
大資料的Hdfs與MapReduce介紹
簡介:本著對大資料的理解,HDFS是側重於大資料的資料儲存,MapReduce是側重於計算與任務的分配;
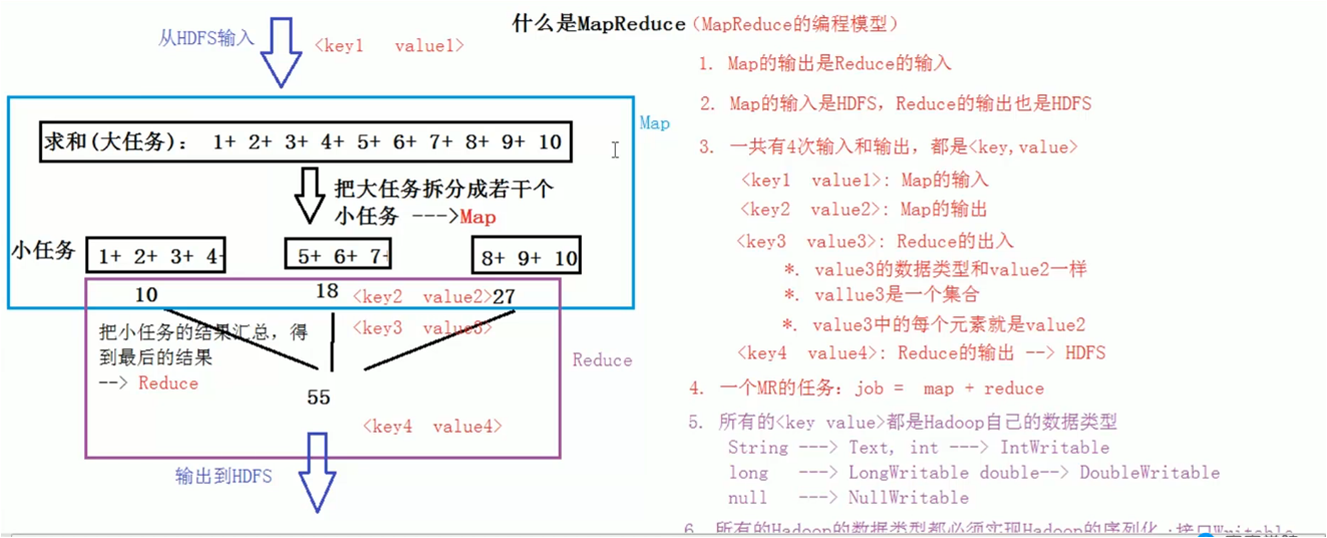
Page Rank (搜尋排名) 什麼是MapReduce ?
1、 資料是從頁面上面獲取,HDFS進行輸入
2、 Map 的輸出是Reduce的輸入;
3、 Map的輸入是HDFS, Reduce的輸出也是 HDFS;
4、 一共是4次輸入輸出,都是key,value的形式;
5、 一個MR任務是job=map+Reduce;
6、 所有的key,value資料型別都是Hadoop自己的資料型別;
7、 String------text; int-----IntWritable ; long -----longWritable null------nulllWritable;….
8、 所有的Hadoop型別都必須實現Hadoop序列化,即實現Writable介面;
9、 如果一個類實現了Writable介面,他的物件就可以作為MR的輸入與輸出;
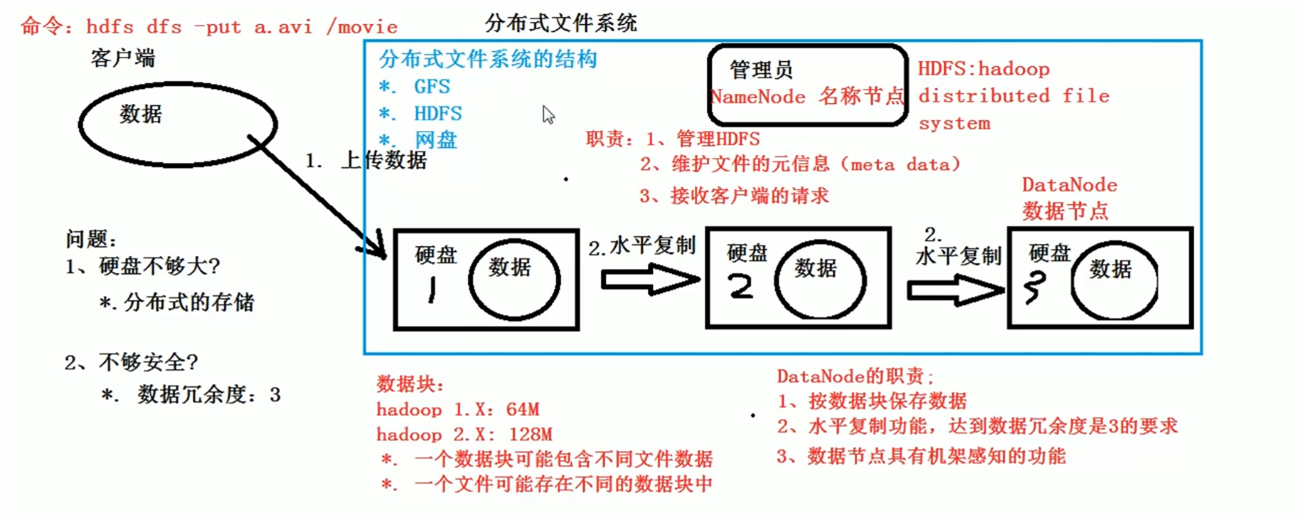
HDFS
MapReduce
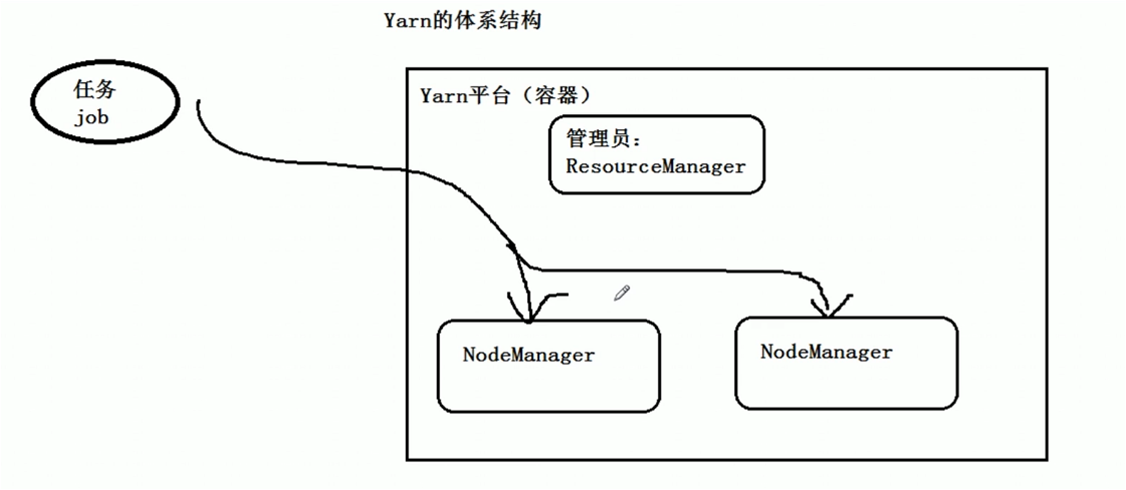
Yarn介紹:
啟動HDFS與yarn;
1、startdfs.sh stop dfs.sh start yarn.sh stop yarn.sh
2、總的就是start –all.sh stop –all.sh
Yarn也是有主節點與真正執行的節點 resourceManager 與 nodeManager
安裝成功以後可以看以下程序 jps 是Java的命令,which jps就可以看到位置;
可以檢視日誌
MapReduce 有預設的排序
1、字串按照字典
2、數字按照 升序
備註:
- 什麼是hdfs?
hdfs是一種分散式系統,其組成是namenode節點和datanode節點。顧名思義,namenode是“名位元組點”,儲存的是這部分儲存區域的相關資訊,並管理datanode節點;而datanode儲存的就是資料。一個namenode對應一個或多個datanode節點,每一個datanode執行在一臺機器上,所以這些datanode組合到一起將形成一個叢集(cluster),實現真正的分散式儲存檔案。需要注意的是namenode和datanode可能執行在同一臺機器上。
除此之外,hdfs特別的地方是,加強了儲存檔案的安全性和完整性。namenode存在副本節點(standby node),當主節點出現問題,比如所執行的機器出現宕機,將由standby節點來取代並獲得datanode的管理許可權;而且每一段資料將備份在幾個不同的datanode上面(根據叢集的datanode數量來決定備份個數)。因此,對應的將會有一個儲存對映表,來記錄每一段資料分別儲存在哪些節點中,便於namenode進行管理和查詢。
- 什麼是yarn
yarn是一個資源管理工具,用來分配資源。它的命名也是極為有趣,YARN(Yet Another Resource Negotiator,另一種資源協調者)。
它包含幾個部分 ,ResourceManager,NodeManager,ApplicationMaster以及Container組成,基本思想是將JobTracker中的資源管理和作業排程進行分離,分別交給ResourceManager,ApplicationMaster進行管理,ApplicationMaster 承擔了以前的 TaskTracker 的一些角色,ResourceManager 承擔了 JobTracker 的角色。
二.啟動方法
以下預設已經成功安裝並配置完成hadoop,如未安裝配可參考如下網址:http://www.imooc.com/learn/391
- namenode的啟動方法
這裡將namenode和datanode的啟動從dfs的啟動分離出來,為了降低錯誤成本,全域性啟動hdfs的話可能會出現問題。
注意:第一次啟動hdfs,需要進行格式化,命令可以找度娘,下面介紹正常的開啟命令。(以下所有命令均在/sbin目錄下進行)
啟動namenode
hadoop-daemon.shstart namenode
· 1
驗證是否啟動,可以通過java的程序命令jps來檢測,如果檢測到namenode程序則說明啟動成功,否則,需要重新輸入命令。下同。
啟動datanode
hadoop-daemon.shstart datanode
· 1
啟動yarn
由於yarn的結構特性,此處推薦將yarn的所有功能一起啟動。
啟動方式如下:
start-yarn.sh
· 1
同樣通過jps命令進行檢測,能夠檢測到ResourceManager和NodeManager程序。
三.檢視啟動資訊
如果通過以上步驟能夠成功啟動hdfs和yarn,那麼就可以到網頁中檢視儲存檔案的資訊和資源管理的資訊。檢視的方法如下:
1. 檢視yarn
管理yarn的埠為50700,即可以在網址部分輸入
yarn001:50700
· 1
注意,交換地址名稱與hadoop的配置檔案中所配置的保持一致,我的交換地址名稱為yarn001。下同。
1. 檢視hdfs
管理hdfs系統的段口號為8088,即可以在網址部分輸入
yarn001:8088