
隨機取樣和隨機模擬:吉布斯取樣Gibbs Sampling
吉布斯取樣演算法詳解
為什麼要用吉布斯取樣
什麼是sampling?
sampling就是以一定的概率分佈,看發生什麼事件。舉一個例子。甲只能E:吃飯、學習、打球,時間T:上午、下午、晚上,天氣W:晴朗、颳風、下雨。現在要一個sample,這個sample可以是:打球+下午+晴朗。
吉布斯取樣的通俗解釋?
問題是我們不知道p(E,T,W),或者說,不知道三件事的聯合分佈joint distribution。當然,如果知道的話,就沒有必要用gibbs sampling了。但是,我們知道三件事的conditional distribution。也就是說,p(E|T,W),p(T|E,W),p(W|E,T)。現在要做的就是通過這三個已知的條件分佈,再用gibbs sampling的方法,得到聯合分佈
具體方法。首先隨便初始化一個組合,i.e. 學習+晚上+颳風,然後依條件概率改變其中的一個變數。具體說,假設我們知道晚上+颳風,我們給E生成一個變數,比如,學習-》吃飯。我們再依條件概率改下一個變數,根據學習+颳風,把晚上變成上午。類似地,把颳風變成颳風(當然可以變成相同的變數)。這樣學習+晚上+颳風-》吃飯+上午+颳風。同樣的方法,得到一個序列,每個單元包含三個變數,也就是一個馬爾可夫鏈。然後跳過初始的一定數量的單元(比如100個),然後隔一定的數量取一個單元(比如隔20個取1個)。這樣sample到的單元,是逼近聯合分佈的。
馬氏鏈收斂定理
馬氏鏈定理: 如果一個非週期馬氏鏈具有轉移概率矩陣P

其中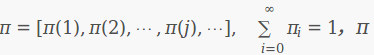
所有的 MCMC(Markov Chain Monte Carlo) 方法都是以這個定理作為理論基礎的。 定理的證明相對複雜。
定理內容的一些解釋說明
- 該定理中馬氏鏈的狀態不要求有限,可以是有無窮多個的;
- 定理中的“非週期“這個概念不解釋,因為我們遇到的絕大多數馬氏鏈都是非週期的;

Monte Carlo隨機取樣方法
產生獨立樣本
基本方法:概率積分變換(第一部分已講)
接受—拒絕(舍選)取樣
重要性取樣
產生相關樣本:Markov Chain Monte Carlo
Metropolis-Hastings演算法
Gibbs Sampler
這裡主要講馬爾科夫鏈蒙特卡羅( Markov chain Monte Carlo, MCMC ),它使得我們可以從一大類概率分佈中進行取樣,並且可以很好地應對樣本空間維度的增長。
Metropolis-Hastings取樣演算法
Idea
對於給定的概率分佈p(x),我們希望能有便捷的方式生成它對應的樣本。由於馬氏鏈能收斂到平穩分佈, 於是一個很的漂亮想法是:如果我們能構造一個轉移矩陣為P的馬氏鏈,使得該馬氏鏈的平穩分佈恰好是p(x), 那麼我們從任何一個初始狀態x0出發沿著馬氏鏈轉移, 得到一個轉移序列 x0,x1,x2,⋯xn,xn+1⋯,, 如果馬氏鏈在第n步已經收斂了,於是我們就得到了 π(x) 的樣本xn,xn+1⋯。
這個絕妙的想法在1953年被 Metropolis想到了,為了研究粒子系統的平穩性質, Metropolis 考慮了物理學中常見的波爾茲曼分佈的取樣問題,首次提出了基於馬氏鏈的蒙特卡羅方法,即Metropolis演算法,並在最早的計算機上程式設計實現。Metropolis 演算法是首個普適的取樣方法,並啟發了一系列 MCMC方法,所以人們把它視為隨機模擬技術騰飛的起點。 Metropolis的這篇論文被收錄在《統計學中的重大突破》中, Metropolis演算法也被遴選為二十世紀的十個最重要的演算法之一。
我們接下來介紹的MCMC 演算法是 Metropolis 演算法的一個改進變種,即常用的 Metropolis-Hastings 演算法。由上一節的例子和定理我們看到了,馬氏鏈的收斂性質主要由轉移矩陣P 決定, 所以基於馬氏鏈做取樣的關鍵問題是如何構造轉移矩陣P,使得平穩分佈恰好是我們要的分佈p(x)。如何能做到這一點呢?
細緻平穩條件
定理:[細緻平穩條件] 如果非週期馬氏鏈的轉移矩陣P和分佈Π(x)滿足
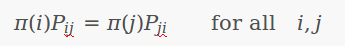
則Π(x)是馬氏鏈的平穩分佈,上式被稱為細緻平穩條件(detailed balance condition)。
其實這個定理是顯而易見的,因為細緻平穩條件的物理含義就是對於任何兩個狀態i,j,從i轉移出去到j而丟失的概率質量,恰好會被從j轉移回i的概率質量補充回來,所以狀態i上的概率質量Π(x)是穩定的,從而Π(x)是馬氏鏈的平穩分佈。數學上的證明也很簡單,由細緻平穩條件可得

由於Π是方程 ΠP = Π的解,所以Π是平穩分佈。
Note:細緻平穩條件是達到穩態的充分條件,並不是必要條件(也就是說要想達到穩態,必須要滿足細緻平衡條件,但也不是說滿足細緻平衡條件時的點就是穩態,而是說細緻平衡條件是達到穩態的必經之路)。如在[馬爾科夫模型]示例中0.28*0.286=0.08008,0.15*0.489=0.07335不相等,並不符合細緻平穩條件。
構建滿足條件的馬氏鏈
假設我們已經有一個轉移矩陣為Q的馬氏鏈 (q(i,j)表示從狀態i轉移到狀態j的概率,也可以寫為q(j|i)或者q(i→j)), 顯然,通常情況下
p(i)q(i,j)≠p(j)q(j,i)
也就是細緻平穩條件不成立,所以 p(x) 不太可能是這個馬氏鏈的平穩分佈。我們可否對馬氏鏈做一個改造,使得細緻平穩條件成立呢?譬如,我們引入一個 α(i,j), 我們希望
p(i)q(i,j)α(i,j)=p(j)q(j,i)α(j,i)(∗)(2)
取什麼樣的 α(i,j) 以上等式能成立呢?最簡單的,按照對稱性,我們可以取
α(i,j)=p(j)q(j,i),α(j,i)=p(i)q(i,j)
於是(*)式就成立了。所以有
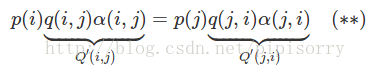
於是我們把原來具有轉移矩陣Q的一個很普通的馬氏鏈,改造為了具有轉移矩陣Q′的馬氏鏈,而Q′恰好滿足細緻平穩條件,由此馬氏鏈Q′的平穩分佈就是p(x)!
在改造 Q 的過程中引入的 α(i,j)稱為接受率,物理意義可以理解為在原來的馬氏鏈上,從狀態i 以q(i,j) 的概率轉跳轉到狀態j 的時候,我們以α(i,j) 的概率接受這個轉移,於是得到新的馬氏鏈Q′的轉移概率為q(i,j)α(i,j)。
Note:當按照上面介紹的構造方法把Q–>Q’後,就不能保證Q’是一個轉移矩陣(轉移矩陣每一行加和為1)了。這時應該在 j != i 的時候轉移概率Q'(i, j) 如上處理, 當j = i 的時候, Q'(i, i) 應該設為Q'(i, i) = 1- 其它概率之和,從而歸一化概率轉移矩陣。
馬氏鏈轉移和接受概率:
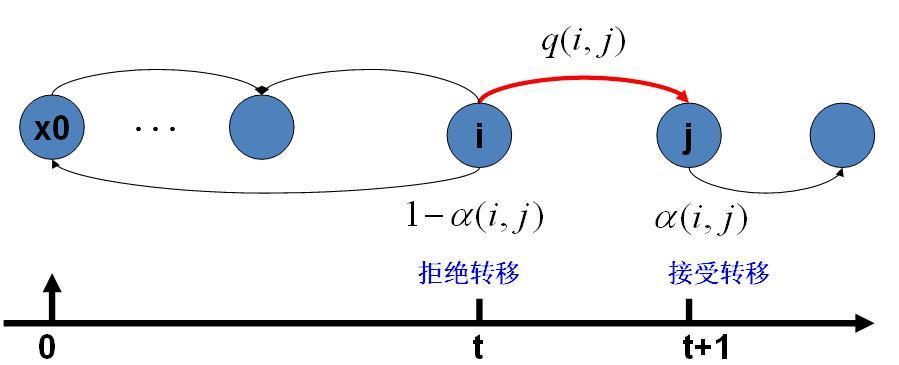
MCMC取樣演算法
取樣概率分佈p(x)的演算法,假設我們已經有一個轉移矩陣Q(對應元素為q(i,j)),lz: 馬氏鏈的初始狀態及狀態指的是概率分佈π=[π(1),π(2),⋯,π(j),⋯]

Note: 一開始的取樣還沒有收斂,並不是平穩分佈(p(x))的樣本(概率分佈中的其中一個概率分佈),只有取樣了多次(如20次)可能收斂了,其樣本才算是平穩分佈的樣本。
上述過程中 p(x),q(x|y) 說的都是離散的情形,事實上即便這兩個分佈是連續的,以上演算法仍然是有效,於是就得到更一般的連續概率分佈 p(x) 的取樣演算法,而q(x|y) 就是任意一個連續二元概率分佈對應的條件分佈。
Metropolis-Hastings演算法
{提高接受率alpha}
以上的 MCMC 取樣演算法已經能很漂亮的工作了,不過它有一個小的問題:馬氏鏈Q在轉移的過程中的接受率α(i,j) 可能偏小,這樣取樣過程中馬氏鏈容易原地踏步,拒絕大量的跳轉,這使得馬氏鏈遍歷所有的狀態空間要花費太長的時間,收斂到平穩分佈p(x) 的速度太慢。有沒有辦法提升一些接受率呢?
假設 α(i,j)=0.1,α(j,i)=0.2 , 此時滿足細緻平穩條件,於是
p(i)q(i,j)×0.1=p(j)q(j,i)×0.2
上式兩邊擴大5倍,我們改寫為
p(i)q(i,j)×0.5=p(j)q(j,i)×1
看,我們提高了接受率,而細緻平穩條件並沒有打破!這啟發我們可以把細緻平穩條件(**) 式中的α(i,j),α(j,i) 同比例放大,使得兩數中最大的一個放大到1,這樣我們就提高了取樣中的跳轉接受率。所以我們可以取
α(i,j)=min{p(j)q(j,i)p(i)q(i,j),1}
於是,經過對上述MCMC 取樣演算法中接受率的微小改造,我們就得到了如下教科書中最常見的 Metropolis-Hastings 演算法。

對於分佈 p(x),我們構造轉移矩陣Q′ 使其滿足細緻平穩條件
p(x)Q′(x→y)=p(y)Q′(y→x)
此處 x 並不要求是一維的,對於高維空間的 p(x),如果滿足細緻平穩條件
p(x)Q′(x→y)=p(y)Q′(y→x)
那麼以上的 Metropolis-Hastings 演算法一樣有效。
Gibbs Sampling演算法
{提高高維隨機變數取樣接受率alpha}
MCMC:Markov鏈通過轉移概率矩陣可以收斂到穩定的概率分佈。這意味著MCMC可以藉助Markov鏈的平穩分佈特性模擬高維概率分佈p(x);當Markov鏈經過burn-in階段,消除初始引數的影響,到達平穩狀態後,每一次狀態轉移都可以生成待模擬分佈的一個樣本。
而Gibbs抽樣是MCMC的一個特例,它交替的固定某一維度xi,然後通過其他維度x⃗ ¬i的值來抽樣該維度的值,注意,gibbs取樣只對z是高維(2維以上)(Gibbs sampling is applicable in situations where Z has at least two dimensions)情況有效。
基本演算法如下:
- 選擇一個維度
i,可以隨機選擇; - 根據分佈
p(xi|x¬i)抽樣xi。
吉布斯取樣滿足細緻平穩條件的轉移矩陣的構造
對於高維的情形,由於接受率 α的存在(通常α<1), 以上 Metropolis-Hastings 演算法的效率不夠高。能否找到一個轉移矩陣Q使得接受率 α=1 呢?我們先看看二維的情形,假設有一個概率分佈 p(x,y), 考察x座標相同的兩個點A(x1,y1),B(x1,y2),我們發現
lz: 從下式可看出,M-H方法是從p(xi)出發構建細緻平穩條件,而gibbs是從p(xi, yj)出發構建細緻平穩條件。
p(x1,y1)p(y2|x1)=p(x1)p(y1|x1)p(y2|x1)p(x1,y2)p(y1|x1)=p(x1)p(y2|x1)p(y1|x1)
所以得到
p(x1,y1)p(y2|x1)=p(x1,y2)p(y1|x1)(∗∗∗)(4)
即
p(A)p(y2|x1)=p(B)p(y1|x1)
基於以上等式,我們發現,在 x=x1 這條平行於 y軸的直線上,如果使用條件分佈p(y|x1) 作為任何兩個點之間的轉移概率,那麼任何兩個點之間的轉移滿足細緻平穩條件。
同樣的,如果我們在 y=y1 這條直線上任意取兩個點 A(x1,y1),C(x2,y1),也有如下等式
p(A)p(x2|y1)=p(C)p(x1|y1).
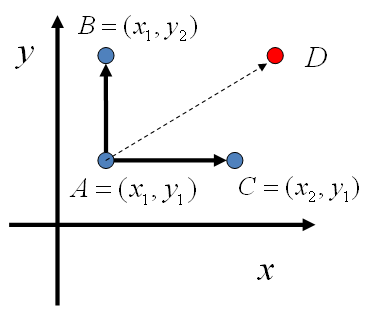
於是我們可以如下構造平面上任意兩點之間的轉移概率矩陣Q
Q(A→B)Q(A→C)Q(A→D)=p(yB|x1)=p(xC|y1)=0如果xA=xB=x1如果yA=yC=y1其它
有了如上的轉移矩陣 Q, 我們很容易驗證對平面上任意兩點 X,Y, 滿足細緻平穩條件
p(X)Q(X→Y)=p(Y)Q(Y→X)
於是這個二維空間上的馬氏鏈將收斂到平穩分佈 p(x,y) 。而這個演算法就稱為 Gibbs Sampling 演算法,是 Stuart Geman 和Donald Geman 這兩兄弟於1984年提出來的,之所以叫做Gibbs Sampling 是因為他們研究了Gibbs random field, 這個演算法在現代貝葉斯分析中佔據重要位置。
lz: 從這可以看出,gibbs取樣和M-H取樣的不同在於,gibbs取樣從更大角度考慮了每次取樣間的聯絡,也就是M-H只是單獨考慮某個pi_i的取樣(相當於直接從A -> D),而gibbs考慮了pi_j和其它如pi_j間的關係,從而從固定pi_j的角度出發,對pi_i取樣加速(取樣都是沿著座標軸進行的)。
二維吉布斯取樣演算法

Note: 取樣演算法中右邊的概率我們是知道的,例如你要取樣的是二維高斯分佈,那麼固定xt後就是二維高斯分佈固定xt後的一維高斯分佈,且每次取樣的座標不同,這樣這個一維高斯分佈概率密度函式也就不一樣了。
Gibbs Sampling 演算法中的馬氏鏈轉移
Note:2.1步是從 (x0,y0)轉移到(x0,y1),滿足Q(A→B)=p(yB|x1)的細緻平穩條件,所以會收斂到平穩分佈;同樣2.2步是從(x0,y1)轉移到(x1,y1),也會收斂到平穩分佈。也就是整個第2步是從 (x0,y0)轉移到(x1,y1),滿足細緻平穩條件,在迴圈多次後會收斂於平穩分佈,取樣得到的(xn,yn),(xn+1,yn+1)...就是平穩分佈的樣本(lz:不是(xn,yn),(xn,yn+1),(xn+1,yn+1)...,因為需要歸一化)。
以上取樣過程中,如圖所示,馬氏鏈的轉移只是輪換的沿著座標軸 x軸和y軸做轉移,於是得到樣本(x0,y0),(x1,y1),(x2,y2),⋯馬氏鏈收斂後,最終得到的樣本就是 p(x,y) 的樣本,而收斂之前的階段稱為 burn-in period。也就是說馬氏鏈跳轉過程就是取樣的過程(取樣的意思就是說在xt下,我們先計算出p(y|xt)的概率分佈,並依這個概率分佈取樣某個yt+1), 馬氏鏈任何一個時刻 i 到達的狀態 x_i 都是一個樣本。 只是要等到 i 足夠大( i > K) , 馬氏鏈收斂到平穩分佈後, 那麼 x_K, x_{K+1}, …. 這些樣本就都是平穩分佈的樣本。
lz:最終的近似平穩分佈就可以通過取樣結果近似表達出來。
座標軸輪換取樣
一般地,Gibbs Sampling 演算法大都是座標軸輪換取樣的,但是這其實是不強制要求的。最一般的情形可以是,在t 時刻,可以在x軸和y 軸之間隨機的選一個座標軸,然後按條件概率做轉移,馬氏鏈也是一樣收斂的。輪換兩個座標軸只是一種方便的形式。
lz: 但是不能只固定一個取樣的,否則樣本都是從某個固定維度取樣,並不具有整個分佈的代表性。
n維吉布斯取樣演算法
以上的過程我們很容易推廣到高維的情形,對於(***) 式,如果x1變為多維情形x1,可以看出推導過程不變,所以細緻平穩條件同樣是成立的
p(x1,y1)p(y2|x1)=p(x1,y2)p(y1|x1)(5)
此時轉移矩陣 Q 由條件分佈 p(y|x1) 定義。上式只是說明了一根座標軸的情形,和二維情形類似,很容易驗證對所有座標軸都有類似的結論。
所以n維空間中對於概率分佈p(x1,x2,⋯,xn) 可以如下定義轉移矩陣
- 如果當前狀態為(x1,x2,⋯,xn),馬氏鏈轉移的過程中,只能沿著座標軸做轉移。沿著xi 這根座標軸做轉移的時候,轉移概率由條件概率 p(xi|x1,⋯,xi−1,xi+1,⋯,xn) 定義;
- 其它無法沿著單根座標軸進行的跳轉,轉移概率都設定為 0。
於是我們可以把Gibbs Sampling 演算法從取樣二維的 p(x,y) 推廣到取樣n 維的 p(x1,x2,⋯,xn)


Note:
1 Algorithm 8中的第2步的第6小步,x2(t)應為x2(t+1)。
2 要完成Gibbs抽樣,需要知道如下條件概率:p(xi|x¬i)=p(x)p(x¬i)=p(x)∫p(x)dxi,x={xi,x¬i}
lz這也就是說,gibbs取樣是通過條件分佈取樣模擬聯合分佈,再通過模擬的聯合分佈直接推匯出條件分佈,以此迴圈。
Gibbs sampling makes it possible to obtain samples from probability distributions without having to explicitly calculate the values for their marginalizing integrals, e.g. computing expected values, by defining a conceptually straightforward approximation.
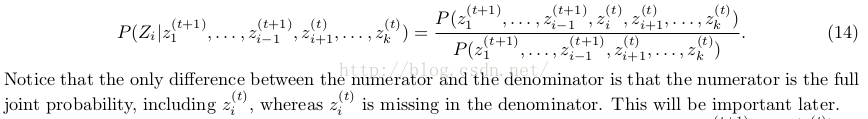
以上演算法收斂後,每次完整的迴圈完成後得到的(xn+1,yn+1)...就是概率分佈p(x1,x2,⋯,xn)的一個樣本。(lz: g(.)是歸一化)
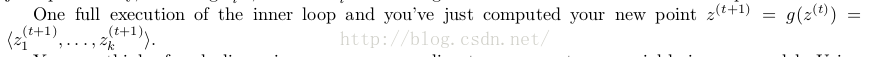
同樣的,在以上演算法中,座標軸輪換取樣不是必須的,可以在座標軸輪換中引入隨機性,這時候轉移矩陣 Q 中任何兩個點的轉移概率中就會包含座標軸選擇的概率,而在通常的 Gibbs Sampling 演算法中,座標軸輪換是一個確定性的過程,也就是在給定時刻t,在一根固定的座標軸上轉移的概率是1。
吉布斯取樣的相關性和獨立性
馬爾科夫鏈中的連續的樣本是高度相關的(they were produced by a process that conditions on the previous point in the chain to generate the next point. This is referred to as autocorrelation (sometimes serial autocorrelation), i.e. correlation between successive values in the data.),這些樣本並不獨立,但是我們此處要求的是取樣得到的樣本符合給定的概率分佈,並不要求獨立。
吉布斯取樣的接受率計算
吉布斯取樣可以看做是M-H演算法的一個特例,即接受率α=1的情況。證明如下:
考慮一個M-H取樣的步驟,它涉及到變數zk,剩餘變數z¬k保持不變。同時,從z到z∗的轉移概率為q k(z∗|z)=p(z∗k|z¬k)。我們注意到z∗¬k=z¬k,因為再取樣步驟中,向量的各個元素都不變。又p(z)=p(zk|z¬k)p(z¬k),因此,確定M-H演算法中的接受概率為
A(z∗,z)=p(z∗)qk(z|z∗)p(z)qk(z∗|z)=p(z∗k|z∗¬k)p(z∗¬k)p(zk|z∗¬k)p(zk|z¬k)p(z¬k)p(z∗k|z¬k)=1
吉布斯取樣收斂的判斷
無論metropolis-hasting演算法還是gibbs演算法,都需要一個burn in過程,只有在達到平衡狀態時候得到的樣本才能是平衡狀態時候的目標分佈的樣本,因此,在burn in過程中產生的樣本都需要被捨棄。如何判斷一個過程是否達到了平衡狀態還沒有一個成熟的方法來解決,目前常見的方法是看是否狀態已經平穩(例如畫一個圖,如果在較長的過程中,變化已經不大,說明很有可能已經平衡)當然這個方法並不能肯定一個狀態是否平衡,你可以舉出反例,但是卻是實際中沒有辦法的辦法。
關於鏈的收斂有這樣一些檢驗方法
(1)圖形方法 這是簡單直觀的方法。我們可以利用這樣一些圖形:
(a)跡圖(trace plot):將所產生的樣本對迭代次數作圖,生成馬氏鏈的一條樣本路徑。如果當t足夠大時,路徑表現出穩定性沒有明顯的週期和趨勢,就可以認為是收斂了。
(b)自相關圖(Autocorrelation plot):如果產生的樣本序列自相關程度很高,用跡圖檢驗的效果會比較差。一般自相關隨迭代步長的增加而減小,如果沒有表現出這種現象,說明鏈的收斂性有問題。
(c)遍歷均值圖(ergodic mean plot):MCMC的理論基礎是馬爾科夫鏈的遍歷定理。因此可以用累積均值對迭代步驟作圖,觀察遍歷均值是否收斂。
(2)蒙特卡洛誤差
(3)Gelman-Rubin方法
關於gibbs sampling的收斂,可以採用R^統計量。同時,可以多開幾個chain進行模擬。判斷收斂的時候,應該掐頭去尾計算R^。
在工程實踐中我們更多的靠經驗和對資料的觀察來指定 Gibbs Sampling 中的 burn-in 的迭代需要多少次。
Robert and Casella ( 1999 )總結了馬爾科夫鏈蒙特卡羅演算法的收斂性檢測。
Jordan Boyd-Graber (personal communication) also recommends looking at Neal’s [15] discussion of likelihood as a metric of convergence.
[15] R. M. Neal. Probabilistic inference using markov chain monte carlo methods. Technical Report CRGTR-93-1, University of Toronto, 1993. http://www.cs.toronto.edu/∼radford/ftp/review.pdf.
burn-in階段可能不需要
當然可以一條鏈跑到黑,但是一條鏈跑到黑只能是寫學術 paper 的做法,在工程上可能還是要考慮很實際的速度和效率的問題,做 LDA 的時候我們就得考慮每秒鐘能處理多少個請求,這時候不得不設定 burn-in。
[Charles Geyer:為什麼一條鏈走到黑是正確的One Long Run in MCMC]
Jason Eisner (personal communication) argues, with some support from the literature, that burn-in, lag, and multiple chains are in fact unnecessary and it is perfectly correct to do a single long sampling run and keep all samples. See [4, 5], MacKay ([13], end of section 29.9, page 381) and Koller and Friedman ([10], end of section 12.3.5.2, page 522).
[4] C. Geyer. Burn-in is unnecessary, 2009. http://www.stat.umn.edu/∼charlie/mcmc/burn.html, Downloaded October 18, 2009.
[5] C. Geyer. One long run, 2009. http://www.stat.umn.edu/∼charlie/mcmc/one.html.
[10] D. Koller and N. Friedman. Probabilistic Graphical Models: Principles and Techniques. MIT Press, 2009.
[13] D. Mackay. Information Theory, Inference, and Learning Algorithms. Cambridge University Press, 2003.
得到近似的獨立樣本
為了得到近似獨立的樣本可以對序列進行取樣。
In order to avoid autocorrelation problems (so that the chain “mixes well”), many implementations of Gibbs sampling average only every L th value, where L is referred to as thelag.
the choice of L seems to be more a matter of art than science: people seem to look at plots of the autocorrelation for different values of L and use a value for which the autocorrelation drops off quickly. The autocorrelation for variable Z i with lag L is simply the correlation between the sequence Z i(t) and the sequence Z i(t−L) . Which correlation function is used seems to vary.
[Philip Resnik : GIBBS SAMPLING FOR THE UNINITIATED]
吉布斯取樣高階主題
隱變數Gibbs抽樣公式
如果模型包含隱變數z,通常需要知道後驗概率分佈p(z|x) (如LDA中要推斷的目標分佈p(z|w)),但是這個分佈因涉及很多離散隨機變數等原因很難求解。
我們期望Gibbs抽樣器可以通過Markov鏈利用全部的條件分佈p(zi|z¬i,w) 來模擬p(z|w) 。所以包含隱變數的Gibbs抽樣器公式如下:
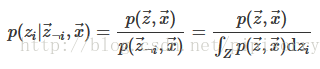
lz:這裡分母實際只是分子對zi的一個積分,將變數zi積分掉,就得到p(z-i, x),所以重點在聯合分佈p(z,w)公式上,一般先推出聯合分佈公式再積分就可以使用上面的隱變數gibbs取樣公式了。而這個聯合分佈就是我們取樣出來的結果組成的近似分佈了。
多鏈Multiple chains
As is the case for many other stochastic algorithms (e.g. expectation maximization as used in the forward-backward algorithm for HMMs), people often try to avoid sensitivity to the starting point chosen at initialization time by doing multiple runs from different starting points. For Gibbs sampling and other Markov Chain Monte Carlo methods, these are referred to as “multiple chains”.
超引數的取樣Hyperparameter sampling
Rather than simply picking hyperparameters, it is possible, and in fact often critical, to assign their values via sampling (Boyd-Graber, personal communication). See, e.g., Wallach et al. [20] and Escobar and West [3].
[3] M. D. Escobar and M. West. Bayesian density estimation and inference using mixtures. Journal of the American Statistical Association, 90:577–588, June 1995.
[20] H. Wallach, C. Sutton, and A. McCallum. Bayesian modeling of dependency trees using hierarchical Pitman-Yor priors. In ICML Workshop on Prior Knowledge for Text and Language Processing, 2008.
其它蒙特卡羅方法
silce sampling(連續取樣M個點)
吉布斯取樣的實現
PRML
從隨機過程到馬爾科夫鏈蒙特卡洛方法
An Introduction to MCMC for Machine Learning,2003
Introduction to Monte Carlo Methods
吉布斯取樣
吉布斯取樣分散式實現
吉布斯取樣與lda