
機器學習-最近鄰(KNN,RNN)
最近鄰
概述
基於最近鄰的監督學習方法分兩類:分類,針對的是具有離散標籤的資料;迴歸,針對的是具有連續標籤的資料基於最近鄰的無監督學習方法用於聚類分析。
最近鄰方法原理是從訓練樣本中找到與查詢點在距離上最近的預定數量或範圍的多個點,然後依據這些點來預測查詢點的標籤。從訓練樣本中找出點的數量可以是使用者定義的常量,這叫ķ最近鄰學習即KNN,也可以通過使用者定義的查詢點的距離半徑範圍得出,這叫基於半徑的最近鄰學習即RNN。
資料之間的距離可以理解為資料之間的相似度。距離可以通過多種方式來度量,如歐幾里得距離,曼哈頓距離等。標準歐幾里得是最常見的選擇。
最近鄰學習方法稱為非泛化機器學習方法,因為只是簡單的“記住”了其所有的訓練資料,死記硬背下所有歷史資料,在新資料面前就與所有的歷史資料比較從而找出最相似的歷史資料。而泛化的機器學習方法在給定的樣本資料進行訓練之後會形成概念模型,在新資料面前則依據概念模型直接推導計算得出結論。
無監督最近鄰
無監督最近鄰的任務就是從訓練樣本中找到與查詢點在距離上最近的預定數量或範圍的多個點。需要找出點的個數可以是使用者定義的常量,這叫ķ最近鄰即KNN ,也可以通過使用者定義的新點的距離半徑範圍得出,這叫基於半徑的最近鄰即RNN。
KNN無監督最近鄰示例
import numpy as np import matplotlib.pyplot as plt from sklearn import neighbors # random the data as the training data x = 5 * np.random.random((50, 2)) y = np.array([[1, 3], [4, 2]]) # knn n_neighbors = 5 # create color maps from matplotlib.colors import ListedColormap cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF']) # fit the training data from sklearn.neighbors import NearestNeighbors nbrs = NearestNeighbors(n_neighbors = n_neighbors, algorithm = 'auto'); nbrs.fit(x) # get the nearest neighbors distances, indices = nbrs.kneighbors(y) print "distance:",distances print "indices:",indices # get the selection of nearest neighbors selected = nbrs.kneighbors_graph(y).toarray() print "selected:",selected # plot the point plt.plot(y[:,0], y[:,1], 'g+') # plot the area t = np.linspace(0, np.pi * 2, 50) x_t = np.cos(t) y_t = np.sin(t) for i in range(y.shape[0]) : plt.plot(x_t * distances[i, -1] + y[i, 0], y_t * distances[i, -1] + y[i, 1]) # all selected selected = selected[0, :].astype(np.bool) | selected[1, :].astype(np.bool) selected = selected.astype(np.int32) # plot the selection plt.scatter(x[:, 0], x[:, 1], c = selected, cmap = cmap_bold, edgecolor = 'k', s = 20) plt.show()
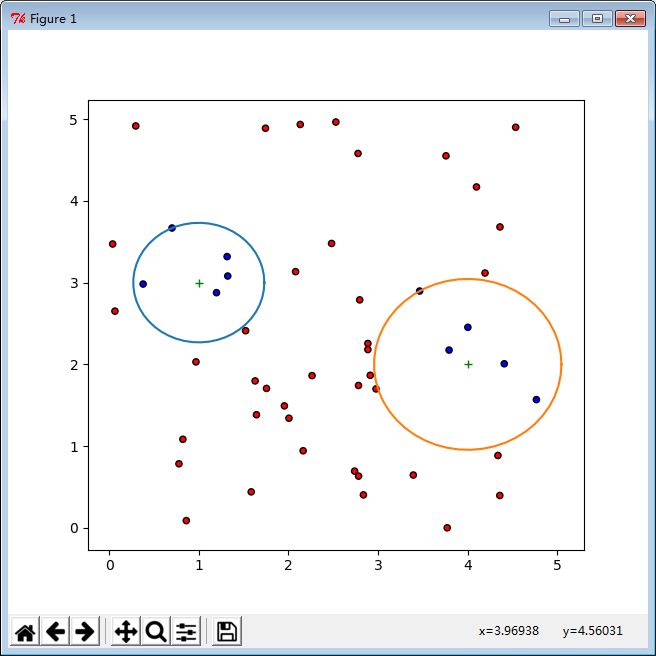
RNN無監督最近鄰示例:
import numpy as np import matplotlib.pyplot as plt from sklearn import neighbors # random the data as the training data x = 5 * np.random.random((50, 2)) y = np.array([[1, 3], [4, 2]]) # rnn n_radius = 1 # create color maps from matplotlib.colors import ListedColormap cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF']) # fit the training data from sklearn.neighbors import NearestNeighbors nbrs = NearestNeighbors(radius = n_radius, algorithm = 'auto'); nbrs.fit(x) # get the nearest neighbors distances, indices = nbrs.radius_neighbors(y) print "distance:",distances print "indices:",indices # get the selection of nearest neighbors selected = nbrs.radius_neighbors_graph(y).toarray() print "selected:",selected # plot the point plt.plot(y[:,0], y[:,1], 'g+') # plot the area t = np.linspace(0, np.pi * 2, 50) x_t = np.cos(t) y_t = np.sin(t) for i in range(y.shape[0]) : plt.plot(x_t * n_radius + y[i, 0], y_t * n_radius + y[i, 1]) # all selected selected = selected[0, :].astype(np.bool) | selected[1, :].astype(np.bool) selected = selected.astype(np.int32) # plot the selection plt.scatter(x[:, 0], x[:, 1], c = selected, cmap = cmap_bold, edgecolor = 'k', s = 20) plt.show()

最近鄰分類
最近鄰分類屬於非泛化學習或基於例項的學習,他不會從訓練資料上學習去構造一個泛化的概念模型。基於最鄰近方法從樣本集合中找出的點通過投票得出最具代表性的標籤作為查詢點的標籤,一般情況下,從訓練樣本集合中找出的多個點使用統一的權重來投票查詢點的標籤,在某些情況下,需要進行加權,分配的權重與查詢點的距離成反比,即與查詢點的距離越大,權重越小。
一個查詢點的ķ個最近鄰分類方法為KNN演算法,一個查詢點的固定半徑ř內的最近鄰分類方法為RNN方法。
KNN最近鄰分類示例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import neighbors
# import some data to play with
from sklearn import datasets
iris = datasets.load_iris()
# only take the first two features.
# we could avoid this ugly slicing by using a two-dim dataset
x = iris.data[:, :2]
y = iris.target
# k
n_neighbors = 15
# create color maps
from matplotlib.colors import ListedColormap
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
# knn
n_neighbors = 15
for weights in ['uniform', 'distance']:
# we create an instance of Neighbors classifier and fit the data
clf = neighbors.KNeighborsClassifier(n_neighbors, weights = weights)
clf.fit(x, y)
# plot the decision boundary.
# For that, we will assign a color to each point in the mesh[x_min, x_max] * [y_min, y_max]
x_min, x_max = x[:, 0].min() - 1, x[:, 0].max() + 1
y_min, y_max = x[:, 1].min() - 1, x[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02), np.arange(y_min, y_max, .02))
# predict
z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
# put the result into a color plot
z = z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, z, cmap = cmap_light)
# plot also the training points
plt.scatter(x[:, 0], x[:, 1], c = y, cmap = cmap_bold, edgecolor = 'k', s = 20)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("3-Class classification (k = %i, weithts = '%s')" % (n_neighbors, weights))
plt.show()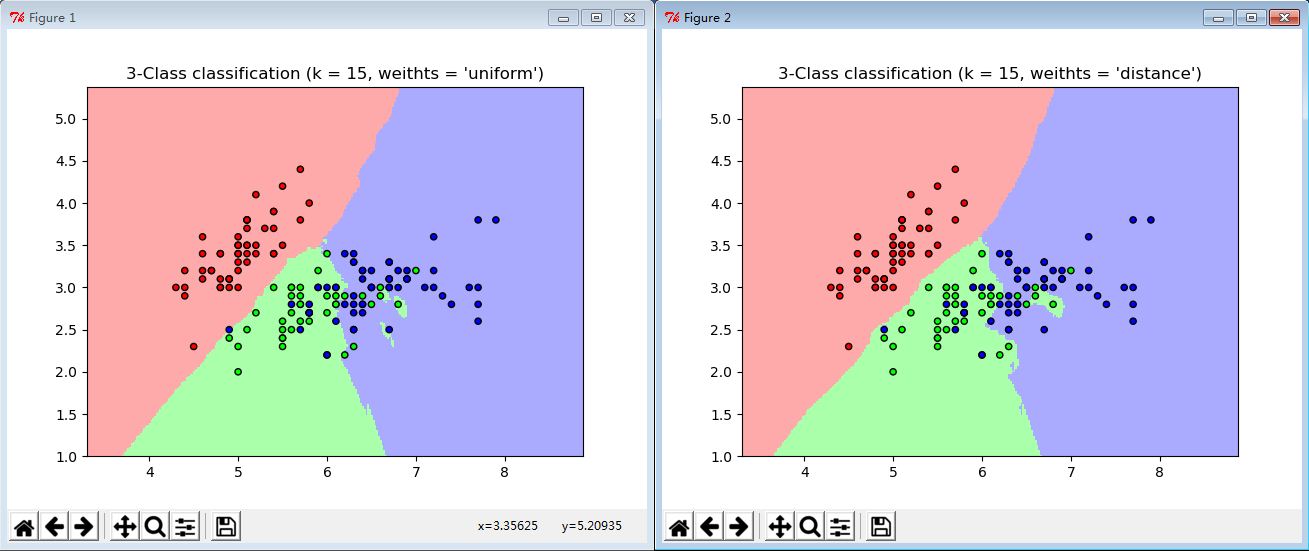
RNN最近鄰分類示例
基於半徑最近鄰分類方法中需要半徑引數,而給出合適的半徑引數非常困難,需要進行資料的歸一化預處理,並且RNN對資料的分佈也有要求。後續介紹資料歸一化後補充RNN最近鄰分類示例。
最近鄰迴歸
最近鄰迴歸是用在資料標籤為連續變數的場景下,查詢點的標籤是由它的最近鄰點的標籤的均值計算而來。最近鄰迴歸在計算查詢點的標籤時同最近鄰分類一樣可以使用權重,可以是統一的權重或者距離權重。
同樣最近鄰迴歸也有KNN和RNN兩種,基於查詢點的ķ個最近鄰實現和基於查詢點的固定半徑ř內的鄰點實現。
KNN最近鄰迴歸示例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import neighbors
np.random.seed(0)
x = np.sort(5 * np.random.rand(40, 1), axis = 0)
t = np.linspace(0, 5, 500)[:, np.newaxis]
y = np.sin(x).ravel()
# add noise to targets
y[::5] += 1 * (0.5 - np.random.rand(8))
# knn
n_neighbors = 5
for i, weights in enumerate(['uniform', 'distance']) :
reg = neighbors.KNeighborsRegressor(n_neighbors, weights = weights)
reg.fit(x, y)
y_pred = reg.predict(t)
plt.subplot(2, 1, i + 1)
plt.scatter(x, y, c = 'k', label = 'data')
plt.plot(t, y_pred, c = 'g', label = 'prediction')
plt.axis('tight')
plt.legend()
plt.title("KNeighborsRegressor (k = %i, weights = '%s')" % (n_neighbors, weights))
plt.tight_layout()
plt.show()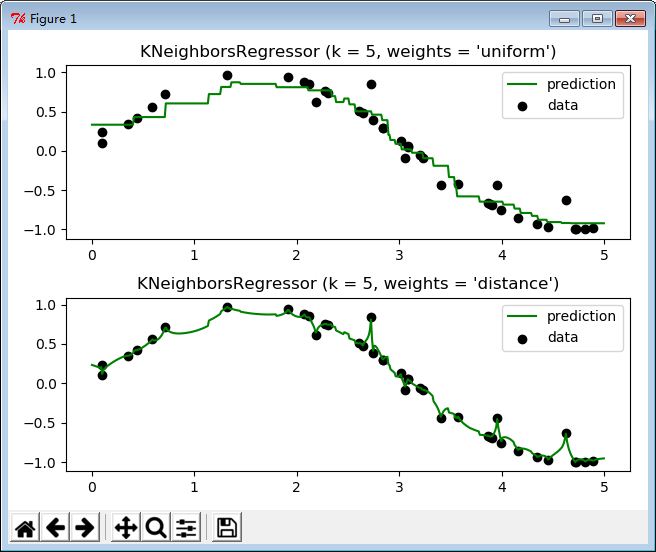
RNN最近鄰迴歸示例
基於半徑最近鄰迴歸方法中需要半徑引數,而給出合適的半徑引數非常困難,需要進行資料的歸一化預處理,並且RNN對資料的分佈也有要求。後續介紹資料歸一化後補充RNN最近鄰迴歸示例。
最近鄰演算法
無論無監督最近鄰,還是最近鄰分類或者最近鄰迴歸,最為核心的是如何計算訓練樣本中與查詢點距離最近的多個點。最為直接的方法是求解查詢點與訓練樣本中每一個點的距離,根據距離大小取距離最鄰近的多個點即可,這種最鄰近演算法為暴力方法(蠻力)。
對於d維的Ñ個樣本資料來說,這個方法的複雜度是-O [d * N ^ 2],對於小資料樣本來說,暴力最近鄰是非常不錯的。當樣本數Ñ增大,暴力最近鄰變得不切實際了,甚至不可行。
樹方法是一種優化的最近鄰計算方法。其基於樹的資料結構試圖通過有效的編碼樣本的聚合距離資訊來減少所需的距離計算量。基本思想是,若甲點距離乙點非常遠,乙點距離ç點非常近,可知甲點與ç點距離也非常遠,不需要明確計算阿與ç點之間的距離。通過這種方式,最近鄰計算複雜度可以降低為-O [d * N *log(N)]。在大樣本資料下,相對於暴力最鄰近計算有顯著改善。
目前樹方法有KD樹方法和Ball樹方法,KD樹在資料維度較低情況下表現優異,而Ball tree方法則在高維度資料情況下表現優異。