
分散式訊息處理Kafka入門
1、Apache Kafka 介紹
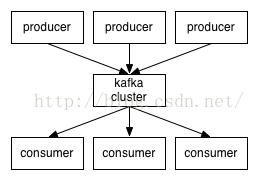
Kafka是一種快速、可擴充套件的、設計內在就是分散式的,分割槽的和可複製的提交日誌服務。從下是幾個常用術語。
Topics(主題),訊息流的存在形式。
Producers(生產者)
Consumers(消費者)
Broker(代理),Kafka叢集中可以包括一個或多個servers,每個server被稱為broker。
下圖是Kafka幾個角色的互動圖。消費者和生產者之間通過一種簡單、高效能且語言無關的TCP協議進行通訊。目前已經提供了基於多種開發語言的Kafka客戶端,詳見https://cwiki.apache.org/confluence/display/KAFKA/Clients。
主題和日誌Topics and Logs
1) Topic是傳送訊息的類別或名稱,kafka為每個topic維護一個分割槽的日誌,如下所示:
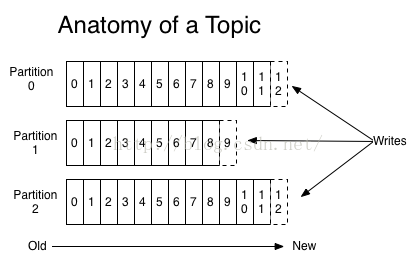
每個partition是持續新增的有序的不可變的訊息序列—a commit log 。partition內部的訊息都被分配唯一的Id number--offset 。
2) 無論是否消費,kafka在一段可配置時間內會保留所有提交的訊息。如設定2天,釋出後兩天內都可以消費,兩天後就會騰出空間。kafka的效能是恆定量,多保留些資料不是問題。
3) 每個消費者實際需要保留的元資料資訊是消費者處理log的位置-offset. offset由consumer來控制。通常隨著讀取messages,consumer會線性增長offset, 但實際上這個值由consumer控制,可以以喜歡的任何順序來消費,如可以設定成一個old offset,重新處理訊息。
4) 這些特性意味著kafka consumer可是做到非常輕量級,它們可以加入進來或剝離出去而基本上不會對其他consumer造成影響。(如我們可以用命令列tail等操作檢視任一個topic內容,而不會改變已經存在的consumer的消費行為).
以上這些特性的好處在於首先它允許日誌量超出單臺伺服器能力範疇,每個獨立的分割槽必須受限於執行它的server,但是一個topic卻可以有多個partition(這意味著可以持有任意數量的資料);其次,他們作為並行單元執行。
分散式Distribution
日誌分割槽被分散式得儲存到kafka叢集內的各個servers上,每個server只處理分割槽的一部分資料和訪問請求。每個分割槽都跨多servers的進行資料複製以實現容錯。每個Partition會有一個Leader,有0個或多個followers. leader處理這個partition的所有讀寫請求,followers被動的複製leader. 如果leader fails,其中一個followers自動成為leader.每個server都做一部分partition的leader和其他partition的follower,所以負載在叢集上是均勻的。
生產者Producers
Producers向topics傳送資料,每個producer負責選擇將訊息傳送給topic的哪個partition。這可以用輪詢的方式簡單的balance load,或者基於語義partition function(如根據訊息Key).
消費者Consumers
訊息有兩種傳統使用模式:佇列和釋出-訂閱。 佇列模式下,幾個消費者同時從訊息伺服器讀取資料時,訊息只會傳送到其中一個消費者;釋出訂閱模式中,訊息會廣播到所有消費者。Kafka提供了一種消費者的抽象——consumer group,可以同時實現以上兩種訊息使用模式。
消費者給自己命名一個consumer group 名稱,每個傳送給topic的訊息都被傳遞到consumer訂閱組的一個consumer例項中。consumer 例項可以是一臺機器上的不同獨立程序,也可以是不同機器上的程序。
如果所有的consumer instance都有相同的consumer group, 類似於傳統的queue,負載平均到consumers.
如果所有的consumer instance都有不同的consumer group, 類似於釋出-訂閱,訊息將被廣播到所有的consumers.
更常見的是,topics有少量的consumer group,每個邏輯訂閱組一個名字。每個組為了擴充套件性和容錯性由多個consumer instance組成。這超出了釋出訂閱模式語義,每個訂閱者是consumer群,不是單個程序。
kafka比常見的訊息系統提供了更強的排序保證。
傳統佇列系統,並行consumer會讓本來有序的佇列,訊息處理順序被打亂。如果要繼續保證訊息佇列的有序性,那麼只能通過“獨佔性消費者”模式來實現,而這又失去了並行處理特性。Kafka在這一點上面做得更出色,它可以保證順序和並行處理能力。通過分配partitions給consumer group中的consumers,並保證每個partition是由consumer group中的一個consumer消費。(這樣保證一個consumer是一個指定partiton的唯一reader且是按順序消費資料。因為會劃分出很多分割槽,所以還是能平衡負載。需要注意的是,在consumer grup中的consumer instances的數量不能多於partitions的數量.)
當然Kafka只提供了分割槽內部的訊息有序性,不能跨一個topic的多個partitions. 結合每個partition內部訊息資料的有序性和按Key劃分多partitions的能力,對大多數應用都夠用了。
然而,如果你的應用需要的是一個基於全部訊息資料的完全的有序佇列,也可以通過一種特殊的方式來達到目的。即為一個topic只劃分一個partition,且在consumer group中只能有一個consumer程序。
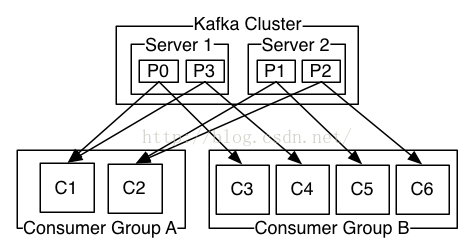
A two serverKafka cluster hosting four partitions (P0-P3) with two consumer groups.Consumer group A has two consumer instances and group B has four.
Guarantees
(1)一個生產者向指定topic的一個partition傳送的訊息,將會被按訊息的傳送順序追加到佇列中。因此對於一個生產者先後傳送的訊息M1和M2,M1會比M2有一個更小的 offset,並且會更早的出現在日誌中。
(2)一個consumer instance看到的訊息順序與它們在Log中儲存的順序相同。
(3)對於一個複製因子為N的topic,可以容忍N-1 server宕機不丟失資料。
2、使用場景 Use Cases
Kafka的常見使用場景。
訊息佇列 Messaging
Kafka可以用來平滑替換傳統訊息中介軟體,訊息中介軟體一般是用於解耦生產者消費者和快取未處理訊息等。kafka與以往的訊息中介軟體相比有更大的吞吐量、內建的分割槽和分割槽複製機制、容錯機制,所以更適合做大型訊息處理應用的解決方案。
根據以往使用kafka的經驗看,常見的場景是——吞吐量並不高,但需要端到端低延遲且嚴格的資料持久化保證。
網站活動跟蹤 Website Activity Tracking
(1)kafka的原始用途:通過重建使用者跟蹤管道為一組實時的釋出-訂閱feeds。這意味著網站活動(pv,search,使用者的其他活動)根據型別被髮布到中心topics(每個activity一個topic). 這些feed廣泛用於大量用例的訂閱包括實時處理、實時監控、load to hadoop或者離線資料倉庫為離線處理和報告。
(2)活動跟蹤需要高吞吐量,因為需要為每個user page view都生成許多的活動訊息。
Metrics 度量.
kafka經常用於處理監控資料,如從分散式的應用聚合統計資料以生成這些監控資料的集中式的訂閱源(feeds)。
Log aggregation日誌聚合
日誌聚合工具會將物理的日誌檔案從分散的多個主機上收集過來,並放入一個集中的位置(如file server/hdfs),以便於後續處理。
Kafka對各種日誌檔案的各種細節進行了抽象化處理,然後針對日誌資料或事件資料提供了一個更乾淨、一致的訊息流。Kafka提供了低延遲處理、易於支援多個數據源和分散式的資料處理(消費)的特性。相比於中心化的日誌聚合系統,如scribe/flume,kafka可以在提供同樣效能的條件下,實現更強的持久化保證以及更低的端到端延遲。
Stream processing流處理
在一些使用場景中,使用者需要做階段性的資料處理。使用者會首先消費那些儲存在Kafka topics中原始資料,然後對資料進行聚合、豐富等加工,或者乾脆轉換成一種新的Kafka topics用於未來的進一步處理工作。例如:一個文章推薦的處理流可能從rss源抓取文章內容,然後釋出到一個文章的topic;下一階段的處理可能會對資料進行規範化或者把這個資料複製到一個內容清洗後新的文章topic;最後階段可能會嘗試對內容和使用者進行匹配的工作。這樣就在本來相互獨立的topics之上創建出了一個實時的資料流圖。Storm和Samza是比較流行的實現這類轉換的框架。
Event sourcing 事件溯源
事件溯源是一種應用設計模式,在這類應用中狀態改變會被記錄為一系列按時間排序的日誌記錄。Kafka支援非常大量的日誌資料,因此非常適合做這種型別應用的後端。
Commit Log
kafka可以做為分散式系統的一種外部日誌提交工具(external commit-log)。日誌系統能夠幫助在節點間複製資料,可以作為失敗節點恢復資料時的一種資料重新同步機制。Kafka的日誌壓縮功能也可以幫助這種用途提供支援。
3、快速入門 Quick Start
這一部分教程是假定你是剛剛接觸Kafka並且在你的測試環境中還沒有使用到Kafka和ZooKeeper。
Step1: 下載安裝包
>wget http://mirrors.cnnic.cn/apache/kafka/0.9.0.1/kafka_2.11-0.9.0.1.tgz
> tar -xzf kafka_2.11-0.9.0.1.tgz
> cd kafka_2.11-0.9.0.1
Step2: 啟動server
Kafka需要使用到ZooKeeper,所以你如果還沒有一個的話,可以暫時使用kafka提供的一個供測試使用的單節點ZooKeeper例項。
> bin/zookeeper-server-start.sh config/zookeeper.properties
接下來啟動Kafka server:
> bin/kafka-server-start.sh config/server.properties
Step3: 建立一個topic
建立一個名為”test”的topic,設定為一個分割槽、一個副本。
> bin/kafka-topics.sh --create --zookeeper localhost:2181--replication-factor 1 --partitions 1 --topic test
使用list命令檢視剛剛建立的topic:
> bin/kafka-topics.sh --list --zookeeper localhost:2181
test
此外也可以配置為當提交到不存在的topic時,broker自動建立該topic。
Step 4: 傳送訊息 Send somemessages
Kafka提供了命令列工具從檔案獲取輸入或者標準輸入 ,作為訊息傳送到kafka叢集,預設一行一個訊息。
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topictest
Step 5: 啟動一個消費者 Start aconsumer
Kafka提供了命令列工具,可以人佇列中取出訊息並輸出到終端螢幕上。
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test--from-beginning
這時,你就可以在傳送端輸入訊息,觀察消費端的輸出。
Step 6: 建立一個多節點的Kfaka叢集 Setting up a multi-broker cluster
我們接下來把這個單例項的kfaka變成一個三節點的叢集。
> cp config/server.properties config/server-1.properties
> cp config/server.properties config/server-2.properties
修改配置檔案如下:
config/server-1.properties:
broker.id=1
listeners=PLAINTEXT://:9093
port=9093
log.dir=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://:9094
port=9094
log.dir=/tmp/kafka-logs-2
broker.id是叢集中每個節點的唯名稱。同時我們必須修改每個broker例項使用的監聽埠和日誌名稱。因為在這個測試用例中,三個kafka broker節點都部署在一臺機器上。
啟動兩個新的kafka broker節點:
> bin/kafka-server-start.sh config/server-1.properties &
> bin/kafka-server-start.sh config/server-2.properties &
接下來建立一個新的topic,設定複製因子為3:
> bin/kafka-topics.sh --create --zookeeper localhost:2181--replication-factor 3 --partitions 1 --topic my-replicated-topic
檢視每個broker都在做些什麼:
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topicmy-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader:1 Replicas: 1,2,0 Isr: 1,2,0
注:如上所示,leader是處理所有訊息讀寫的節點。Replicas是所有資料冗餘複製節點的列表,無論這些節點是否可用都會顯示出來。Isr表示正在保持與leader資料同步的節點列表。我們可以看到在這個例子中,node1是這個topic唯一一個分割槽的leader節點。
我們繼續檢視前面建立的topic——test:
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topictest
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader:0 Replicas: 0 Isr: 0
果然,這個topic是位於server 0上面的。因為這個topic只有一個分割槽、複製因子為1且在建立時我們僅啟動了server0 。
向my-replicated-topic可寫幾條測試資料:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topicmy-replicated-topic
...
my test message 1
my test message 2
接下來是啟動一個消費者:
> bin/kafka-console-consumer.sh --zookeeper localhost:2181--from-beginning --topic my-replicated-topic
測試容錯性,殺掉server-1. (Leader):
> ps -ef | grep server-1.properties
Kill掉程序。
Kafka叢集的leadership自動進行了切換:
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topicmy-replicated-topic
繼續測試發、收訊息,服務仍然在正常執行。即使原來的leader節點已經當掉了。
Step 7: 使用Kafka Connect實現資料的匯入/匯出 Use Kafka Connect to import/export data
Kafka 0.9+增加了一個新的特性 Kafka Connect ,可以更方便的建立和管理資料流管道。它為Kafka和其它系統建立規模可擴充套件的、可信賴的流資料提供了一個簡單的模型,通過connectors 可以將大資料從其它系統匯入到Kafka中,也可以從Kafka中匯出到其它系統。Kafka Connect可以將完整的資料庫注入到Kafka的Topic中,或者將伺服器的系統監控指標註入到Kafka,然後像正常的Kafka流處理機制一樣進行資料流處理。而匯出工作則是將資料從Kafka Topic中匯出到其它資料儲存系統、查詢系統或者離線分析系統等,比如資料庫、Elastic Search 、 Apache Ignite 等。它包含兩個功能,資料整合和流處理。Kafka Connect則是為資料整合而生。
Kafka Connect特性包括:
n Kafka connector通用框架,提供統一的整合API
n 同時支援分散式模式和單機模式
n REST 介面,用來檢視和管理Kafka connectors
n 自動化的offset管理,開發人員不必擔心錯誤處理的影響
n 分散式、可擴充套件
n 流/批處理整合
Kafka已經成為處理大資料流的平臺標準, 成千上萬的公司在使用它 。程式設計師在構建它們的平臺的時候也遇到一些問題:Schema管理、容錯、並行化、資料延遲、分發擔保、運營與監控。這些棘手的問題都要程式設計師去處理,如果有一個統一的框架去完成這些事情,將可以大大減少程式設計師的工作量,因此Kafka 0.9中提供了這一特性,負責處理這些問題。
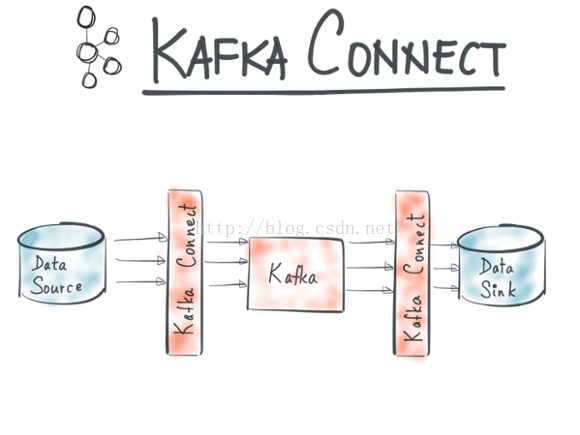
Kafka Connnect有兩個核心概念:Source和Sink。 Source負責匯入資料到Kafka,Sink負責從Kafka匯出資料,它們都被稱為Connector。Kafka背後的公司confluent鼓勵社群建立更多的開源的connector,將Kafka生態圈壯大起來,促進Kafka Connnect的應用。
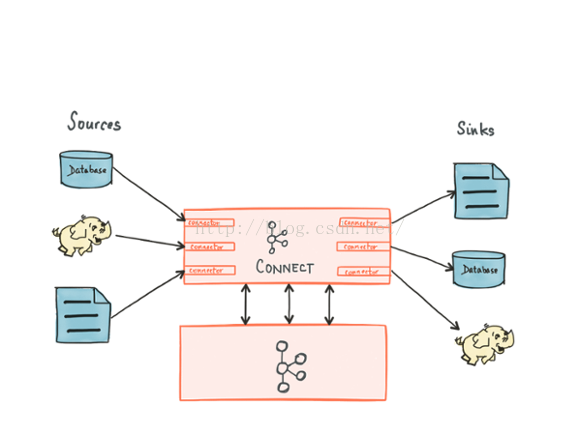
當前Kafka Connect支援兩種分發擔保:at least once (至少一次) 和 at most once(至多一次),exactly once將在未來支援。
當前已有的Connectors包括:
Connectors的釋出和開發可以參照 官方文件 。
我們接下來使用終端命令列工具對Kafka Connect做一個簡單的測試和演示:
1)建立一個用於測試的檔案
>cd /usr/local/kafka_2.11-0.9.0.1
> echo -e "foo\nbar" > test.txt
2)啟動兩個單例項模式的connector
>bin/connect-standalone.sh config/connect-standalone.propertiesconfig/connect-file-source.properties config/connect-file-sink.properties
在上面的三個引數中,
connect-standalone.properties,是Kafka Connect程序使用的配置檔案,通常包含需要連線的broker資訊和對資料進行序列化的格式配置;
connect-file-source.properties和connect-file-sink.properties,定義了兩個需要被創建出來的connector,包含connector name、使用到的工作類、topics的命名(這裡是取命為了connect-test)以及輸入輸出檔名等配置資訊。
3)測試connector管道
> echo "Another line" >> test.txt
向原始檔test.txt中追加寫入更多內容時,實時觀察另一個Connector的輸出檔案:
> tail -f test.sink.txt
4)我們也可以在終端上另啟動一個消費者來檢視在上面使用的topic中的訊息資料
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topicconnect-test --from-beginning
{"schema":{"type":"string","optional":false},"payload":"foo"}
{"schema":{"type":"string","optional":false},"payload":"bar"}
{"schema":{"type":"string","optional":false},"payload":"Anotherline"}
{"schema":{"type":"string","optional":false},"payload":"Anotherline 2."}
{"schema":{"type":"string","optional":false},"payload":"Anotherline 3."}
{"schema":{"type":"string","optional":false},"payload":"connectormessage test 1."}
{"schema":{"type":"string","optional":false},"payload":"connectormessage test 2."}
4、生態 Ecosystem
目錄已經有大量的主發行版之外的與kafka實現整合的工具。在Kafka生態系統頁列出了很多,包括:資料流系統、hadoop整合、監控、部署工具等。以下是主流的一部分kafka整合工具的列表。|
工具名稱 |
描述 |
備註 |
|
Kafka Connect |
Kafka has a built-in framework called Kafka Connect for writing sources and sinks that either continuously ingest data into Kafka or continuously ingest data in Kafka into external systems. The connectors themselves for different applications or data systems are federated and maintained separately from the main code base. You can find a list of them here. |
|
|
Stream Processing |
|
|
|
Hadoop Integration |
|
|
|
Search and Query |
|
|
|
Management Consoles |
|
|
|
Logging |
|