
評估分類器的效能:保持方法、交叉驗證、自助法等
目錄
一、保持(holdout)方法
保持方法其實就是我們最經常用的,最普遍的方法。
將標記的資料分成兩個不相交的集合,一部分作為訓練集,一部分作為驗證集。在資料集上訓練我們的分類模型,在檢驗集上評估模型的效能。兩個集合的劃分比例通常根據專家判斷,比如2:1,1:2等。
保持方法有眾所周知的侷限性:1、模型效能往往不如用全部被被標記的樣本都用於訓練來得好;2、模型高度依賴於訓練集構成。訓練集越小,模型方差越大;訓練集太大,則驗證集就少了,那麼話估計出來的準確率不太可靠。3、訓練集和檢驗集不是獨立的關係,因為這兩個子集來源於同一個資料集,在一個子集中超出比例的類在另一個子集就低於比例。
二、隨機二次抽樣
多次重複保持方法,以改進分類器效能的估計,即隨機二次抽樣(random subsampling)。
總準確率是每一次迭代模型的準確率的平均。
侷限性:1、和保持方法一樣,訓練階段也沒有利用到儘可能多的資料。2、由於它沒有控制每個資料用於訓練和檢驗的次數,因此有些訓練的資料使用的頻率可能比其他高很多。這樣模型的權重會朝被多次使用的訓練子集那邊偏倚。
三、交叉驗證
交叉驗證中,每個資料用於訓練的次數相同,都是一次。
二折交叉驗證:把資料集分為相同大小的2個子集,選擇一個作為訓練集,另一個作為檢驗集,然後交換兩個集合的角色。總誤差為對兩次執行求和。
K折交叉驗證:對二折的推廣。把資料氛圍k份,按上述思想重複k次,使得每份資料都用於訓練、檢驗各一次。總誤差是k次執行誤差的和。
留一法:特殊情況下,K折交叉驗證中的k=N,N是資料集大小,則為留一法。這個方法中,每個訓練集有N-1,驗證集就1個數據。這個方法需要重複N此,計算開銷很大;每個檢驗集就1個數據,效能估計度量的方法偏高。
該方法優點是儘可能多地訓練資料,此外,驗證集之間是互斥的,有效覆蓋了整個資料集。
四、自助(bootstrap)法
上面講的所有方法都是基於不放回抽樣。因此,單次的訓練集和檢驗集都不包含重複的資料。在自助法中,訓練資料採用有放回抽樣,使得它等概率地再次被重新抽取。
大小為N的一個自助樣本,一個數據被抽取的概率是1-(1-1/N)^N。當N充分大時,概率逼近1-e^-1 = 0.632。沒有抽中的記錄就成為檢驗集的一部分。
在檢驗集上得到自助樣本準確率的一個估計,重複b此抽樣過程,產生b個樣本。
通過組合每個自助樣本的準確率()和由包含所有樣本的訓練集計算的準確率(acc.s)計算總準確率(acc.boot):
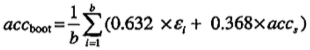
上式方法叫做.632自助法。這裡對和acc.s分配了不同的權重,
的權重即一個數據被抽取的平均概率0.632。
