
馬爾科夫過程與吉布斯取樣
隨機模擬(或者統計模擬)方法有一個很酷的別名是蒙特卡羅方法(Monte Carlo Simulation)。這個方法的發展始於20世紀40年代,和原子彈製造的曼哈頓計劃密切相關,當時的幾個大牛,包括烏拉姆、馮.諾依曼、費米、費曼、Nicholas Metropolis, 在美國洛斯阿拉莫斯國家實驗室研究裂變物質的中子連鎖反應的時候,開始使用統計模擬的方法,並在最早的計算機上進行程式設計實現。
 隨機模擬與計算機
隨機模擬與計算機
現代的統計模擬方法最早由數學家烏拉姆提出,被Metropolis命名為蒙特卡羅方法,蒙特卡羅是著名的賭場,賭博總是和統計密切關聯的,所以這個命名風趣而貼切,很快被大家廣泛接受。被不過據說費米之前就已經在實驗中使用了,但是沒有發表。說起蒙特卡羅方法的源頭,可以追溯到18世紀,布豐當年用於計算
 蒙特卡羅方法
蒙特卡羅方法
統計模擬中有一個重要的問題就是給定一個概率分佈
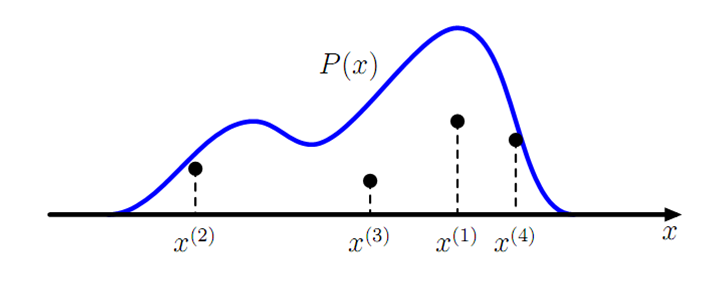
生成一個概率分佈的樣本
而我們常見的概率分佈,無論是連續的還是離散的分佈,都可以基於
[Box-Muller 變換] 如果隨機變數
則
其它幾個著名的連續分佈,包括指數分佈、Gamma 分佈、t 分佈、F 分佈、Beta 分佈、Dirichlet 分佈等等,也都可以通過類似的數學變換得到;離散的分佈通過均勻分佈更加容易生成。更多的統計分佈如何通過均勻分佈的變換生成出來,大家可以參考統計計算的書,其中 Sheldon M. Ross 的《統計模擬》是寫得非常通俗易懂的一本。
不過我們並不是總是這麼幸運的,當
p(x)=p~(x)∫p~(x)dx p(x)=p~(x)∫p~(x)dx,而p~(x) p~(x) 我們是可以計算的,但是底下的積分式無法顯式計算。相關推薦
馬爾科夫過程與吉布斯取樣
隨機模擬(或者統計模擬)方法有一個很酷的別名是蒙特卡羅方法(Monte Carlo Simulation)。這個方法的發展始於20世紀40年代,和原子彈製造的曼哈頓計劃密切相關,當時的幾個大牛,包括烏拉姆、馮.諾依曼、費米、費曼、Nicholas Metropolis
從馬爾科夫過程到吉布斯取樣(附程式示例)
目標:如何採取滿足某個概率分佈的一組資料,比如如何給出滿足標準正太分佈的1000個點,當然該分佈比較簡單,生成滿足此分佈的1000個點並不難,對matlab,python 等都是一行語句的事,但是如果是一個不常見的分佈,怎樣採集呢? 本文試圖通過示例讓讀者理解從馬爾科夫鏈到
隱馬爾科夫模型與三個問題
自然語言處理 算法 隱馬爾科夫模型定義 隱馬爾可夫模型是關於時序的概率模型,描述由一個隱藏的馬爾可夫鏈隨機生成不可觀測的狀態隨機序列,再由各個狀態生成一個觀測而產生觀測隨機序列的過程。 隱藏的馬爾可夫鏈隨機生成的狀態的序列,稱為狀態序列(state sequence);每個狀態生成一個觀測,而由此產生
馬爾科夫過程的CKS方程的推導
process tps 推導 RoCE 條件 協調 ESS edi 比較 概率論中的Chapman-Kolmogorov方程(或CKS方程)是指:https://en.wikipedia.org/wiki/Chapman%E2%80%93Kolmogorov_equatio
[定理證明]正態隨機過程又是馬爾科夫過程的充要條件
lin 百度 com .com erl .cn ear 模型 ont 必要性的證明 充分性的證明 參考 參考1:《概率論與數理統計教材》(茆詩松,第二版) 參考2:[公式推導]用最簡潔的方法證明多元正態分布的條件分布 參考3:《
深度學習 --- 受限玻爾茲曼機(馬爾科夫過程、馬爾科夫鏈)
上一節我們詳細的探討了玻爾茲曼機,玻爾茲曼機的發明是為了解決Hopfield神經網路的偽吸引子的問題,因此把退火演算法、玻爾茲曼分佈和Hopfield神經網路結合在一起形成了玻爾茲曼機(隨機神經網路)。通過前面幾節我們知道玻爾茲曼機可以很好
馬爾科夫模型與隱馬爾科夫模型
1. 馬爾科夫模型 1.1馬爾可夫過程 馬爾可夫過程(Markov process)是一類隨機過程。它的原始模型馬爾可夫鏈,由俄國數學家A.A.馬爾可夫於1907年提出。該過程具有如下特性:在已知目前狀態(現在)的條件下,它未來的演變(將來)不依賴於它
蒙特卡羅 馬爾科夫鏈 與Gibbs取樣
這幾個概念看了挺多遍都還是含混不清,最近看了幾篇部落格,才算大致理解了一點點皮毛,所以來總結一下。MCMC概述 從名字我們可以看出,MCMC由兩個MC組成,即蒙特卡羅方法(Monte Carlo Simulation,簡稱MC)和馬爾科夫鏈(Ma
馬爾科夫鏈與轉移矩陣
什麼是轉移概率矩陣(Transition Probability Matrix) 轉移概率矩陣:矩陣各元素都是非負的,並且各行元素之和等於1,各元素用概率表示,在一定條件下是互相轉移的,故稱為轉移概率矩陣。如用於市場決策時,矩陣中的元素是市場或顧客的保留、獲得或失去的概
蒙特卡羅馬爾科夫與吉布斯采樣
body inf 9.png com pos eight div alt image 蒙特卡羅馬爾科夫與吉布斯采樣
馬爾科夫隨機場(MRF)與吉布斯分佈(Gibbs)
1. 首先由兩個定義,什麼是馬爾科夫隨機場,以及什麼是吉布斯分佈 馬爾科夫隨機場:對於一個無向圖模型G,對於其中的任意節點X_i,【以除了他以外的所有點為條件的條件概率】和【以他的鄰居節點為條件的條件概率】相等,那麼這個無向圖就是馬爾科夫隨機場 Gibbs分佈:如果無向圖模型能
概率分布與馬爾科夫鏈的關系討論(上傳費事)
com info 技術分享 技術 17. 分享 概率 討論 關系 概率分布與馬爾科夫鏈的關系討論(上傳費事)
概率分布與馬爾科夫鏈的關系討論
而且 ID inf 選擇 之間 tran http 馬爾科夫 方法 概率分布與馬爾科夫鏈的關系討論2018年6月24日22:38Copyright ? 2018 Lucas Yu 小編原創,任何形式傳播(轉載或復制),請註明出處,謝謝! 摘要: 本文主要討論使
強化學習(David Silver)2:MDP(馬爾科夫決策過程)
war 觀察 turn 解法 求解 有關 馬爾科夫 函數 使用 1、MP(馬爾科夫過程) 1.1、MDP介紹 1)MDP形式化地強化學習中的環境(此時假設環境完全可以觀察) 2) 幾乎所有強化學習問題都可以形式化為MDP(部分可觀察的環境也可以轉化為MDP????) 1.2
馬爾科夫決策過程
技術分享 mar silver 接下來 馬爾科夫 ima gamma nbsp 給定 馬爾科夫特性: 下一時刻的狀態只與現在的時刻的狀態相關,與之前的時刻無關,即狀態信息包含了歷史的所有相關信息。 馬爾科夫獎勵過程,$<S, P, R, \gamma>$:
強化學習(RLAI)讀書筆記第三章有限馬爾科夫決策過程(finite MDP)
第三章 有限馬爾科夫決策過程 有限馬爾科夫決策過程(MDP)是關於評估型反饋的,就像多臂老虎機問題裡一樣,但是有是關聯型的問題。MDP是一個經典的關於連續序列決策的模型,其中動作不僅影響當前的反饋,也會影響接下來的狀態以及以後的反饋。因此MDP需要考慮延遲反饋和當前反饋與延遲反饋之間的交換。
馬爾科夫獎賞過程
0 前言 本文寫作目的:儘量通俗講解強化學習知識,使讀者不會被各種概念嚇倒!本文是第一篇,但是最關鍵的一篇是第二篇馬爾科夫決策過程(Markov Decision Process,MDP),只有充分理解了馬爾科夫決策過程,才能遊刃有餘的學習後續知識,所以希望讀者能夠將MDP深入理解後再去學習後續
從馬爾科夫決策過程到強化學習(From Markov Decision Process to Reinforcement Learning)
從馬爾科夫決策過程到強化學習(From Markov Decision Process to Reinforcement Learning) 作者:Bluemapleman([email protected]) Github:https://github.com/blu
馬爾科夫決策過程MDP - Lecture Note for CS188(暨CS181 ShanghaiTech)
說明:筆記旨在整理我校CS181課程的基本概念(PPT借用了Berkeley CS188)。由於授課及考試語言為英文,故英文出沒可能。 目錄 1 Markov Decision Processes mechanics 1.1 Markov Decision
隱馬爾科夫模型(HMM)與維特比(Viterbi)演算法通俗理解
隱馬爾科夫模型:https://blog.csdn.net/stdcoutzyx/article/details/8522078 維特比演算法:https://blog.csdn.net/athemeroy/article/details/79339546 隱含馬爾可夫模型並不是俄