
SparkStreaming實戰-使用者行為日誌
阿新 • • 發佈:2019-01-10
文章目錄
需求說明
- 今天到現在為止實戰課程的訪問量
- 今天到現在為止從搜尋引擎引流過來的實戰課程訪問量
使用者行為日誌介紹
使用者行為日誌:使用者每次訪問網站時所有的行為資料(訪問、瀏覽、搜尋、點選…)
使用者行為軌跡、流量日誌
典型的日誌來源於Nginx和Ajax
日誌資料內容:
1)訪問的系統屬性: 作業系統、瀏覽器等等
2)訪問特徵:點選的url、從哪個url跳轉過來的(referer)、頁面上的停留時間等
3)訪問資訊:session_id、訪問ip(訪問城市)等
Python日誌產生器伺服器測試並將日誌寫入到檔案中
generate_log.py
#coding=UTF-8
import random
import time
url_paths = [
"class/112.html",
"class/128.html",
"class/145.html",
"class/146.html",
"class/131.html" 生成的日誌
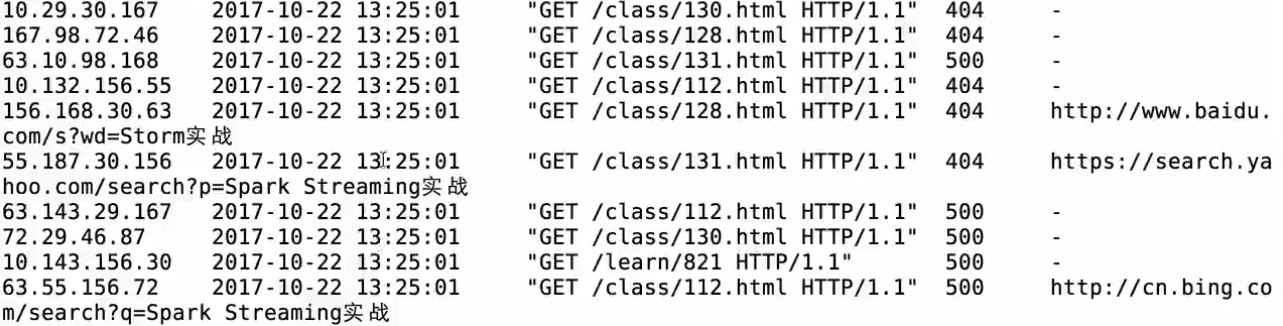
定時執行日誌生成器:
linux crontab
網站:http://tool.lu/crontab
每一分鐘執行一次的crontab表示式: */1 * * * *
log_generator.sh
python ****/generate_log.py
crontab -e
*/1 * * * * /home/hadoop/data/project/log_generator.sh
打通Flume&Kafka&Spark Streaming線路
使用Flume實時收集日誌資訊
對接python日誌產生器輸出的日誌到Flume
streaming_project.conf
選型:access.log ==> 控制檯輸出
exec
memory
logger
exec-memory-logger.sources = exec-source
exec-memory-logger.sinks = logger-sink
exec-memory-logger.channels = memory-channel
exec-memory-logger.sources.exec-source.type = exec
exec-memory-logger.sources.exec-source.command = tail -F /home/hadoop/data/project/logs/access.log
exec-memory-logger.sources.exec-source.shell = /bin/sh -c
exec-memory-logger.channels.memory-channel.type = memory
exec-memory-logger.sinks.logger-sink.type = logger
exec-memory-logger.sources.exec-source.channels = memory-channel
exec-memory-logger.sinks.logger-sink.channel = memory-channel
啟動flume測試
flume-ng agent \
--name exec-memory-logger \
--conf $FLUME_HOME/conf \
--conf-file /home/hadoop/data/project/streaming_project.conf \
-Dflume.root.logger=INFO,console
Flume對接kafka
日誌==>Flume==>Kafka
啟動zk:./zkServer.sh start
啟動Kafka Server:
kafka-server-start.sh -daemon /home/hadoop/app/kafka_2.11-0.9.0.0/config/server.properties
修改Flume配置檔案使得flume sink資料到Kafka
streaming_project2.conf
exec-memory-kafka.sources = exec-source
exec-memory-kafka.sinks = kafka-sink
exec-memory-kafka.channels = memory-channel
exec-memory-kafka.sources.exec-source.type = exec
exec-memory-kafka.sources.exec-source.command = tail -F /home/hadoop/data/project/logs/access.log
exec-memory-kafka.sources.exec-source.shell = /bin/sh -c
exec-memory-kafka.channels.memory-channel.type = memory
exec-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
exec-memory-kafka.sinks.kafka-sink.brokerList = hadoop000:9092
exec-memory-kafka.sinks.kafka-sink.topic = streamingtopic
exec-memory-kafka.sinks.kafka-sink.batchSize = 5
exec-memory-kafka.sinks.kafka-sink.requiredAcks = 1
exec-memory-kafka.sources.exec-source.channels = memory-channel
exec-memory-kafka.sinks.kafka-sink.channel = memory-channel
啟動flume
flume-ng agent \
--name exec-memory-kafka \
--conf $FLUME_HOME/conf \
--conf-file /home/hadoop/data/project/streaming_project2.conf \
-Dflume.root.logger=INFO,console
啟動kafka消費者檢視日誌是否正常
kafka-console-consumer.sh --zookeeper hadoop000:2181 --topic streamingtopic
Spark Streaming對接Kafka的資料進行消費
需求開發分析
功能1:今天到現在為止 實戰課程 的訪問量
yyyyMMdd courseid
使用資料庫來進行儲存我們的統計結果
Spark Streaming把統計結果寫入到資料庫裡面
視覺化前端根據:yyyyMMdd courseid 把資料庫裡面的統計結果展示出來
選擇什麼資料庫作為統計結果的儲存呢?
RDBMS: MySQL、Oracle...
day course_id click_count
20171111 1 10
20171111 2 10
下一個批次資料進來以後:(本操作比較麻煩)
20171111 (day)+ 1 (course_id ) ==> click_count + 下一個批次的統計結果 ==> 寫入到資料庫中
NoSQL: HBase、Redis....
HBase: 一個API就能搞定,非常方便(推薦)
20171111 + 1 ==> click_count + 下一個批次的統計結果
本次課程為什麼要選擇HBase的一個原因所在
前提需要啟動:
HDFS
Zookeeper
HBase
HBase表設計
建立表
create 'imooc_course_clickcount', 'info'
Rowkey設計
day_courseid
思考:如何使用Scala來操作HBase
功能二:功能一+從搜尋引擎引流過來的
HBase表設計
create 'imooc_course_search_clickcount','info'
rowkey設計:也是根據我們的業務需求來的
20171111 +search+ 1
在Spark應用程式接收到資料並完成相關需求
相關maven依賴已經在前面的文章中給出過
時間工具類:
package com.imooc.spark.project.utils
import java.util.Date
import org.apache.commons.lang3.time.FastDateFormat
/**
* 日期時間工具類
*/
object DateUtils {
val YYYYMMDDHHMMSS_FORMAT = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss")
val TARGE_FORMAT = FastDateFormat.getInstance("yyyyMMddHHmmss")
def getTime(time: String) = {
YYYYMMDDHHMMSS_FORMAT.parse(time).getTime
}
def parseToMinute(time :String) = {
TARGE_FORMAT.format(new Date(getTime(time)))
}
def main(args: Array[String]): Unit = {
println(parseToMinute("2017-10-22 14:46:01"))
}
}
java編寫的hbase工具類
package com.imooc.spark.project.utils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
/**
* HBase操作工具類:Java工具類建議採用單例模式封裝
*/
public class HBaseUtils {
HBaseAdmin admin = null;
Configuration configuration = null;
/**
* 私有改造方法
*/
private HBaseUtils(){
configuration = new Configuration();
configuration.set("hbase.zookeeper.quorum", "hadoop000:2181");
configuration.set("hbase.rootdir", "hdfs://hadoop000:8020/hbase");
try {
admin = new HBaseAdmin(configuration);
} catch (IOException e) {
e.printStackTrace();
}
}
private static HBaseUtils instance = null;
public static synchronized HBaseUtils getInstance() {
if(null == instance) {
instance = new HBaseUtils();
}
return instance;
}
/**
* 根據表名獲取到HTable例項
*/
public HTable getTable(String tableName) {
HTable table = null;
try {
table = new HTable(configuration, tableName);
} catch (IOException e) {
e.printStackTrace();
}
return table;
}
/**
* 新增一條記錄到HBase表
* @param tableName HBase表名
* @param rowkey HBase表的rowkey
* @param cf HBase表的columnfamily
* @param column HBase表的列
* @param value 寫入HBase表的值
*/
public void put(String tableName, String rowkey, String cf, String column, String value) {
HTable table = getTable(tableName);
Put put = new Put(Bytes.toBytes(rowkey));
put.add(Bytes.toBytes(cf), Bytes.toBytes(column), Bytes.toBytes(value));
try {
table.put(put);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
//HTable table = HBaseUtils.getInstance().getTable("imooc_course_clickcount");
//System.out.println(table.getName().getNameAsString());
String tableName = "imooc_course_clickcount" ;
String rowkey = "20171111_88";
String cf = "info" ;
String column = "click_count";
String value = "2";
HBaseUtils.getInstance().put(tableName, rowkey, cf, column, value);
}
}
domain相關實體類
package com.imooc.spark.project.domain
/**
* 清洗後的日誌資訊
* @param ip 日誌訪問的ip地址
* @param time 日誌訪問的時間
* @param courseId 日誌訪問的實戰課程編號
* @param statusCode 日誌訪問的狀態碼
* @param referer 日誌訪問的referer
*/
case class ClickLog(ip:String, time:String, courseId:Int, statusCode:Int, referer:String)
package com.imooc.spark.project.domain
/**
* 實戰課程點選數實體類
* @param day_course 對應的就是HBase中的rowkey,20171111_1
* @param click_count 對應的20171111_1的訪問總數
*/
case class CourseClickCount(day_course:String, click_count:Long)
package com.imooc.spark.project.domain
/**
* 從搜尋引擎過來的實戰課程點選數實體類
* @param day_search_course
* @param click_count
*/
case class CourseSearchClickCount(day_search_course:String, click_count:Long)
兩需求的dao類
package com.imooc.spark.project.dao
import com.imooc.spark.project.domain.CourseClickCount
import com.imooc.spark.project.utils.HBaseUtils
import org.apache.hadoop.hbase.client.Get
import org.apache.hadoop.hbase.util.Bytes
import scala.collection.mutable.ListBuffer
/**
* 實戰課程點選數-資料訪問層
*/
object CourseClickCountDAO {
val tableName = "imooc_course_clickcount"
val cf = "info"
val qualifer = "click_count"
/**
* 儲存資料到HBase
* @param list CourseClickCount集合
*/
def save(list: ListBuffer[CourseClickCount]): Unit = {
val table = HBaseUtils.getInstance().getTable(tableName)
for(ele <- list) {
table.incrementColumnValue(Bytes.toBytes(ele.day_course),
Bytes.toBytes(cf),
Bytes.toBytes(qualifer),
ele.click_count)
}
}
/**
* 根據rowkey查詢值
*/
def count(day_course: String):Long = {
val table = HBaseUtils.getInstance().getTable(tableName)
val get = new Get(Bytes.toBytes(day_course))
val value = table.get(get).getValue(cf.getBytes, qualifer.getBytes)
if(value == null) {
0L
}else{
Bytes.toLong(value)
}
}
def main(args: Array[String]): Unit = {
val list = new ListBuffer[CourseClickCount]
list.append(CourseClickCount("20171111_8",8))
list.append(CourseClickCount("20171111_9",9))
list.append(CourseClickCount("20171111_1",100))
save(list)
println(count("20171111_8") + " : " + count("20171111_9")+ " : " + count("20171111_1"))
}
}
package com.imooc.spark.project.dao
import com.imooc.spark.project.domain.{CourseClickCount, CourseSearchClickCount}
import com.imooc.spark.project.utils.HBaseUtils
import org.apache.hadoop.hbase.client.Get
import org.apache.hadoop.hbase.util.Bytes
import scala.collection.mutable.ListBuffer
/**
* 從搜尋引擎過來的實戰課程點選數-資料訪問層
*/
object CourseSearchClickCountDAO {
val tableName = "imooc_course_search_clickcount"
val cf = "info"
val qualifer = "click_count"
/**
* 儲存資料到HBase
*
* @param list CourseSearchClickCount集合
*/
def save(list: ListBuffer[CourseSearchClickCount]): Unit = {
val table = HBaseUtils.getInstance().getTable(tableName)
for(ele <- list) {
table.incrementColumnValue(Bytes.toBytes(ele.day_search_course),
Bytes.toBytes(cf),
Bytes.toBytes(qualifer),
ele.click_count)
}
}
/**
* 根據rowkey查詢值
*/
def count(day_search_course: String):Long = {
val table = HBaseUtils.getInstance().getTable(tableName)
val get = new Get(Bytes.toBytes(day_search_course))
val value = table.get(get).getValue(cf.getBytes, qualifer.getBytes)
if(value == null) {
0L
}else{
Bytes.toLong(value)
}
}
def main(args: Array[String]): Unit = {
val list = new ListBuffer[CourseSearchClickCount]
list.append(CourseSearchClickCount("20171111_www.baidu.com_8",8))
list.append(CourseSearchClickCount("20171111_cn.bing.com_9",9))
save(list)
println(count("20171111_www.baidu.com_8") + " : " + count("20171111_cn.bing.com_9"))
}
}
使用Spark Streaming處理Kafka過來的資料
package com.imooc.spark.project.spark
import com.imooc.spark.project.dao.{CourseClickCountDAO, CourseSearchClickCountDAO}
import com.imooc.spark.project.domain.{ClickLog, CourseClickCount, CourseSearchClickCount}
import com.imooc.spark.project.utils.DateUtils
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable.ListBuffer
/**
* 使用Spark Streaming處理Kafka過來的資料
*/
object ImoocStatStreamingApp {
def main(args: Array[String]): Unit = {
if (args.length != 4) {
println("Usage: ImoocStatStreamingApp <zkQuorum> <group> <topics> <numThreads>")
System.exit(1)
}
val Array(zkQuorum, groupId, topics, numThreads) = args
val sparkConf = new SparkConf().setAppName("ImoocStatStreamingApp") //.setMaster("local[5]")
val ssc = new StreamingContext(sparkConf, Seconds(60))
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
val messages = KafkaUtils.createStream(ssc, zkQuorum, groupId, topicMap)
// 測試步驟一:測試資料接收
//messages.map(_._2).count().print
// 測試步驟二:資料清洗
val logs = messages.map(_._2)
val cleanData = logs.map(line => {
val infos = line.split("\t")
// infos(2) = "GET /class/130.html HTTP/1.1"
// url = /class/130.html
val url = infos(2).split(" ")(1)
var courseId = 0
// 把實戰課程的課程編號拿到了
if (url.startsWith("/class")) {
val courseIdHTML = url.split("/")(2)
courseId = courseIdHTML.substring(0, courseIdHTML