
【卷積神經網路】Lesson 3--目標檢測
課程來源:吳恩達 深度學習課程 《卷積神經網路》
筆記整理:王小草
時間:2018年6月8日
1.目標定位Object localization
1.1 什麼是目標定位
明確下目標定位與檢測的定義。
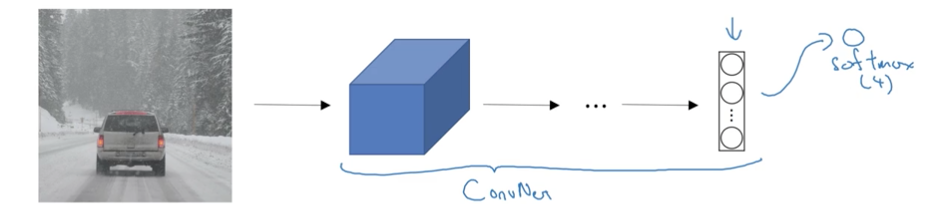
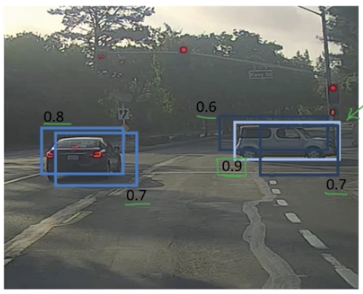
識別一張圖片的型別(比如貓狗分類)叫做影象分類image classification,比如下面這張圖篇是分類到汽車:

不僅識別出圖片的型別,還將目標物體的位置標出來叫做分類定位classification with localization

檢測出圖片中所有目標物體中的位置叫做目標檢測detection
比如給出一張交通圖片,檢測並標記出裡面的車輛,行人,自行車,交通燈等等。(注意,detection與classification with localization的不同在於單張圖片中有不同分類的物件)

本節要講述的是以上第二種情況,即給圖片分類,並定位和標記出出目標物體的位置
1.2 定位方法的介紹
標準的影象分類問題,假如如下輸入一張圖片,通過卷積神經網路卷啊卷,最後經過softmax層,分成4類:行人,汽車,摩托車,啥都沒有
如果你還想定點陣圖片中汽車的位置,該咋辦呢?你可以讓上面這個神經網路再多加幾個輸出,輸出汽車的邊框。
汽車的邊框資訊只需要4個數字來表示:b_x,b_y,b_h,b_w,分別表示邊框的中心點的橫坐、,縱座標,邊框的高,邊框的寬。
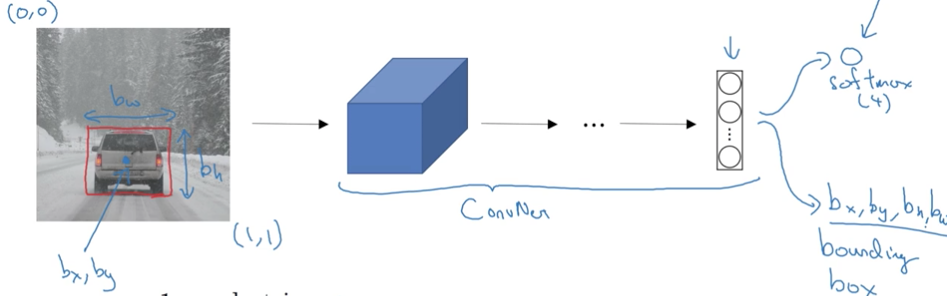
因此在標註訓練資料時,除了給出類別的標籤,還要給出表示邊框的4個數字。然後通過有監督的訓練模型,輸出一個分類標籤和四個邊框引數值。
1.3 符號約定
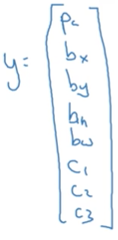
(1)定義標籤y
y是8*1的向量(注意這裡我們只限定講解影象中只有一個目標物體的情況)。
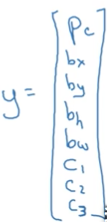
Pc表示概率:是否有目標物體,若有車輛,摩托車,行人目標物體,則Pc=1,若這三個都沒有則Pc=0;
bx,by,bh,bw分別表示目標物體邊框的中心點橫縱座標與高寬
c1,c2,c3分別表示當Pc=1時,圖片屬於車輛,摩托車,行人的類別的概率。
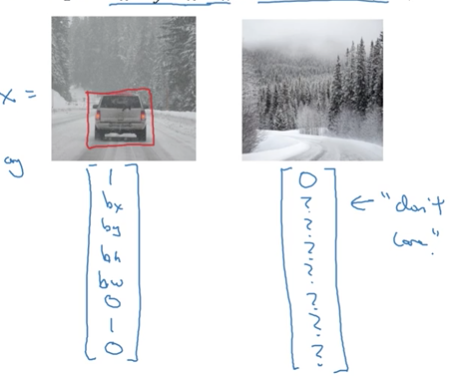
因此上面這個例子的標籤y可以寫成圖左,而什麼都沒檢測到可以寫成圖右。
(2)定義損失函式
分別將y向量中的8個元素寫成y1,y2,…,y8,其中Pc=y1,以此類推。
對於單個樣本的損失:
當y1=1時,就是這把個元素對應的平方差損失之和;
當y1=0時,就只是y1的平方差,後面7個元素都不用考慮
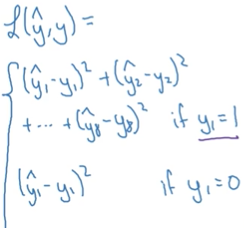
在實際中,也可以不這樣定義,可以將y1的輸出用邏輯迴歸的損失函式定義,bx,by,bh,bw的輸出用平方差和來定義,而c1,c2,c3用softmax的Log損失來定義.
2.特徵點檢測Landmark detection
神經網路可以通過對特徵點(x,y)的輸出來識別目標特徵。來舉2個例子。
例子1:
假設要識別人臉左眼角的特徵點,則只需要讓神經網路的最後一層輸出(Pc,lx,ly)3個值即可,Pc表示是否是人臉,lx,ly是人臉上眼角的座標點。

假設想定位兩隻眼睛的4個眼角的位置,那就將輸出改為4組座標對應的數字(l1_x,l1_y),…,(l4_x,l4_y)

假設想定位兩隻眼睛的一圈,則可能需要10幾個特徵點,同樣,將輸出增加到10幾座標即可,這樣就可以識別出人臉上眼睛的形狀等特徵從而做一些後續的判斷。同理,可以輸出臉部的更多特徵點,比如嘴脣,從而可以根據這些特徵點預測任務的表情,是傷心還是開心。

假設總共有128個特徵點,則輸出有129維,y={Pc, l1_x,l1_y,…l128_x,l128_y}
通過特徵點檢測,想想我們平時用的美顏相機(哦,對了,筆者是女生),可以在臉上頭上加一些裝飾,比如貓鬍子啊,皇冠啊,帽子啊,髮飾啊,並且無論怎麼動都能加在正確的位置上,者也是用了特徵檢測,檢測出某些特徵點的位置,然後將這些額外的裝飾新增在對應的特徵點位置上。
例子2:
若將身體的關鍵點作為特徵點,則可以識別任務的動作與形態:

3.目標檢測object detection
目標檢測實則分為兩步。
假設要檢測圖片中所有汽車
第一步:圖片分類
先收集圖片,將有汽車的圖片中的汽車挖出來作為圖片的中心,然後進行標記汽車與非汽車,並利用卷積神經網路學習出汽車分類模型。

第二步:滑動視窗檢測
設定一個指定大小的視窗,從圖片的左上角開始,以指定的步長進行從左往右,從上往下的滑動,每滑動一次,都將視窗內的影象截取出來,輸出第一步訓練好的分類模型中預測是否是汽車,若是,則輸出該視窗當前的左邊資訊,若不是,則繼續滑動尋找。


若滑動完所有區域還是沒有找到汽車,則將視窗增大一點點,繼續從新滑動尋找。

這樣做的缺點很明顯:每滑動一次都要用神經網路預測一次,計算量非常大。
4.滑動視窗的卷積實現
上一節講了通過視窗滑動來進行目標檢測,但效率低計算量大,本節來講一講如何在卷積上實現視窗滑動,從而提升效率與速度。
來自論文[Sermanet et al.2014,Overfeat:Integrated recognition, location and detection using convolutional network]
4.1 將全連線層轉變為卷積層
首先了解一下如何將全連線層轉變為卷積層,接下去的滑動視窗的實現會用到它。
傳統的影象分類結構如下,輸入圖片,經過卷積和池化,然後經過全連線層和softmax層,最終預測分類類別的概率。

將最後兩層的全連線層修改為卷積層。將第二層的輸出556經過400個556的卷積核,得到11400的輸出,代替原來的全連線層的輸出400,同理第二個全連線層也改成經過400個11400的卷積核,得到11400的輸出,將最後的全連線層也改成經過4個11400的卷積核,得到114的輸出。

於是後面3層的全連線都變成了卷積層的模式。
4.2 滑動視窗的卷積實現
將上面全連線轉變成卷積層後的如下顯示(注意,其實是立體的,只是為了方便直觀理解接下去的講解,現在以平面的視角展示)

假設我們已經訓練好上面這個4分類的模型了。
現在給出一張16163的圖片,滑動視窗的大小為14143。
以傳統的做法:滑動視窗以2個畫素的步長進行從左到右,從上到下的滑動,會得到4張截圖,分別依次輸給分類卷積神經網路進行預測,得到分類的類別。總共做了4次卷積預測,但這樣當圖片很大,滑動視窗又比較小的時候,會帶來巨大計算量
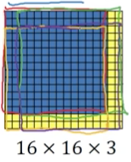
實際上,4次卷積操作中有很多計算都是重複的。
我們將16163的圖片也同樣進行如上卷積,與11400對應的,會有22400的輸出結果。在最終輸出的4個自放款中,左上角藍色那一塊實則對應了左上角14143的藍色區域。
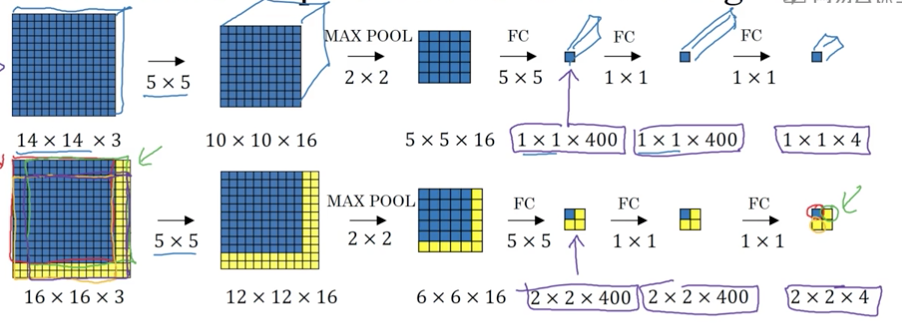
因此,實際上,無需通過滑動視窗依次取出截圖去執行前向傳播進行分類預測,只需要直接將原影象進行卷積,其中的共有區域可以共享很多計算。
也就是說,給出一張圖片,比如汽車:

無需滑動n次,並進行n次分類預測,而是直接把整張圖片進行卷積後,一次性得到每個區域的分類結果。
5.Bounding box預測
5.1 yolo演算法
上一節的方法大大降低了目標檢測的計算量,但仍有缺陷:檢測的邊框不夠精確。本節來解決邊框預測不精確的問題。
很多時候,視窗無論怎麼滑動都取不到完整的目標物體:

要解決這個問題,常用的解決辦法是yolo演算法,優點是隻要看一次。
來自論文[Redmon et al.,2015, You Only Look Once:Unified real-time object detection]
給出一張100100的圖片,為了方便講解,此處粗粒度地分為33的格子。
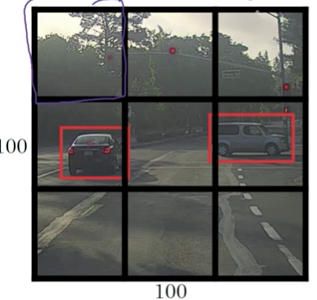
一般情況下,對每個格子對應的影象進行分類預測,分類的方式與第1節講述的一樣,因此在訓練資料中藥現將每個格子都進行標記:
因此,對於最左上角的格子,什麼東東都沒有,得標記成:

而有大部分車體的兩個格子(yolo演算法將物體的中心點所在的格子算作是有該物體的格子)的標記為:
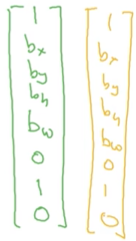
因為有33個格子,且每個格子的預測label向量有8個元素,總共輸出的吃春是33*8.
yolo的整個過程是,輸入圖片1001003,若以33的根子為劃分,經過卷積神經網路,輸出338
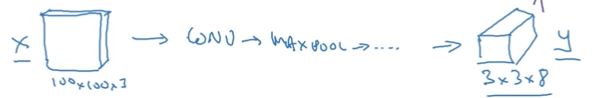
若一個格子中存在多個物件,我們稍後討論。但在實踐中一般會用更小的格子網路,比如1919,那麼多個物件分配到同一個格子上的概率就會小很多
yolo的優點:
(1)輸出更精確的座標,不收滑動窗法分類器的步長限制
(2)使用卷積實現的過程,可以一次性得到結果
3.2 如何編碼邊框座標
在yolo演算法中,每個格子的左上角是(0,0),右下角是(1,1),以下圖右車為例:
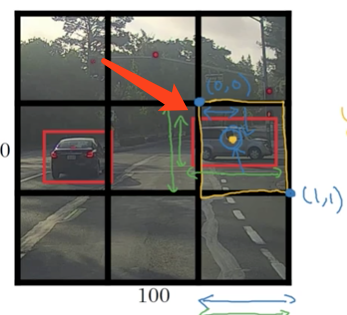
車的中線點座標為(0.4,0.3),即bx=0.4,by=0.3
寬和高是相對於格子的百分比,車子的寬大概佔了格子寬的90%,因此bw = 0.9,車子的高佔了格子的50%,則bh = 0.5
其中bx,by肯定是0-1之間的座標,因此其值在0-1之間;
而bw,bh可能超過1,因為可能車子的長度超過了格子長度,有一部分跑到了另一個格子去。
6.交併化Intersection over union
如何判斷物件檢測演算法運作良好呢?我們可以使用並交比函式來評價物件檢測演算法。
假設下圖,紅框是正確的檢測邊框,紫框是模型預測出來的檢測邊框

要評價模型預測的效果,就用兩者相交的面積/兩者相併的面積,這個佔比就是交併化函式輸出的指標,在0-1之間,一般指定一個閥值0.5,若佔比>=0.5則模型的預測是可以接受的。當然嚴格一點的話,你也可以提高閥值。
7.非極大值抑制Non-max suppression
Non-max suppression可以有效保證在影象中只對物體檢測一次,避免重複檢測加大計算量。
假設用Yolo演算法,把影象分成19*19的網格,這兩輛車只會屬於其中心點所在的網格,但是實際上車子覆蓋的其他網格,也都會去想我這裡是不是一輛車,造成了重複計算。

直觀得來了解下Non-max suppression是如何起作用的。
首先會有多個框框檢測出自己裡面都有汽車,每個框框都會得到一個並交比係數;
對於同一個目標物體的多個框框,比較它們的並交比,選出最大的那個框框顏色加深,將其他的比值小的框框都減弱顏色使其變暗,最終目標物體會得到1個較好的邊框。
深入得來理解下Non-max suppression的演算法過程
仍然將影象分割成19*19的網格:

假設只識別汽車這一個類別,每個網格的輸出就是:
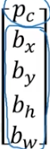
1.首先拋棄掉pc<=0.6的box
2.對剩下的boxs(邊界框):
- 選擇pc最大的那個輸出作為預測值
- 將剩下的pc與預測值相同,IoU >= 0.5 的box拋棄掉
直到每個box都被判斷過,它們有的作為輸出結果,剩下的和輸出結果重疊面積太高的會被拋棄掉。
若同一張圖片中檢測n個目標物,則要對每個物體都進行以上步驟。
8.Anchor Boxes
以上所有,有個缺點,就是每個網格只能檢測出一個物件。如果想讓一個格子能檢測出多個物件,那麼久可以用Anchor Boxes。
假設這樣一張圖片:

人和車重疊,其兩個物體的中心點都在同一個網格內,此時若還是用這樣的輸出:
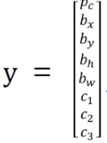
就不行了,因為一次只能輸出一個類別。
Anchor Boxes的做法是預先定義兩個不通過形狀的anchor box(實踐中可能會用更多個)
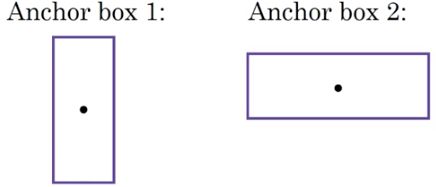
然後將預測結果將這兩個anchor box關聯起來。
重新定義標籤y:
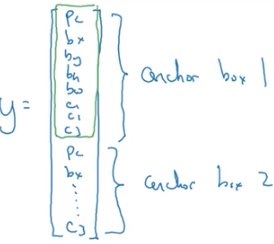
前面8個元素是針對行人的預測,後面8個元素是針對汽車的預測。
訓練的時候,不僅僅關注與標註的邊框一樣,還要關注預測的邊框與anchor box的並交比。
例子:
還是這張圖片:

預定義兩個Anchor Boxes

輸出標籤y的形式:
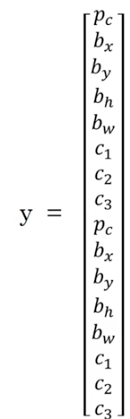
因此又有人又有車的網格的標籤應該是y:

若檢測到的邊框與Anchor Boxes1的並交比很大,則將預測值寫在y的上面8個元素,若與Anchor Boxes2的並交比較大,則將預測值輸出再y的下面8各元素,以此來區分檢測出來的邊框到底是人呢還是汽車。
若沒有人只有車,則y:

Anchor Boxes演算法有兩個缺點:
(1)當兩個目標物圖的邊框很相似或一樣的時候,就失效了,比如檢測電視機和電腦,都是差不多方方的形狀。
(2)當資料集中出現了3個目標物體,則失效了,需要重新定義模型,定義新的輸出y的形式才行了。
9.YOLO演算法
至此,我們已經講述了物件檢測演算法的大部分零件,這一節,將將所欲零件組裝構成完整的yolo物件檢測演算法。
9.1 構建訓練集
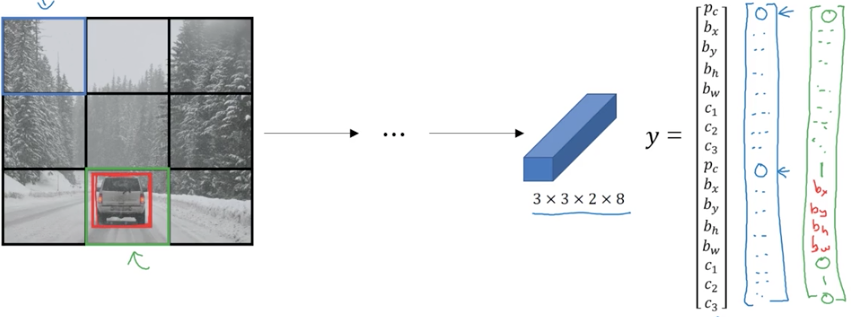
假設要檢測一張圖片中的3個類別:pedestrain, car, motocycle,分成33的網格(實踐中一般為1919)。

訓練集的標籤y為3328:(28分別是2個Anchor Boxes對應的類別)
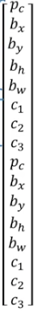
訓練集的特徵x是遍歷網格中的9個小格子,分別給他們都標記一個y.
其實這個圖片中只有1個格子裡有車,其餘8個格子裡都沒有車,因此沒有車的標記為
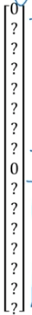
有車的標記為
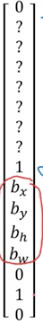
其中bx,by,bh,bw就是這輛車在該格子中的邊框
9.2 預測
因此向卷積神經網路中輸如影象為1001003,若分割成33的網格,則輸出的大小為33*16
###9.3 使用Non-max suppression
為了讓例子更有趣,我們用一張新的美女圖。

若使用2個anchor box,則針對每個網格都會輸出2個預測邊框,其中一個概率pc很低(注意,有些邊框可能會超出所在格子的寬度和高度)

接著,你要拋棄pc概率低的預測,得到這些剩下的邊框

然後,如果你有3個類別(行人,車,摩托車),則你要分別對這3個類別單獨進行Non-max suppression,執行3次來得到最終的預測結果
10 RPN網路Region proposals
10.1 R-CNN
如果你讀了物件檢測的論文,你會發現有一個概念叫Region proposals候選區域,在計算機視覺裡很有影響力。
迴歸上文的演算法(非yolo),會對一張圖片中的滑動視窗,都過一遍卷積神經網路,但問題是一張圖片中其實只有少量視窗有目標物體,其他吃昂口是完全沒有任何用的,因此對於完全沒有目標物體的視窗去計算也顯得耗時耗力。因此,論文[Girshik et,al,2013,Rich feature hierarchies for accurate object detection and semantic segmentation]提出了一種叫做R-CNN的演算法,即帶區域的卷積神經網,只是選擇某些有意義的視窗運行卷積神經網路進行預測。
執行影象分割演算法,得到如下結果:

然後將每個色塊作為一個整體跑一下分類器去進行檢測(加入有2000個色塊),因此上圖在藍色區域進行檢測,可能能檢測出一個人,淡藍色區域可能能檢測出一輛車
通過影象分割,從而針對性得對一些整體去檢測,比在影象的所有位置都跑一邊要大大減小計算量。
10.2 R-CNN的改進
R-CNN的速度還是不能使研究者們滿意,於是有了一系列研究工作對該演算法進行改進。
基本的R-CNN:
利用影象分割求出候選區域,對每個候選區域進行分類,輸出類別標籤和邊框。
Fast R-CNN:
[Cirshik,2015.Fast R-CNN]
與R-CNN的區別是,Fast R-CNN使用了滑動視窗的卷積實現來進行分類(本文第4節),而不是對每個視窗都進行分類。
Faster R-CNN:
[Ren et.al, 2016. Faster R-CNN: Toweards real-time object detection with region prposal network]
但Fast R-CNN還是有缺點,即影象分割的時候,色塊的聚類特別慢。於是另一個研究組提出了Faster R-CNN,利用卷急神經網路來獲取候選區域色塊。
但實際上,大部分更快的R-CNN,都還是比yolo演算法慢。