
python K-Means聚類演算法的實現
阿新 • • 發佈:2019-01-10
K-Means 簡介
聚類演算法有很多種(幾十種),K-Means是聚類演算法中的最常用的一種,演算法最大的特點是簡單,好理解,運算速度快,但是一定要在聚類前需要手工指定要分成幾類。
具體實現步驟如下:
給定n個訓練樣本{x1,x2,x3,…,xn}
kmeans演算法過程描述如下所示:
1.建立k個點作為起始質心點,c1,c2,…,ck
2.重複以下過程直到收斂
遍歷所有樣本xi,根據距離確定每一個樣本的類別。
確定類別後,計算每一個樣本到各自質心的距離,然後求和。和用來和前一次計算出來的距離和比較,已確定是否收斂。
對每一個類,計算所有樣本的均值並將其作為新的質心(對於點而言,就是所有x座標的平均值作為質心的x座標,所有y座標的平均值作為y座標的均值)
根據以上步驟,實現的具體效果如下:
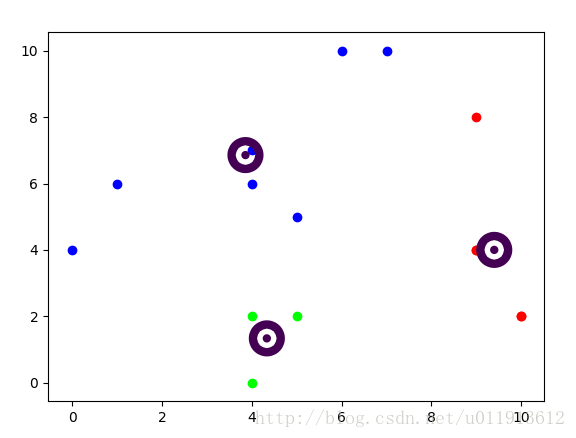
完整程式碼如下:
from matplotlib import pyplot
import numpy as np
#隨機生成K個質心
def randomCenter(pointers,k):
indexs = np.random.random_integers(0,len(pointers)-1,k)
centers = []
for index in indexs:
centers.append(pointers[index])
return centers
#繪製最終的結果
def drawPointersAndCenters(pointers,centers) loadData裝載的資料是通過randonGenerate15Pointer()方法隨機生成的15個點。