
[機器學習筆記]Note16--應用示例:影象文字識別
繼續是機器學習課程的筆記,本節課是最後一節內容了,主要是介紹一個應該–圖中文字的識別。
問題描述和流程圖
影象文字識別應用就是從給定的圖片中識別文字。這比從一份掃描文件中識別文字要複雜得多。一個例子圖片如下所示:

為了完成這樣的工作,需要採取如下步驟:
- 文字檢測(Text detection)——將圖片上的文字和其他環境物件分離開來
- 字元切分(Character segmentation)——將文字分割成一個個單一的字元
- 字元分類(Character classification)——確定每一個字元是什麼
可以用一個任務流程圖來表達這個問題,每一項任務可以由一個單獨的小隊來負責解決,如下所示,這也就是一個流水線的概念了。

滑動視窗
滑動視窗是一項用來從影象中抽取物件的技術。
假設我們需要在一張圖片中識別行人,首先要做的就是用許多固定尺寸的圖片來訓練一個能夠準確識別行人的模型。然後我們以之前訓練識別行人的模型時所採用的圖片尺寸在我們要進行行人識別的圖片上進行剪裁,然後將剪裁得到的切片交給模型,讓模型判斷是否為行人,然後在圖片上滑動剪裁區域重新進行剪裁,將新剪裁的切片也交給模型進行判斷,如此迴圈直至將圖片全部檢測完。
一旦完成後,我們按比例放大剪裁的區域,再以新的尺寸對圖片進行剪裁,將新剪裁的切片按比例縮小至模型所採納的尺寸,交給模型進行判斷,如此迴圈。

滑動視窗技術也被用於文字識別,首先訓練模型能夠區分字元與非字元,然後,運用滑動視窗技術識別字符,一旦完成了字元的識別,我們將識別得出的區域進行一些擴充套件,然後將重疊的區域進行合併。接著我們以寬高比作為過濾條件,過濾掉高度比寬度更大的區域(認為單詞的長度通常比高度要大)。下圖中綠色的區域是經過這些步驟後被認為是文字的區域,而紅色的區域是被忽略的。
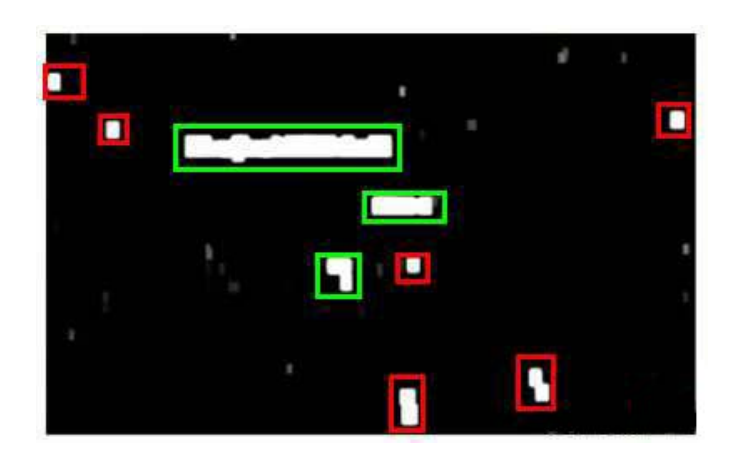
以上就是文字檢測階段。
下一步就是訓練一個模型來完成字元分割的任務,需要的訓練集由單個字元的圖片和兩個相連字元之間的圖片來訓練模型。如下所示:
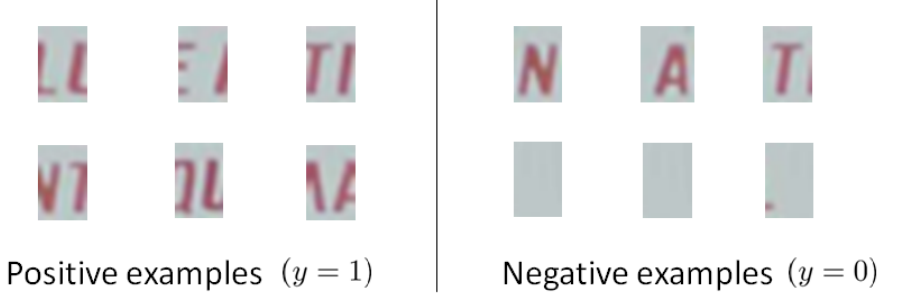
模型訓練完後,我們仍然是使用滑動視窗技術來進行文字識別,如下所示。

這就是字元切割的階段了。
最後就是進行字元分類的步驟。這裡可以使用如神經網路、SVM或者邏輯迴歸演算法訓練一個分類器即可。
獲得大量資料
如果我們的模型是過擬合的,那麼獲得更多的資料用於訓練模型,是能夠有更好的效果的。問題是我們怎麼獲得資料,資料不總是可以直接獲得的,有可能還需要人工地創造一些資料。
以我們的文字識別應用為例,我們在字型網站下載各種字型,然後利用這些不同的字型配上各種不同的隨機背景圖片創造出一些用於訓練的例項,這讓我們能夠獲得一個無限大的訓練集。這是從零開始創造例項
另一種方法是,利用已有的資料,然後對其進行修改,如將已有的字元圖片進行一些扭曲、旋轉、模糊處理。只有我們認為實際資料有可能和經過這樣處理後的資料類似,我們便可以同這樣的方法來創造大量的資料。
有關獲得更多資料的幾種方法:
- 人工資料合成
- 手動收集、標記資料
- 眾包
上限分析
在機器學習的應用中,我們通常需要通過幾個步驟才能進行最終的預測,我們如何能夠知道哪一部分最值得我們花時間和精力去改善呢?這個問題可以通過上限分析來回答。
回到我們的文字識別應用中,我們的流程圖如下:
![此處輸入圖片的描述][2]
流程圖中每一部分的輸出都是下一部分的輸入,上限分析中,我們選取一部分,手工提供100%正確的輸出結果,然後看應用的整理效果提升了多少。
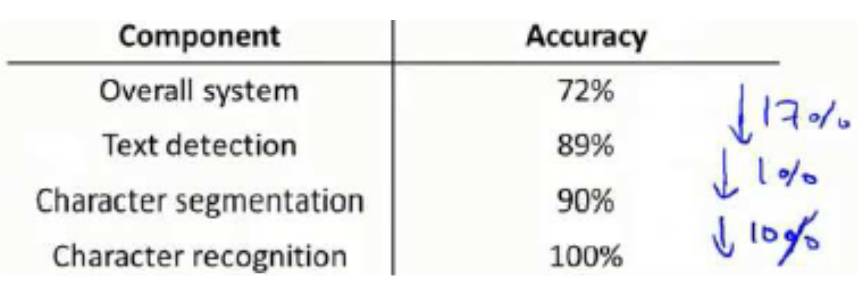
假設我們的例子中總體效果是72%的正確率。
如果我們令文字偵測部分輸出的結果100%正確,發現系統的總體效果從72%提高到了89%。這意味著我們很可能會希望投入時間精力來提高我們的文字偵測部分。
接著我們手動選擇資料,讓字元切分輸出的結果100%正確,發現系統的總體效果只提升了1%,這意味著,我們的字元切分部分可能已經足夠好了。
最後我們手工選擇資料,讓字元分類輸出的結果 100%正確,系統的總體效果又提升了10%,這意味著我們可能也會應該投入更多的時間和精力來提高應用的總體表現。
小結
最後一節課內容介紹了一個機器學習的應用示例–影象文字的識別,同時講了滑動視窗技術以及如何獲得資料,最後就是介紹了上限分析來確定需要集中時間和精力解決的步驟是哪一步。