
Sparksql實戰 - 使用者行為日誌
文章目錄
使用者行為日誌概述
使用者行為日誌:使用者每次訪問網站時所有的行為資料(訪問、瀏覽、搜尋、點選…)
使用者行為軌跡、流量日誌
典型的日誌來源於Nginx和Ajax
日誌資料內容:
1)訪問的系統屬性: 作業系統、瀏覽器等等
2)訪問特徵:點選的url、從哪個url跳轉過來的(referer)、頁面上的停留時間等
3)訪問資訊:session_id、訪問ip(訪問城市)等
比如
2013-05-19 13:00:00 http://www.taobao.com/17/?tracker_u=1624169&type=1 B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1 http://hao.360.cn/ 1.196.34.243
資料處理流程
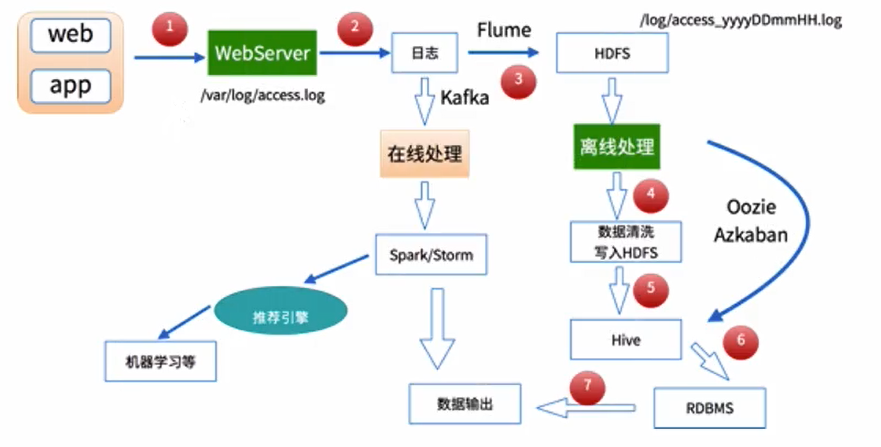
1)資料採集
Flume: web日誌寫入到HDFS
2)資料清洗
髒資料
Spark、Hive、MapReduce 或者是其他的一些分散式計算框架
清洗完之後的資料可以存放在HDFS(Hive/Spark SQL)
3)資料處理
按照我們的需要進行相應業務的統計和分析
Spark、Hive、MapReduce 或者是其他的一些分散式計算框架
4)處理結果入庫
結果可以存放到RDBMS、NoSQL
5)資料的視覺化
通過圖形化展示的方式展現出來:餅圖、柱狀圖、地圖、折線圖
ECharts、HUE、Zeppelin
專案需求
需求一:統計imooc主站最受歡迎的課程/手記的Top N訪問次數
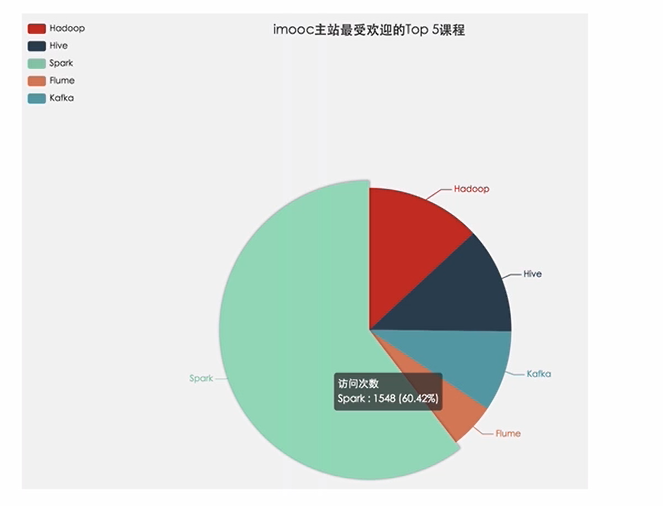
需求二:按地市統計imooc主站最受歡迎的Top N課程
- 根據IP地址提取出城市資訊
- 視窗函式在Spark SQL中的使用
需求三:按流量統計imooc主站最受歡迎的TopN課程
imooc網主站日誌內容構成
百條日誌包下載連結
https://download.csdn.net/download/bingdianone/10800924
183.162.52.7 - - [10/Nov/2016:00:01:02 +0800] "POST /api3/getadv HTTP/1.1" 200 813 "www.imooc.com" "-" cid=0×tamp=1478707261865&uid=2871142&marking=androidbanner&secrect=a6e8e14701ffe9f6063934780d9e2e6d&token=f51e97d1cb1a9caac669ea8acc162b96 "mukewang/5.0.0 (Android 5.1.1; Xiaomi Redmi 3 Build/LMY47V),Network 2G/3G" "-" 10.100.134.244:80 200 0.027 0.027
106.39.41.166 - - [10/Nov/2016:00:01:02 +0800] "POST /course/ajaxmediauser/ HTTP/1.1" 200 54 "www.imooc.com" "http://www.imooc.com/video/8701" mid=8701&time=120.0010000000002&learn_time=16.1 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0" "-" 10.100.136.64:80 200 0.016 0.016
開發相關依賴
<properties>
<maven.compiler.source>1.5</maven.compiler.source>
<maven.compiler.target>1.5</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<spark.version>2.1.0</spark.version>
</properties>
<dependencies>
<!--scala-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<!--
<scope>provided</scope>
-->
</dependency>
<!--SparkSQL-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
<!--
<scope>provided</scope>
-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
<!--
<scope>provided</scope>
-->
</dependency>
<dependency>
<groupId>org.spark-project.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1.spark2</version>
<!--
<scope>provided</scope>
-->
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>com.ggstar</groupId>
<artifactId>ipdatabase</artifactId>
<version>1.0</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.14</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.14</version>
</dependency>
</dependencies>
資料清洗
資料清洗之第一步原始日誌解析
工具類
package com.imooc.log
import java.util.{Date, Locale}
import org.apache.commons.lang3.time.FastDateFormat
/**
* 日期時間解析工具類:
* 注意:SimpleDateFormat是執行緒不安全
*/
object DateUtils {
//輸入檔案日期時間格式
//10/Nov/2016:00:01:02 +0800
val YYYYMMDDHHMM_TIME_FORMAT = FastDateFormat.getInstance("dd/MMM/yyyy:HH:mm:ss Z", Locale.ENGLISH)
//目標日期格式
val TARGET_FORMAT = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss")
/**
* 獲取時間:yyyy-MM-dd HH:mm:ss
*/
def parse(time: String) = {
TARGET_FORMAT.format(new Date(getTime(time)))
}
/**
* 獲取輸入日誌時間:long型別
*
* time: [10/Nov/2016:00:01:02 +0800]
*/
def getTime(time: String) = {
try {
YYYYMMDDHHMM_TIME_FORMAT.parse(time.substring(time.indexOf("[") + 1,
time.lastIndexOf("]"))).getTime
} catch {
case e: Exception => {
0l
}
}
}
def main(args: Array[String]) {
println(parse("[10/Nov/2016:00:01:02 +0800]"))
}
}
package com.imooc.log
import org.apache.spark.sql.SparkSession
/**
* 第一步清洗:抽取出我們所需要的指定列的資料
*/
object SparkStatFormatJob {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("SparkStatFormatJob")
.master("local[2]").getOrCreate()
//讀取源資料
val acccess = spark.sparkContext.textFile("file:///Users/rocky/data/imooc/10000_access.log")
//acccess.take(10).foreach(println)
acccess.map(line => {
val splits = line.split(" ")
val ip = splits(0)
/**
* 原始日誌的第三個和第四個欄位拼接起來就是完整的訪問時間:
* [10/Nov/2016:00:01:02 +0800] ==> yyyy-MM-dd HH:mm:ss
*/
val time = splits(3) + " " + splits(4)
val url = splits(11).replaceAll("\"","")
val traffic = splits(9)
// (ip, DateUtils.parse(time), url, traffic)
DateUtils.parse(time) + "\t" + url + "\t" + traffic + "\t" + ip
}).saveAsTextFile("file:///Users/rocky/data/imooc/output/")
spark.stop()
}
}
清洗之後的樣式
訪問時間、訪問URL、耗費的流量、訪問IP地址資訊
2017-05-11 00:38:01 http://www.imooc.com/article/17891 262 58.32.19.255
資料清洗之二次清洗概述
- 使用Spark SQL解析訪問日誌
- 解析出課程編號、型別
- 根據IP解析出城市資訊
- 使用Spark SQL將訪問時間按天進行分割槽輸出
一般的日誌處理方式,我們是需要進行分割槽的,
按照日誌中的訪問時間進行相應的分割槽,比如:d,h,m5(每5分鐘一個分割槽);資料量越大建議分割槽越多
資料清洗之日誌解析
輸入:訪問時間、訪問URL、耗費的流量、訪問IP地址資訊
輸出:URL、cmsType(video/article)、cmsId(編號)、流量、ip、城市資訊、訪問時間、天
資料清洗之ip地址解析
使用github上已有的開源專案
1)git clone https://github.com/wzhe06/ipdatabase.git
2)進入該專案目錄下,編譯下載的專案:mvn clean package -DskipTests
3)安裝jar包到自己的maven倉庫
mvn install:install-file -Dfile=/Users/rocky/source/ipdatabase/target/ipdatabase-1.0-SNAPSHOT.jar -DgroupId=com.ggstar -DartifactId=ipdatabase -Dversion=1.0 -Dpackaging=jar
記得加入poi包
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.14</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.14</version>
</dependency>
需要加入配置檔案否則報錯
java.io.FileNotFoundException:
file:/Users/rocky/maven_repos/com/ggstar/ipdatabase/1.0/ipdatabase-1.0.jar!/ipRegion.xlsx (No such file or directory)
解決:
將下列包匯入到本地IDEA專案中

測試
package com.imooc.log
import com.ggstar.util.ip.IpHelper
/**
* IP解析工具類
*/
object IpUtils {
def getCity(ip:String) = {
IpHelper.findRegionByIp(ip)
}
def main(args: Array[String]) {
println(getCity("218.75.35.226"))
}
}
相關工具類
package com.imooc.log
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.{LongType, StringType, StructField, StructType}
/**
* 訪問日誌轉換(輸入==>輸出)工具類
*/
object AccessConvertUtil {
//定義的輸出的欄位
val struct = StructType(
Array(
StructField("url",StringType),
StructField("cmsType",StringType),
StructField("cmsId",LongType),
StructField("traffic",LongType),
StructField("ip",StringType),
StructField("city",StringType),
StructField("time",StringType),
StructField("day",StringType)
)
)
/**
* 根據輸入的每一行資訊轉換成輸出的樣式
* @param log 輸入的每一行記錄資訊
*/
def parseLog(log:String) = {
try{
val splits = log.split("\t")
val url = splits(1)
val traffic = splits(2).toLong
val ip = splits(3)
val domain = "http://www.imooc.com/"
val cms = url.substring(url.indexOf(domain) + domain.length)
val cmsTypeId = cms.split("/")
var cmsType = ""
var cmsId = 0l
if(cmsTypeId.length > 1) {
cmsType = cmsTypeId(0)
cmsId = cmsTypeId(1).toLong
}
val city = IpUtils.getCity(ip)//需要加入外部ip解析工具
val time = splits(0)
val day = time.substring(0,10).replaceAll("-","")
//這個row裡面的欄位要和struct中的欄位對應上
Row(url, cmsType, cmsId, traffic, ip, city, time, day)
} catch {
case e:Exception => Row(0)
}
}
}
資料清洗結果以及儲存到目標地址
package com.imooc.log
import org.apache.spark.sql.{SaveMode, SparkSession}
/**
* 使用Spark完成我們的資料清洗操作
*/
object SparkStatCleanJob {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("SparkStatCleanJob")
.config("spark.sql.parquet.compression.codec","gzip")
.master("local[2]").getOrCreate()
//讀取上一步清洗後的資料
val accessRDD = spark.sparkContext.textFile("/Users/rocky/data/imooc/access.log")
//accessRDD.take(10).foreach(println)
//RDD ==> DF
val accessDF = spark.createDataFrame(accessRDD.map(x => AccessConvertUtil.parseLog(x)),
AccessConvertUtil.struct)
// accessDF.printSchema()
// accessDF.show(false)
//按照day進行分割槽進行儲存;coalesce(1)為了減少小檔案;只有一個檔案
accessDF.coalesce(1).write.format("parquet").mode(SaveMode.Overwrite)
.partitionBy("day").save("/Users/rocky/data/imooc/clean2")
spark.stop
}
}
輸出的型別和結果

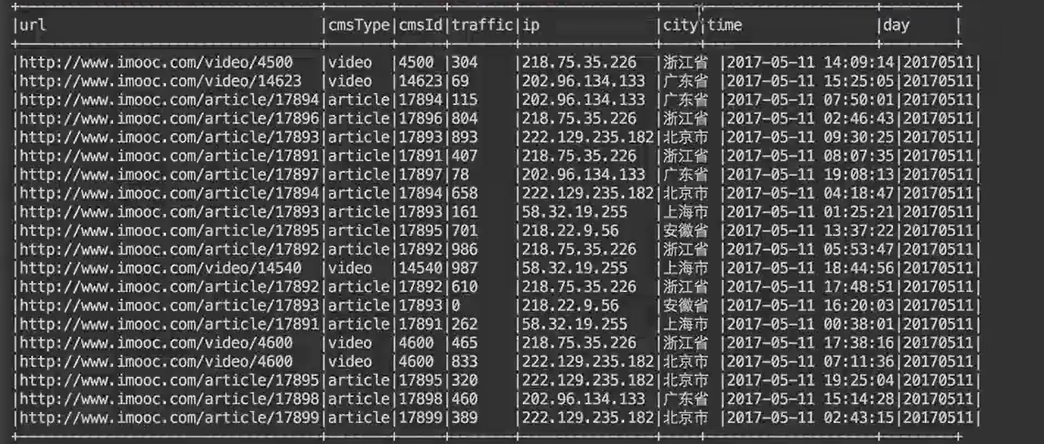
需求統計功能實現
Scala操作MySQL工具類開發
package com.imooc.log
import java.sql.{Connection, PreparedStatement, DriverManager}
/**
* MySQL操作工具類
*/
object MySQLUtils {
/**
* 獲取資料庫連線
*/
def getConnection() = {
DriverManager.getConnection("jdbc:mysql://localhost:3306/imooc_project?user=root&password=root")
}
/**
* 釋放資料庫連線等資源
* @param connection
* @param pstmt
*/
def release(connection: Connection, pstmt: PreparedStatement): Unit = {
try {
if (pstmt != null) {
pstmt.close()
}
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (connection != null) {
connection.close()
}
}
}
def main(args: Array[String]) {
println(getConnection())
}
}
建立相關表
create table day_video_access_topn_stat (
day varchar(8) not null,
cms_id bigint(10) not null,
times bigint(10) not null,
primary key (day, cms_id)
);
create table day_video_city_access_topn_stat (
day varchar(8) not null,
cms_id bigint(10) not null,
city varchar(20) not null,
times bigint(10) not null,
times_rank int not null,
primary key (day, cms_id, city)
);
create table day_video_traffics_topn_stat (
day varchar(8) not null,
cms_id bigint(10) not null,
traffics bigint(20) not null,
primary key (day, cms_id)
);
每天課程訪問次數實體類
package com.imooc.log
/**
* 每天課程訪問次數實體類
*/
case class DayVideoAccessStat(day: String, cmsId: Long, times: Long)
各個維度統計的DAO操作
package com.imooc.log
import java.sql.{PreparedStatement, Connection}
import scala.collection.mutable.ListBuffer
/**
* 各個維度統計的DAO操作
*/
object StatDAO {
/**
* 批量儲存DayVideoAccessStat到資料庫
*/
def insertDayVideoAccessTopN(list: ListBuffer[DayVideoAccessStat]): Unit = {
var connection: Connection = null
var pstmt: PreparedStatement = null
try {
connection = MySQLUtils.getConnection()
connection.setAutoCommit(false) //設定手動提交
val sql = "insert into day_video_access_topn_stat(day,cms_id,times) values (?,?,?) "
pstmt = connection.prepareStatement(sql)
for (ele <- list) {
pstmt.setString(1, ele.day)
pstmt.setLong(2, ele.cmsId)
pstmt.setLong(3, ele.times)
pstmt.
相關推薦
Sparksql實戰 - 使用者行為日誌
文章目錄
使用者行為日誌概述
資料處理流程
專案需求
imooc網主站日誌內容構成
資料清洗
資料清洗之第一步原始日誌解析
資料清洗之二次清洗概述
資料清洗之日誌解析
SparkStreaming實戰-使用者行為日誌
文章目錄
需求說明
使用者行為日誌介紹
Python日誌產生器伺服器測試並將日誌寫入到檔案中
打通Flume&Kafka&Spark Streaming線路
使用Flume實時收集日誌資訊
thinkphp5 行為日誌列表
後臺 操作 str 分享圖片 box blank 函數 使用 http 行為日誌列表
圖上是系統的行為日誌,此處的行為日誌是指後臺的操作行為記錄,不涉及其他模塊,後臺研發過程中需要記錄行為日誌則使用 action_log 函數記錄,清空與刪除日誌此處就不說啦。thinkp
(轉)企業配置sudo命令用戶行為日誌審計
用戶權限管理 配置 服務器 pos gif amp toc cts tro 原文:https://www.cnblogs.com/Csir/p/6403830.html?utm_source=itdadao&utm_medium=referral
第15章 企業配置
springboot filter and interceptor實戰之mdc日誌列印
1.1 mdc日誌列印全域性控制
1.1.1 logback配置
<property name="log.pattern" value="%d{yyyy-MM-dd'T'HH:mm:ss.SSSXXX}%level [%thread] [
Elastic Stack實戰學習教程~日誌資料的收集、分析與視覺化
Elastic Stack介紹
近幾年,網際網路生成資料的速度不斷遞增,為了便於使用者能夠更快更精準的找到想要的內容,站內搜尋或應用內搜尋成了不可缺少了的功能之一。同時,企業積累的資料也再不斷遞增,對海量資料分析處理、視覺化的需求也越來越高。
在這個領域裡,開源專案ElasticSearch贏得了市場的關
Elastic Stack實戰學習教程~日誌數據的收集、分析與可視化
cse 靈活 service 配置 很多 技術 常見 假設 搜索服務 Elastic Stack介紹
近幾年,互聯網生成數據的速度不斷遞增,為了便於用戶能夠更快更精準的找到想要的內容,站內搜索或應用內搜索成了不可缺少了的功能之一。同時,企業積累的數據也再不斷遞增,對海量數據
ElasticSearch實戰:Linux日誌對接Kibana
本文由雲+社群發表
ElasticSearch是一個基於Lucene的搜尋伺服器。它提供了一個分散式多使用者能力的全文搜尋引擎,基於RESTFul web介面。ElasticSearch是用Java開發的,並作為Apache許可條款下的開放原始碼釋出,是當前流行的企業級搜尋引擎。ElasticSearch
使用者行為日誌概述
寫在前面
什麼是使用者行為日誌呢?其實也叫做使用者行為軌跡,流量日誌等。簡單來說,就是使用者每次訪問網站產生的行為資料(訪問,瀏覽,搜尋,點選等)。基本上,只要你訪問了任何一個網站,該網站都會有你的行為記錄。
當然,日誌也是一個很大的概念,任何程式都有可能輸出日誌:作業系統核心、各種應用伺服器等等。日誌的內容
網站搭建筆記精簡版---廖雪峰WebApp實戰-Day11:編寫日誌建立頁筆記
今天實現建立部落格日誌的功能
首先在handlers檔案中增加後端功能函式,之後設定前端頁面。
程式碼之後會在github上附上。
handlers
# 驗證許可權是否正確
def check_admin(request):
if request.__u
ELK實戰篇--logstash日誌收集eslaticsearch和kibana
前篇:
ELK6.2.2日誌分析監控系統搭建和配置
ELK實戰篇
好,現在索引也可以建立了,現在可以來輸出nginx、apache、message、secrue的日誌到前臺展示(Nginx有的話直接修改,沒有自行安裝)
編輯nginx配置檔案,修改以下內容(在http模組下新增
大資料場景-使用者行為日誌分析
使用者日誌:
訪問的系統屬性:作業系統、瀏覽器型別
訪問特徵:點選的URL、來源(referer)url [推廣]、頁面停留時間
訪問資訊:session_id,訪問IP
價值:分析每個使用者的使用場景頻率高的業務點,分析每個使用者的IP 【解析到城市資訊】,根據使用
使用者行為日誌-js埋點(四)可能存在的問題和總結
記下了點選資訊,如何傳送出去呢?
考察了若干類似的系統,目前比較流行的方式似乎是將要傳送的資訊加到 URL 引數中,請求打點伺服器上的一個非常小的空圖片,這樣,資訊就將記錄在打點伺服器的日誌(比如 apache 日誌)中,之後再用專門的程式從日誌中讀取並分析相關資訊。而且,對於打點伺服器而言,由於只需要
使用者行為日誌分析概述
使用者行為日誌分析:Nginx,Ajax日誌資料內容: 1,訪問的系統屬性:作業系統,瀏覽器等等 2.點選的url,從哪個url跳轉過來,頁面停留時間 3.訪問資訊:session_id,訪問ip等日誌分析的意義: 1.網站的眼睛 2.網站的神經 3.網站的大腦離線資料
【 分類 】- 行為日誌分析
專欄達人
授予成功建立個人部落格專欄
Kafka專案實戰-使用者日誌上報實時統計之編碼實踐
1.概述
該課程我以使用者實時上報日誌案例為基礎,帶著大家去完成各個KPI的編碼工作,實現生產模組、消費模組,資料持久化,以及應用排程等工作, 通過對這一系列流程的演示,讓大家能夠去掌握Kafka專案的相關編碼以及排程流程。下面,我們首先來預覽本課程所包含的課時,他們分別
使用者行為日誌-js埋點(三)瀏覽記錄和停留時間思路
問題
公司想統計一個使用者從進入官網到註冊,這個流程該使用者整個的瀏覽路線,在哪個頁面停留的時間比較長,從而更有針對性的對客戶行為進行分析,瞭解使用者的真正需求。。。
雖然百度統計之類的也可以記錄使用者的瀏覽行為,但是這類統計是全部跟蹤使用者,而無法精確的跟蹤到註冊的使用者之前一系列的行為,而我們只需
Spring aop+自定義註解統一記錄使用者行為日誌
Spring aop+自定義註解統一記錄使用者行為日誌
原創: zhangshaolin 張少林同學 今天
寫在前面
本文不涉及過多的Spring aop基本概念以及基本用法介紹,以實際場景使用為主。
場景
我們通常有這樣一個需求:列印後臺介面
使用者行為日誌-js埋點(一)實現整體流程
網站資料統計分析工具是網站站長和運營人員經常使用的一種工具,比較常用的有谷歌分析、百度統計 和 騰訊分析等等。所有這些統計分析工具的第一步都是網站訪問資料的收集。目前主流的資料收集方式基本都是基於javascript的。本文將簡要分析這種資料收集的原理,並一步一步實際搭建一個實際的資料收集系統。
注:從
Tomcat收集使用者行為日誌
配置檔案
Tomcat---》conf--àserver.xml
預設配置資訊:
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"