
吳恩達《深度學習》第二課第一週筆記
一、訓練、開發、測試集
1. 可應用的機器學習演算法是一個高度迭代的過程,需要不斷調整的引數有:層數、隱藏層神經元數、學習速率、啟用函式等等。
2. 通常將給定的資料劃分為三部分:訓練、驗證、測試。如果資料集較小:60/20/20, 如果是大資料集(100萬條資料以上,驗證和測試集各分配1萬條即可):98/1/1.
3.如果訓練集與驗證、測試集來源不同,應保證它們處於同一分佈。
二、偏差/方差
1. 模型的偏差和方差要儘可能的綜合考慮,在高偏差情況下會出現欠擬合問題,而方差偏高情況會導致過擬合問題。
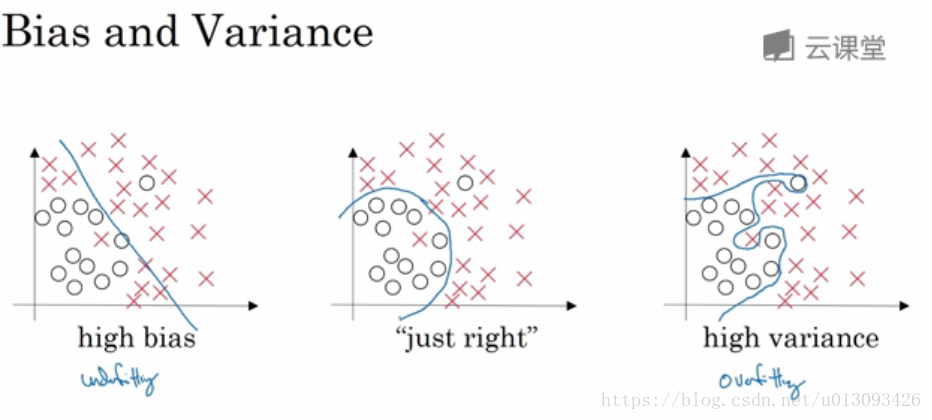
| 高方差(過擬合) | 高偏差 | 高方差和高偏差 | 低方差和低偏差 | |
| 訓練集誤差 | 1% | 15% | 15% | 0.5% |
| 驗證集誤差 | 11% | 16% | 30% | 1% |
但是當訓練驗證集的誤差接近最優誤差(亦稱貝葉斯誤差)時,那麼也是可以接受的。比如bayers error = 15%,那麼上表的第二個案例便是很合理的。
三、機器學習基礎
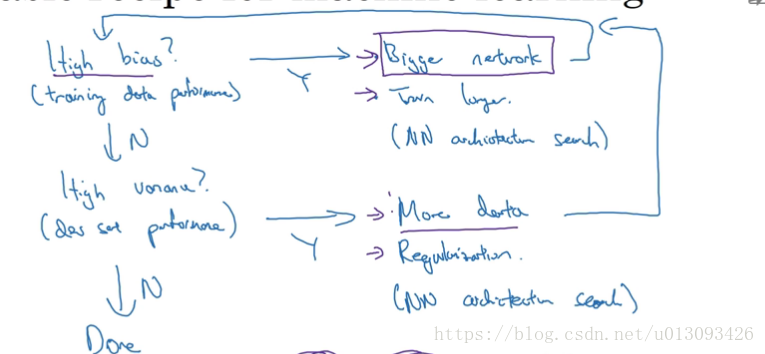
1.由訓練集誤差和驗證集誤差判斷偏差和方差的大小,以系統的優化演算法效能。
四、正則化
1.遇到高方差問題時首先需想到的是正則化
2.正則化的原理:
(1)對於邏輯迴歸,L2正則化是最常見的形式。缺點:需要不斷的嘗試不同的lambd值,導致計算量加大。
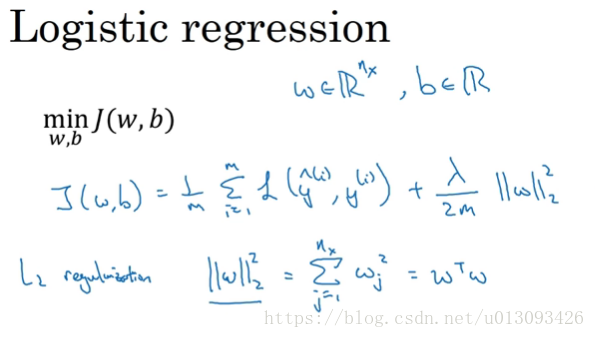
另一種常見的正則化是L1正則化,其通常比較稀疏即包含很多0,形式如下:
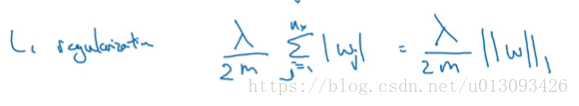
(2)對於神經網路,常採用F範數(弗羅貝尼烏斯範數),其實質也是L2範數。
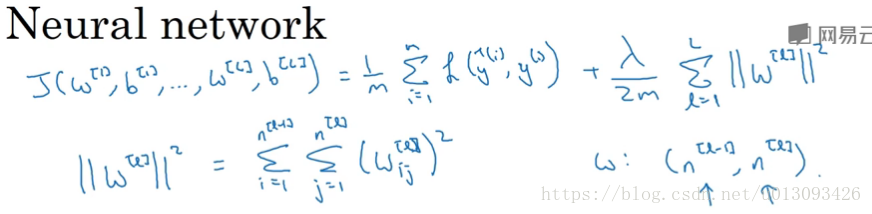
增加的L2範數正則化有時也稱之為權重衰減,因為給W[l]引入了一個小於1的權重(1-alpha*lambd/m)

五、為什麼正則化有利於防止過擬合(減小方差)
1.直觀理解(一):通過正則化引入的lambd可以避免權重過大,甚至可以讓W壓縮至0,這就可以理解為複雜的神經網路中一些中間層神經元被設定成了0,即變成了邏輯迴歸模型。
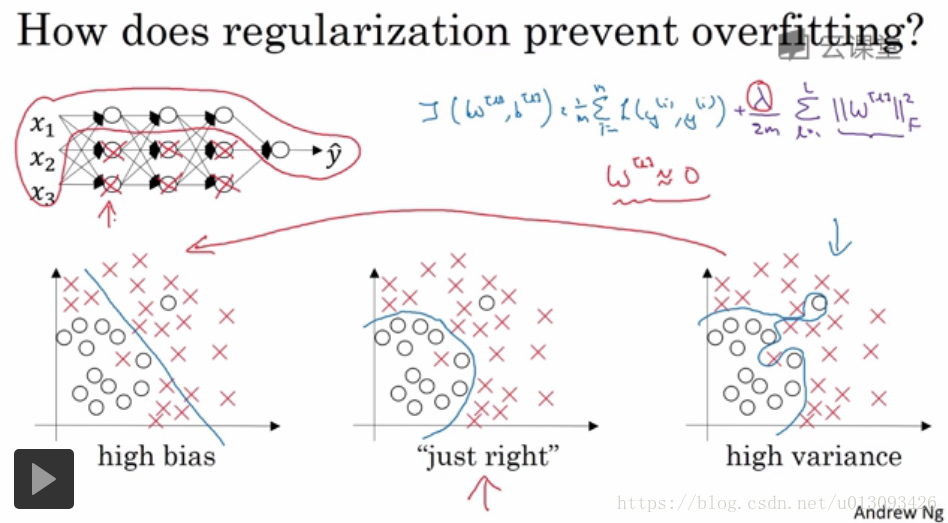
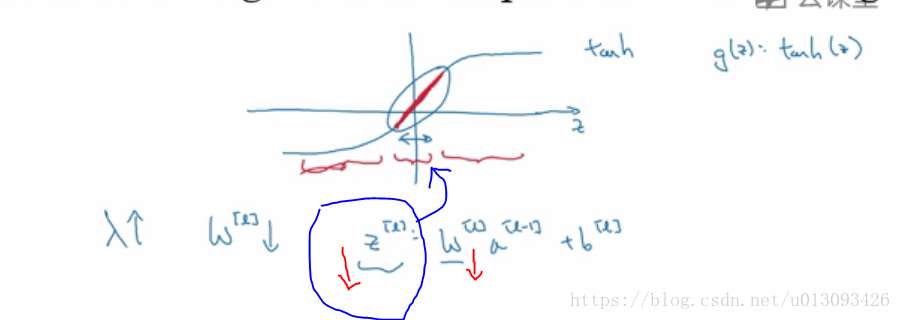
2.直觀理解(二),如果Z的取值範圍很小,那麼相當於深度神經網路的每一層只引入了tanh()的線性部分,這樣簡化了網路結構,就防止出現過擬合了。
六、dropout正則化(隨機失活)
1.dropout處理流程:以擲硬幣的方式(0.5的概率)決定每個節點是否被剔除,以達到精簡網路結構,這樣便可以防止過擬合的發生。
2.實施dropout的方法,最常用的方法是inverted dropout 反向隨即失活

3.在預測階段不要使用dropout
七、理解dropout
1.直觀認識:
(1)使用dropout每次迭代後神經網路結構會縮小,這和使用正則化直觀感覺類似。
(2)由於dropout是隨即的刪除某個節點的輸入節點,因此在給各個輸入節點分配權重時可避免大權重的出現(因為可能在某次迭代中被刪掉),這樣最終的結果會和L2範數一樣起到縮減權重的效果,而且更適用於不用的取值範圍。
2.不同層可以選擇不用大小的keep_prob值,對於複雜的權重Wkeep_prob值應較小,這樣可以更加弱化兩層之間的擬合。而對於節點很少的層則可不使用dropout(將keep_prob設定為1)
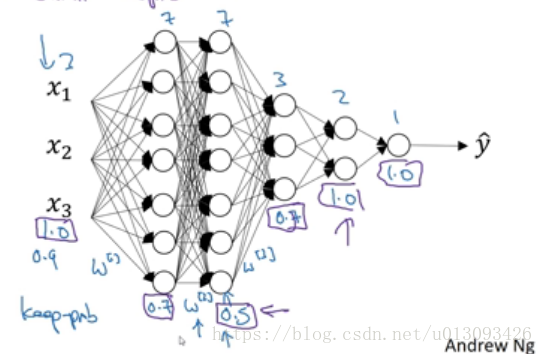
3.在計算機視覺中應用dropout很多,因為很多輸入資料且常有無用資料,而在其他場景中應用較少。
4.缺點:cost function不能被明確定義,因為每次隨即失活節點。因此在使用時,可以先去除dropout畫出J的迭代曲線,執行無誤後再加入dropout
八、其他正則化方法
1.擴大資料(水平翻轉影象,裁剪,扭曲(如對數字))
2.early stopping(提前結束神經網路的迭代過程),也就是說在dev error和J accuracy滿足後就停止下來,這樣W就不會被迭代的過於複雜。缺點:正交化很差。因為提早結束訓練J(W,b)會使W不夠小,這樣J就不夠小。優點:不需要像L2正則化那樣,不斷調整超引數lambd,只需要一次梯度下降即可。
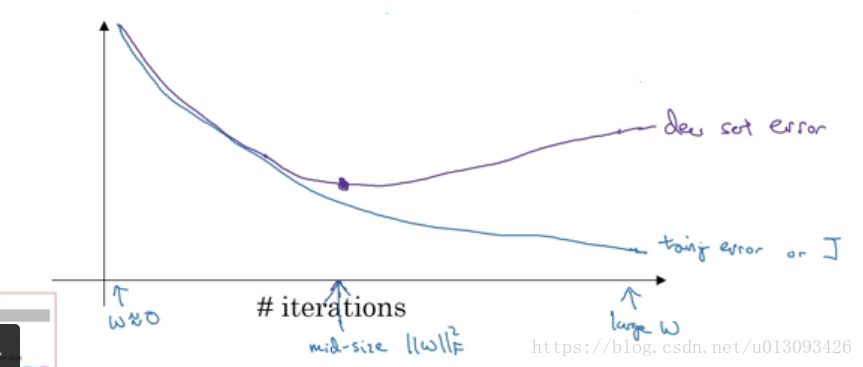
3.神經網路兩個關鍵步驟:(1)優化損失函式J(W,b);(2)防止過擬合(overfitting)
4.正交化:如果處理(1)時的效果不影響(2),在處理(2)時也不影響(1),這個原則稱為正交化
九、提升網路訓練速度方法一:正則化輸入(歸一化)
1.步驟:
(1)零均值化:Mu = np.sum(x[i]) / m x[i] -= Mu
(2)歸一化方差: sigma**2 = np.sum(x[i] ** 2) / m x[i] /= sigma
2.好處:使輸入的各個特徵都在同一取值區間,輸入更規整,可以使J優化起來更快速找到極值點
十、梯度消失或梯度爆炸
1.梯度消失或梯度爆炸的理解
在深層神經網路中,由於W中的值大於或小於1,導致網路中一些與W[L]相關的函式(J,導數,梯度等)以指數級的速度進行增或減,這樣情況稱為梯度消失或梯度爆炸,這個給神經網路的訓練帶來很大困難。
十一、提升網路訓練速度方法二:權重初始化
1. 目的:謹慎的選擇隨即初始化引數,解決梯度消失或梯度爆炸問題
2.實現:
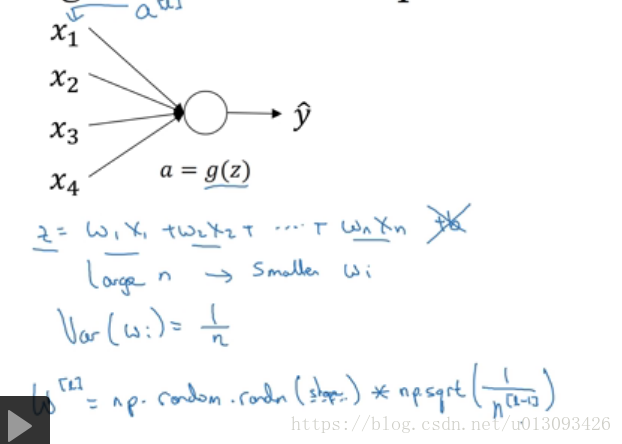
如果啟用函式使用的是relu

如果啟用函式為tanh
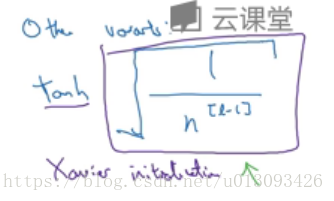
3.改進:
如果想引入方差,則只需在np.sqrt(2/n[l-1])中引入方差係數。
十二、梯度的數值逼近(確保梯度下降正確執行(一))
1.實質:正確實施偏導數計算
十三、梯度檢驗
1.目的:檢驗梯度下降是否正確實施

十四、梯度檢驗實現
1.提示:
(1)不要在訓練神經網路時使用梯度檢驗,這隻適用於除錯中
(2)如果梯度檢驗失敗,需要檢查問題處在哪一層,逐一檢查該層的各個組成元素
(3)記得正則化
(4)不能使用dropout(如果演算法中使用了dropout,需先關閉且程式執行正確後在梯度檢驗)