
Storm學習筆記(1) - 初識實時流處理Storm
文章目錄
Strom是什麼
為什麼使用storm
Apache Storm是一個免費的開源分散式實時計算系統。Storm使得可靠地處理無邊界的資料流變得非常容易,就像Hadoop處理批處理一樣,能夠實時處理資料流。Storm很簡單,可以和任何程式語言一起使用,使用起來很有趣!
Storm有很多用例:實時分析、線上機器學習、連續計算、分散式RPC、ETL等等。Storm非常快**:一個基準測試記錄了它在每個節點每秒處理超過一百萬元組**。它是可伸縮的,容錯的,保證您的資料都被處理,並且易於設定和操作。
Storm集成了您已經使用的排隊和資料庫技術。Storm拓撲使用資料流,並以任意複雜的方式處理這些流,當你需要的時候,可以在計算的每個階段之間重新劃分流。
小結:Strom能實現高頻資料和大規模資料的實時處理
Storm發展歷史
從Twitter說起
Storm產生於BackType(被Twitter收購)公司
storm開發時的需求:大資料的實時處理
自己來實現實時系統,要考慮的因素:
- 健壯性
- 擴充套件性/分散式
- 如何使得資料不丟失,不重複
- 高效能、低延時
Storm的成長
Storm開源
2011.9
Apache
底層原始碼Clojure 開發語言Java
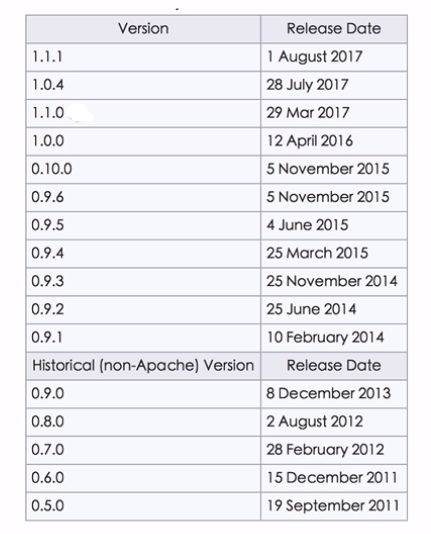
Storm技術網站
- 官網: storm.apache.org
- GitHub: github.com/apache/storm
- wiki: https://en.wikipedia.org/wiki/Storm (event_processor)
Storm和Hadoop的區別
Storm vs Hadoop
- 資料來源/處理領域
Hadoop批處理/mapreduce;Storm實時處理/Spout Bolt - 處理過程
- Hadoop: Map Reduce
- Storm: Spout Bolt
- 程序是否結束
Hadoop程序結束後會停掉;Storm程序是實時流7*24小時執行 - 處理速度
Storm實時必須快速處理資料;Hadoop離線速度無所謂 - 使用場景
實時和離線
Storm和Spark Streaming的區別

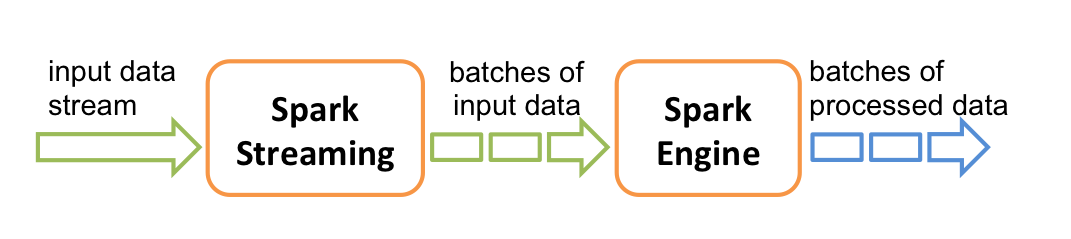
上半部分是從大方向來說sparkstreaming;下半部分是從內部分析saprkstreaming;它是把資料分為一個個batch交給engine來處理的;嚴格來講它並不是實時流計算。
storm延遲是毫秒級別;雖然sparkstreaming目前也是可以設定秒級別,但是它需要設定微批的時間;到達時間週期後才會執行。
spark是一棧式的計算框架,解決各種環境各種需求,比如資料離線處理和實時處理,結果出來後又進行圖計算和機器學習,spark可以在資料不落地的情況下進行下一步。而storm處理過的資料需要先落地再加入其他機器學習和圖計算的框架工具。
實時要求很高,並且資料出來後沒有其他操作,建議使用storm;實時要求不高可以忍受一兩秒,或者資料出來後有其他操作如機器學習和圖計,建議使用spark。
Storm的優勢
程式設計模型:簡易的介面,可以讓java工程師快速上手
擴充套件性:分散式處理可橫向擴充套件
可靠性:資料來源發出的每一條資料都會進行處理,不會丟失;節點掛掉可以自動進行切換
容錯性:硬體問題導致機器宕掉對應用程式沒影響
Storm當前現狀與發展趨勢
發展趨勢
1) 社群的發展、活躍度
2) 企業的需求
3) 大資料相關的大會, Storm主題的數量上升
4) 網際網路 JStorm(阿里)