
Tensorflow學習筆記(五)——結構化模型及Skip-gram模型的實現
一、結構化模型
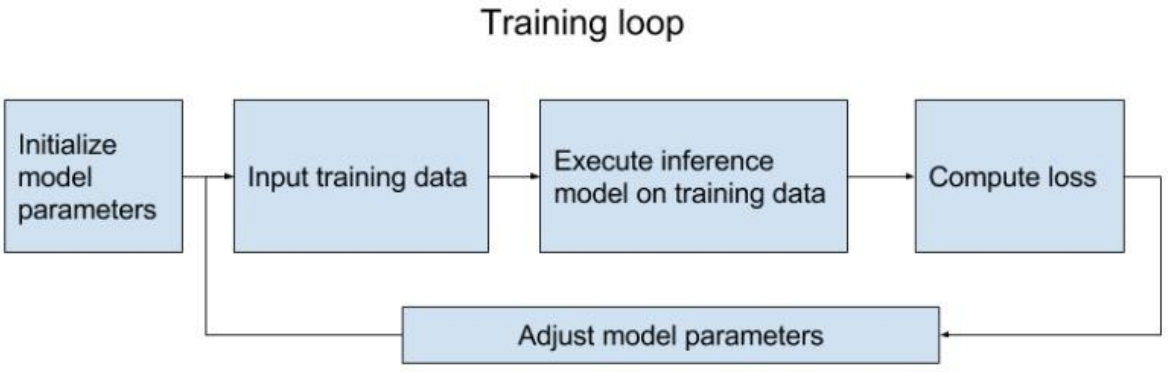
結構化我們的模型,可以方便我們Debug和良好的視覺化。一般我們的模型都是由以下兩步構成,第一步是構建計算圖,第二步是執行計算圖。
Assemble Graph
- Define placeholders for Input and output
- Define the weights
- Define the inference model
- Define loss function
- Define optimizer
Compute
二、Word Embedding
首先我們先理解一下詞向量的概念。簡單來說就是用一個向量去表示一個詞語。下面我們介紹兩個常用的word embedding 模型——CBOW 和 Skip-gram。
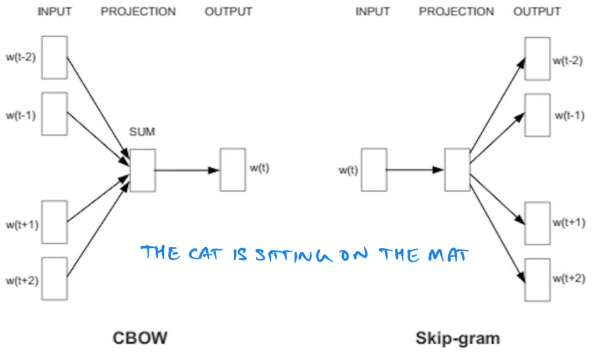
在CBOW模型中,我們給出的是預測目標詞彙的上下文,例如上面的句子中,假設視窗大小為2,我們給出詞彙是“the”“cat”和“sitting”“on”,目標詞彙為“is”;而Skip-gram相反,它給出的是中間的詞彙“is”,然後預測兩邊的詞彙。
關於Skip-gram的具體介紹詳見這篇文章
三、Skip-gram實現
資料集
這裡使用的是text8資料集,這是一個大約100 MB的清理過的資料集,當然這個資料集非常小並不足以訓練詞向量,但是我們可以得到一些有趣的結果。
構建計算圖
讀取資料部分在 process_data.py 有定義的函式可以直接使用。程式碼如下:
def main():
batch_gen = process_data(VOCAB_SIZE, BATCH_SIZE, SKIP_WINDOW)
ceters, targets = next(batch_gen)
word2vec(batch_gen)
if __name__ == '__main__':
main()之後我們將的skip-gram的實現都寫入 word2vec(batch_gen) 函式中。
首先定義好一些超引數
VOCAB_SIZE = 50000
BATCH_SIZE = 128
EMBED_SIZE = 128 # dimension of the word embedding vectors ① 建立輸入和輸出的佔位符(placeholder)
center_word = tf.placeholder(tf.int32, [BATCH_SIZE], name='center_words')
y = tf.placeholder(tf.int32, [BATCH_SIZE, SKIP_WINDOW], name='target_words')這裡SKIP_WINDOW表示預測周圍詞的數目,超引數裡面取值為1。
② 定義詞向量矩陣
embed_matrix = tf.get_variable(
"WordEmbedding", [VOCAB_SIZE, EMBED_SIZE],
tf.float32,
initializer=tf.random_uniform_initializer(-1.0, 1.0))這裡相當於新建一個Variable,維數分別是總的詞數x詞向量的維度。
③ 構建網路模型
我們可以通過下面的操作取到詞向量矩陣中所需要的每一個詞的詞向量。
embed = tf.nn.embedding_lookup(embed_matrix, center_word, name='embed')這裡embed_matrix和center_word分別表示詞向量矩陣和需要提取詞向量的單詞,我們都已經定義過了。
④ 定義loss函式
NCE已經被整合進了tensorflow,所以我們可以非常方便地進行使用,下面就是具體的api。
tf.nn.nce_loss(weights, biases, labels, inputs, num_sampled,
num_classes, num_true=1, sampled_values=None,
remove_accidental_hits=False, partition_strategy='mod',
name='nce_loss')labels和inputs分別是target和輸入的詞向量,前面有兩個引數分別時weights和biases,因為詞向量的維度一般不等於分類的維度,需要將詞向量通過一個線性變換對映到分類下的維度。有了這個定義之後,我們就能夠簡單地進行實現了。
nce_weight = tf.get_variable('nce_weight', [VOCAB_SIZE, EMBED_SIZE],
initializer=tf.truncated_normal_initializer(
stddev=1.0 / (EMBED_SIZE**0.5)))
nce_bias = tf.get_variable('nce_bias', [VOCAB_SIZE],
initializer=tf.zeros_initializer())
nce_loss = tf.nn.nce_loss(nce_weight, nce_bias, y, embed,
NUM_SAMPLED,
VOCAB_SIZE)
loss = tf.reduce_mean(nce_loss, 0)⑤ 定義優化函式
接下來我們就可以定義優化函數了,非常簡單,我們使用隨機梯度下降法。
optimizer = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(loss)執行計算圖
構建完成計算圖之後,我們就開始執行計算圖了,下面就不分開講了,直接放上整段session裡面的內容。
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
total_loss = 0.0 # we use this to calculate the average loss in the last SKIP_STEP steps0
writer = tf.summary.FileWriter('./graphs/no_frills/', sess.graph)
for index in range(NUM_TRAIN_STEPS):
centers, targets = next(batch_gen)
train_dict = {center_word: centers, y: targets}
_, loss_batch = sess.run([optimizer, loss], feed_dict=train_dict)
total_loss += loss_batch
if (index + 1) % SKIP_STEP == 0:
print('Average loss at step {}: {:5.1f}'.format(
index, total_loss / SKIP_STEP))
total_loss = 0.0
writer.close()通過閱讀程式碼,也能看到非常清晰的結構,一步一步去執行結果。
結構化網路
結構化網路非常簡單,只需要加入Name Scope。
with tf.name_scope(name_of_taht_scope):
# declare op_1
# declare op_2
# ...舉一個例子,比如我們定義輸入輸出的佔位符的時候,可以如下方式定義
with tf.name_scope('data'):
center_word = tf.placeholder(
tf.int32, [BATCH_SIZE], name='center_words')
y = tf.placeholder(
tf.int32, [BATCH_SIZE, SKIP_WINDOW], name='target_words')程式碼可參考這裡(引自 Sherlock 知乎專欄 深度煉丹)