
Kafka安裝與簡介
今天來講一下Kafka,它是一個訊息佇列,應用場景比較廣泛。剛開始學習一門東西,咱們先不管它是幹什麼的,先跑起來才是正經,所以本文主要講兩點:
- 安裝搭建Kafka
- 簡單介紹下Kafka的原理和應用
1. 安裝Kafka
1.1 下載解壓
wget http://apache.fayea.com/kafka/0.10.1.0/kafka_2.11-0.10.1.0.tgz
tar -xvf kafka_2.11-0.10.1.0.tgz
cd kafka_2.11-0.10.1.01.2 安裝Zookeeper
Kafka需要Zookeeper的監控,所以先要安裝Zookeeper,如何安裝請傳送至:
1.3 配置kafka broker叢集
我們的宗旨是面向實戰,所以拒絕安裝本地版本Kafka,來看一下Kafka叢集的配置,也很簡單
首先把Kafka解壓後的目錄複製到叢集的各臺伺服器
然後修改各個伺服器的配置檔案:進入Kafka的config目錄,修改server.properties
# brokerid就是指各臺伺服器對應的id,所以各臺伺服器值不同
broker.id=0
# 埠號,無需改變
port=9092
# 當前伺服器的IP,各臺伺服器值不同
host.name=192.168 1.4 啟動Kafka
在每臺伺服器上進入Kafka目錄,分別執行以下命令:
bin/kafka-server-start.sh config/server.properties &1.5 Kafka常用命令
1、新建一個主題
bin/kafka-topics.sh --create --zookeeper hxf:2181 test有兩個複製因子和兩個分割槽
2、檢視新建的主題
bin/kafka-topics.sh --describe --zookeeper hxf:2181,cfg:2181,jqs:2181,jxf:2181,sxtb:2181 --topic test
其中第一行是所有分割槽的資訊,下面的每一行對應一個分割槽
Leader:負責某個分割槽所有讀寫操作的節點
Replicas:複製因子節點
Isr:存活節點
3、檢視Kafka所有的主題
bin/kafka-topics.sh --list --zookeeper hxf:2181,cfg:2181,jqs:2181,jxf:2181,sxtb:2181
4、在終端傳送訊息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
5、在終端接收(消費)訊息
bin/kafka-console-consumer.sh --zookeeper hxf:2181,cfg:2181,jqs:2181,jxf:2181,sxtb:2181 --bootstrap-server localhost:9092 --topic test --from-beginning
2. Kafka簡介
講完實戰讓我們稍微瞭解一下Kafka的一些基本入門知識
2.1 基本術語
訊息
先不管其他的,我們使用Kafka這個訊息系統肯定是先關注訊息這個概念,在Kafka中,每一個訊息由鍵、值和一個時間戳組成
主題和日誌
然後研究一下Kafka提供的核心概念——主題
Kafka叢集儲存同一類別的訊息流稱為主題
主題會有多個訂閱者(0個1個或多個),當主題釋出訊息時,會向訂閱者推送記錄
針對每一個主題,Kafka叢集維護了一個像下面這樣的分割槽日誌:
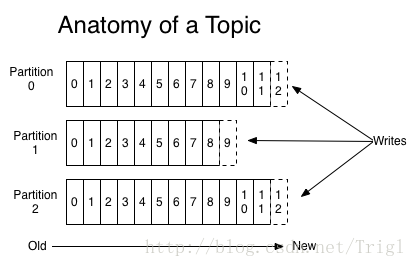
這些分割槽位於不同的伺服器上,每一個分割槽可以看做是一個結構化的提交日誌,每寫入一條記錄都會記錄到其中一個分割槽並且分配一個唯一地標識其位置的數字稱為偏移量offset
Kafka叢集會將釋出的訊息儲存一段時間,不管是否被消費。例如,如果設定儲存天數為2天,那麼從訊息釋出起的兩天之內,該訊息一直可以被消費,但是超過兩天後就會被丟棄以節省空間。其次,Kafka的資料持久化效能很好,所以長時間儲存資料不是問題
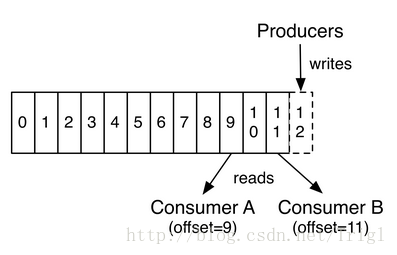
如下圖所示,生產者每釋出一條訊息就會向分割槽log寫入一條記錄的offset,而消費者就是通過offset來讀取對應的訊息的,一般來說每讀取一條訊息,消費者對應要讀取的offset就加1,例如最後一條讀到offset=12,那麼下條offset就為13.由於消費者通過offset來讀取訊息,所以可以重複讀取已經讀過的記錄,或者跳過某些記錄不讀
Kafka中採用分割槽的設計有幾個目的。一是可以處理更多的訊息,不受單臺伺服器的限制。Topic擁有多個分割槽意味著它可以不受限的處理更多的資料。第二,分割槽可以作為並行處理的單元,稍後會談到這一點
分散式
Log的分割槽被分佈到叢集中的多個伺服器上。每個伺服器處理它分到的分割槽。 根據配置每個分割槽還可以複製到其它伺服器作為備份容錯
每個分割槽有一個leader,零或多個follower。Leader處理此分割槽的所有的讀寫請求,而follower被動的複製資料。如果leader宕機,其它的一個follower會被推舉為新的leader。 一臺伺服器可能同時是一個分割槽的leader,另一個分割槽的follower。 這樣可以平衡負載,避免所有的請求都只讓一臺或者某幾臺伺服器處理
生產者
生產者往某個Topic上釋出訊息。生產者還可以選擇將訊息分配到Topic的哪個節點上。最簡單的方式是輪詢分配到各個分割槽以平衡負載,也可以根據某種演算法依照權重選擇分割槽
消費者
Kafka有一個消費者組的概念,生產者把訊息發到的是消費者組,在消費者組裡面可以有很多個消費者例項,如下圖所示:
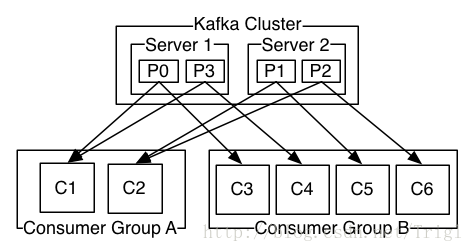
Kafka叢集有兩臺伺服器,四個分割槽,此外有兩個消費者組A和B,消費者組A具有2個消費者例項C1-2,消費者B具有4個消費者例項C3-6
那麼Kafka傳送訊息的過程是怎樣的呢?
例如此時我們建立了一個主題test,有兩個分割槽,分別是Server1的P0和Server2的P1,假設此時我們通過test釋出了一條訊息,那麼這條訊息是發到P0還是P1呢,或者是都發呢?答案是隻會發到P0或P1其中之一,也就是訊息只會發給其中的一個分割槽
分割槽接收到訊息後會記錄在分割槽日誌中,記錄的方式我們講過了,就是通過offset,正因為有這個偏移量的存在,所以一個分割槽內的訊息是有先後順序的,即offset大的訊息比offset小的訊息後到。但是注意,由於訊息隨機發往主題的任意一個分割槽,因此雖然同一個分割槽的訊息有先後順序,但是不同分割槽之間的訊息就沒有先後順序了,那麼如果我們要求消費者順序消費主題發的訊息那該怎麼辦呢,此時只要在建立主題的時候只提供一個分割槽即可
講完了主題發訊息,接下來就該消費者消費訊息了,假設上面test的訊息發給了分割槽P0,此時從圖中可以看到,有兩個消費者組,那麼P0將會把訊息發到哪個消費者組呢?從圖中可以看到,P0把訊息既發給了消費者組A也發給了B,但是A中訊息僅被C1消費,B中訊息僅被C3消費。這就是我們要講的,主題發出的訊息會發往所有的消費者組,而每一個消費者組下面可以有很多消費者例項,這條訊息只會被他們中的一個消費掉
2.2 核心API
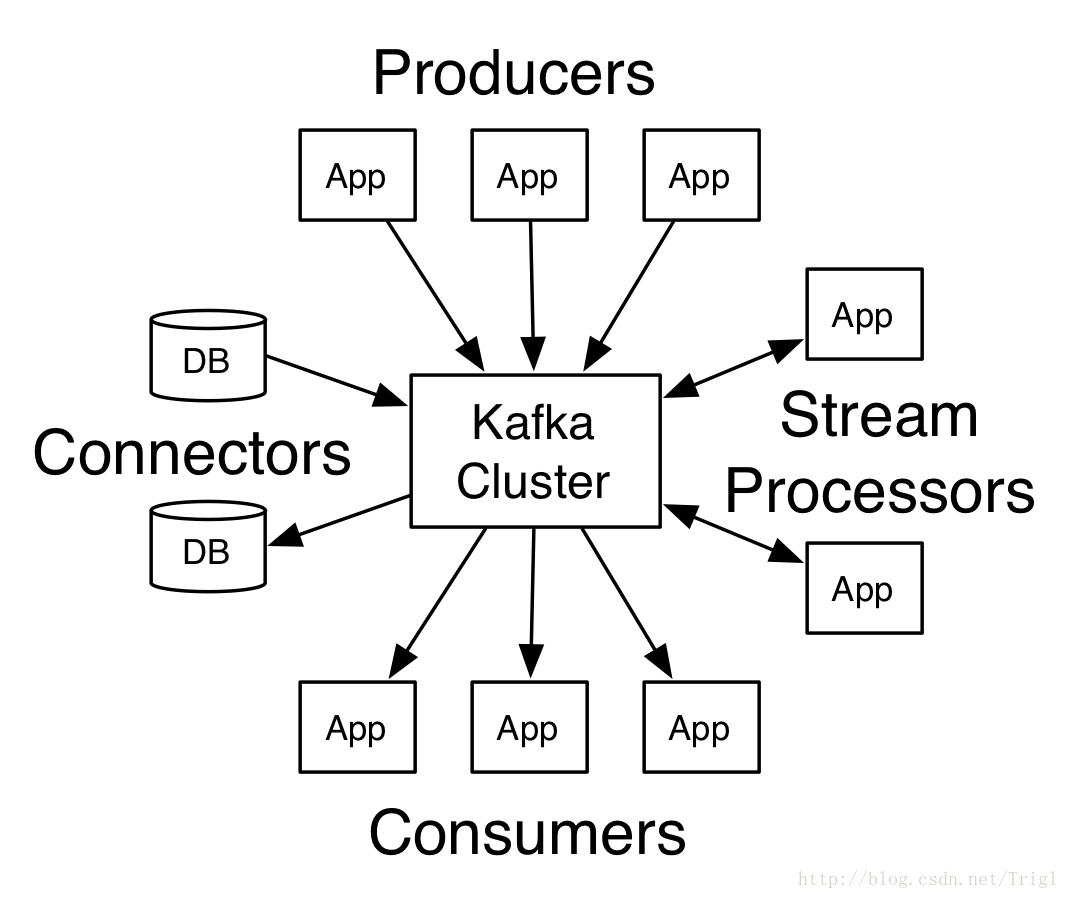
Kafka具有4個核心API:
- Producer API:用於向Kafka主題傳送訊息。
- Consumer API:用於從訂閱主題接收訊息並且處理這些訊息。
- Streams API:作為一個流處理器,用於從一個或者多個主題中消費訊息流然後為其他主題生產訊息流,高效地將輸入流轉換為輸出流。
- Connector API:用於構建和執行將Kafka主題和已有應用或者資料系統連線起來的可複用的生產者或消費者。例如一個主題到一個關係型資料庫的連線能夠捕獲表的任意變化。
2.3 Kafka的應用場景
Kafka用作訊息系統
Kafka流的概念與傳統企業訊息系統有什麼異同?
傳統訊息系統有兩個模型:佇列和釋出-訂閱系統。在佇列模式中,每條伺服器的訊息會被消費者池中的一個所讀取;而釋出-訂閱系統中訊息會廣播給所有的消費者。這兩種模式各有優劣。佇列模式的優勢是可以將訊息資料讓多個消費者處理以實現程式的可擴充套件,然而這就導致其沒有多個訂閱者,只能用於一個程序。釋出-訂閱模式的好處在於資料可以被多個程序消費使用,但是卻無法使單一程式擴充套件效能
Kafka中消費者組的概念同時涵蓋了這兩方面。對應於佇列的概念,Kafka中每個消費者組中有多個消費者例項可以接收訊息;對應於釋出-訂閱模式,Kafka中可以指定多個消費者組來訂閱訊息
相對傳統訊息系統,Kafka可以提供更強的順序保證
Kafka用作儲存系統
任何釋出訊息與消費訊息解耦的訊息佇列其實都可以看做是用來存放釋出的訊息的儲存系統,而Kafka是一個非常高效的儲存系統
寫入Kafka的資料會被存入磁碟並且複製到叢集中以容錯。Kafka允許生產者等待資料完全複製並且確保持久化到磁碟的確認應答
Kafka使用的磁碟結構擴容效能很好——不管伺服器上有50KB還是50TB,Kafka的表現都是一樣的
由於能夠精緻的儲存並且供客戶端程式進行讀操作,你可以把Kafka看做是一個用於高效能、低延遲的儲存提交日誌、複製及傳播的分散式檔案系統
Kafka的流處理
僅僅讀、寫、儲存流資料是不夠的,Kafka的目的是實現實時流處理。
在Kafka中一個流處理器的處理流程是首先持續性的從輸入主題中獲取資料流,然後對其進行一些處理,再持續性地向輸出主題中生產資料流。例如一個銷售商應用,接收銷售和發貨量的輸入流,輸出新訂單和調整後價格的輸出流
可以直接使用producer和consumer API進行簡單的處理。對於複雜的轉換,Kafka提供了更強大的Streams API。可構建聚合計算或連線流到一起的複雜應用程式
流處理有助於解決這類應用面臨的硬性問題:處理無序資料、程式碼更改的再處理、執行狀態計算等
Streams API所依託的都是Kafka的核心內容:使用producer和consumer API作為輸入,使用Kafka作為狀態儲存,在流處理例項上使用相同的組機制來實現容錯
Refer