
隨機森林演算法原理小結
來自:https://www.cnblogs.com/pinard/p/6156009.html
整合學習有兩個流派,一個是boosting,特點是各個弱學習器之間有依賴關係;一個是bagging,特點是各個弱學習器之間沒依賴關係,可以並行擬合。
1. bagging的原理
在整合學習原理總結中,給出bagging的原理圖。
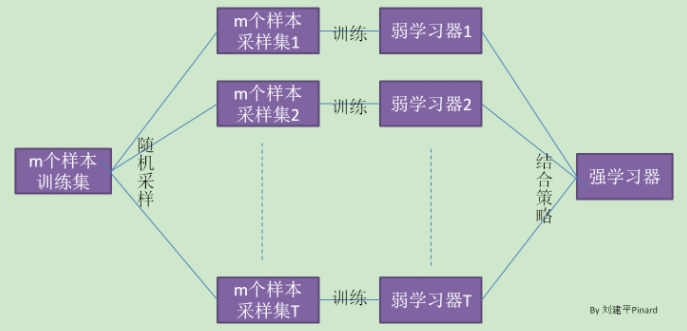
Bagging的弱學習器之間沒boosting那樣的聯絡。它的特點在“隨機取樣”。
隨機取樣常見的是自助隨機取樣,即有放回的隨機取樣。Bagging演算法,一般會隨機採集和訓練集樣本數m一樣的個數的樣本。這樣得到的取樣集和訓練集樣本個數相同,但樣本內容不同。我們對m個樣本訓練集做T次的隨機取樣,則由於隨機性,T個取樣集各不相同。
注意到這和GBDT的子取樣不同。GBDT的子取樣是無放回取樣,而Bagging的子取樣是放回取樣。
對於一個樣本,它在某一次含m個樣本的訓練集的隨機取樣中,每次被採集到的概率是1/m。
樣本在m次取樣中始終不被採到的概率是:
P(一次都未被採集) = (1-1/m)m
對m取極限得到:
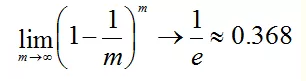
也就是說bagging的每輪隨機取樣中,訓練集大約有36.8%的資料沒被採集。
對於大約36.8%沒被取樣的資料,稱為“袋外資料”。這些資料沒參與訓練集模型的擬合,但可以作為測試集用於測試模型的泛化能力,這樣的測試結果稱為“外包估計”。
bagging對於弱學習器沒有限制,這和Adaboost一樣。但是最常用的一般也是決策樹和神經網路。
bagging的集合策略也比較簡單,對於分類問題,通常使用簡單投票法,得到最多票數的類別或者類別之一為最終的模型輸出。對於迴歸問題,通常使用簡單平均法,對T個弱學習器得到的迴歸結果進行算術平均得到最終的模型輸出。
由於Bagging演算法每次都進行取樣來訓練模型,因此泛化能力很強,對於降低模型的方差很有作用。當然對於訓練集的擬合程度就會差一些,也就是模型的偏倚會大一些。