
mapreduce框架內部核心工作流程
mapreduce框架內部核心工作流程圖
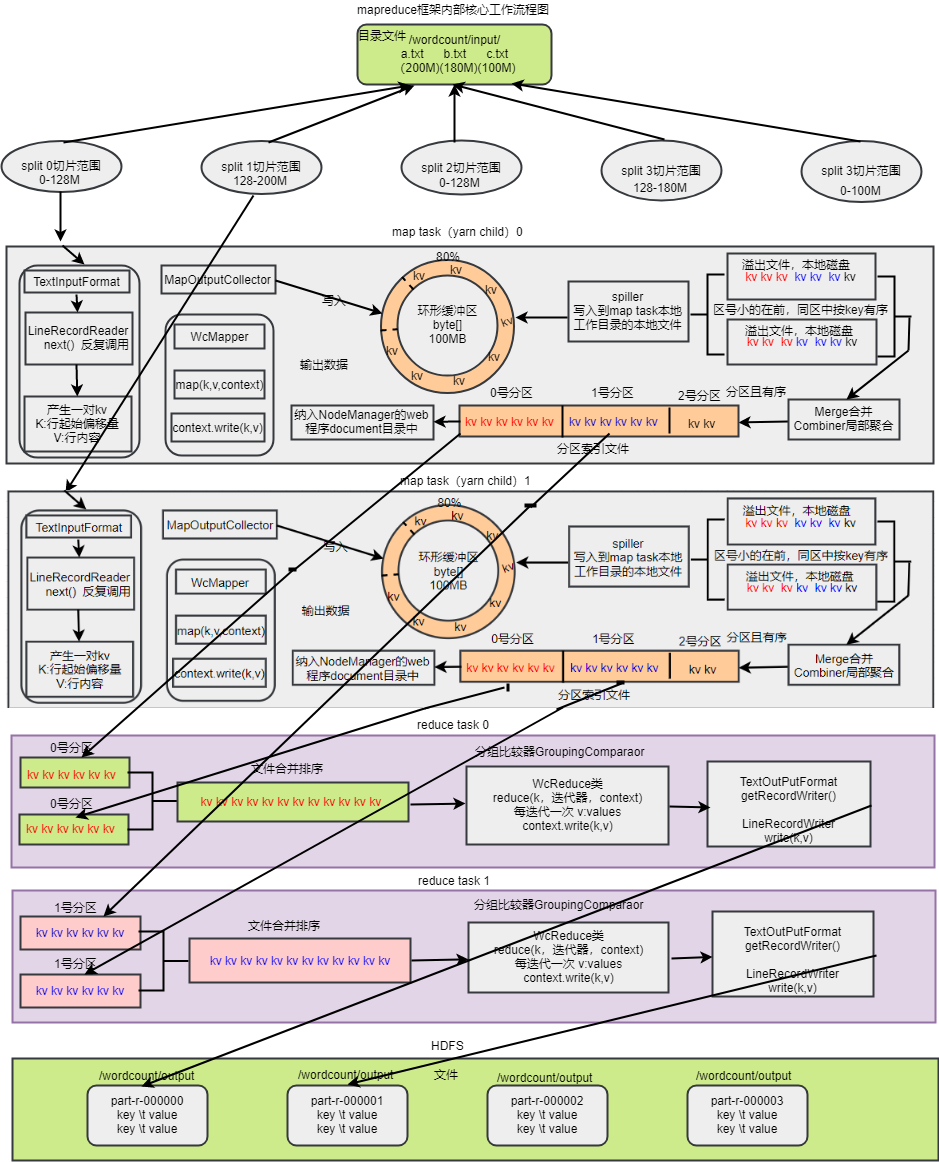
流程
1、mapTask呼叫InputFormat再呼叫RecourReader的read()方法來讀取資料,獲得key、value,mapreduce通過InputFormat來解耦
2、read()方法依靠一次讀取一行的邏輯來讀取原始檔案的資料,返回key、value,mapTask會將其交給自定義的Mapper
3、map方法我們會呼叫context.write方法來輸出資料到OutPutCollector類,OutPutCollector會將資料放到(記憶體中存放 預設MR.SORT.MB:100MB可以自己配置,一般不會放滿預設80%,這裡面還要留有空間排序預設20%)環形緩衝區(其實就是一個bite()陣列,如果寫滿了,那麼就會一邊寫一邊將開始的資料回收,然後繼續寫到回收後的位置上,形成了環形緩衝區)
4、環形緩衝區的溢位的資料溢位之前會通過Hashpartioner進行分割槽、排序(預設是快速排序法key.compareTO),會通過spiller寫入到mapTask工作目錄的本地檔案(所有溢寫檔案分割槽且區內有序)
5、所有溢位的檔案會做歸併排序形成mapTask的最終結果檔案,一個mapTask對應一個最終結果檔案,形成幾個分割槽就會有對應幾個reduceTask。reduceTask的個數由配置檔案或者引數設定,只要不設定自定義partitioner,那麼這裡的分割槽會動態適配reduceTask個數。如果設定了自定義partitioner,那麼就需要提前設定對應的reduceTask的個數
6、每個reduceTask都會到每一個mapTask的節點去下載分割槽檔案到reduceTask的本地磁碟工作目錄
7、為了保證最後的結果有序,reduceTask任務A需要再次從所有mapTask下載到的對應檔案重新進行歸併排序
8、reduceTask的內部邏輯寫在reducer的reduce(key,values)方法,通過呼叫GroupingComparaor(key,netxtk)或者自定義GroupingComparaor來判斷哪些key是一組,形成key和values。
9、reducer的reduce方法最後通過context.writer(key,v)寫到輸出檔案(所有reduceTask的輸出檔案都有序),輸出路徑由提交任務時的引數決定,預設檔名part-r-00000
10、如果設定了combiner,那麼溢寫排序檔案會呼叫,歸併排序時也會combiner,將加快shluffer的效率,但是一般情況下不建議使用,如果符合條件下一定要使用,也可以直接指定reducer為combiner,沒必要重複寫程