
圖解演算法 第10章 k最近鄰演算法
本章內容
k鄰近演算法建立分類系統
學習特徵抽取
學習迴歸
學習k最近鄰居演算法的應用和侷限性
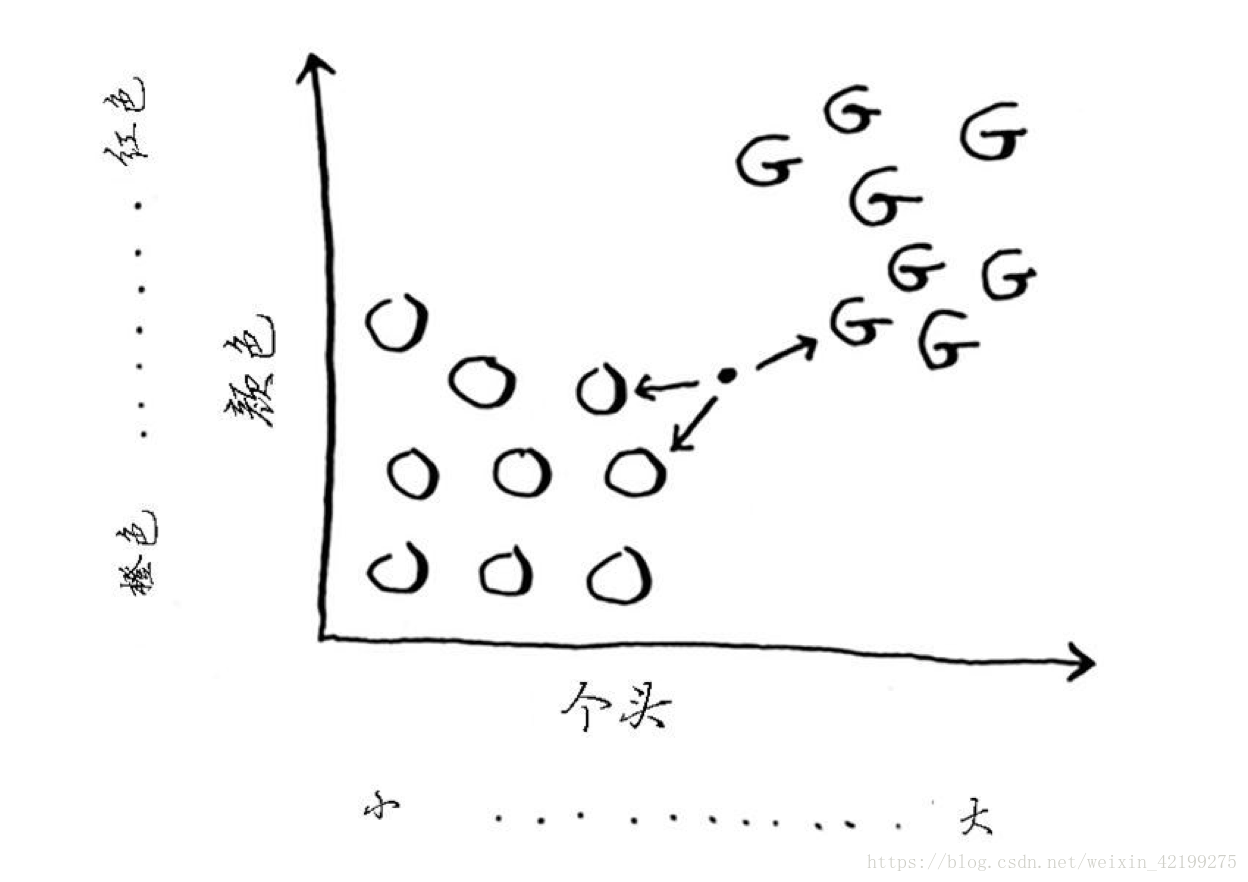
k最近鄰居 k-nearest neighbours KNN
特徵抽取
座標軸中兩個點的距離:勾股定理
OCR圖書數字化
提取線段,點,曲線等特徵。
相關推薦
圖解演算法 第10章 k最近鄰演算法
本章內容 k鄰近演算法建立分類系統 學習特徵抽取 學習迴歸 學習k最近鄰居演算法的應用和侷限性 k最近鄰居 k-nearest neighbours KNN 特徵抽取 座標軸中兩個點的距離:勾股定理 OCR圖書數字化 提取線段,點,曲線等特徵。
《演算法圖解》第10章 K最近鄰(K nearest neighbors,KNN)演算法
今天看到這裡的案例非常有意思,即以座標軸中的座標來作為引數。計算不同點的距離。實際上就是標記一些使用者的喜好和習慣,不同的維度代表不同的專案,在這個維度上的值可表示喜好程度。電影評分、音樂收藏...總之,很多情況都可以用,很有趣。就是標記了很多使用者,看哪些使
【機器學習實戰】第10章 K-Means(K-均值)聚類演算法
第 10章K-Means(K-均值)聚類演算法 K-Means 演算法 聚類是一種無監督的學習, 它將相似的物件歸到一個簇中, 將不相似物件歸到不同簇中. 相似這一概念取決於所選擇的相似度計算方法. K-Means 是發現給定資料集的 K 個簇的聚類演算法, 之
K最近鄰演算法(K-NN)
K-NN是什麼? K最近鄰演算法是一種簡單但目前最常用的分類演算法,也可用於迴歸。 KNN沒有引數(不對資料潛在分佈規律做任何假設),基於例項(不建立明確的模型,而是通過具體的訓練例項進行預測),用於監督學習中。 K-NN演算法怎麼工作? 當用KNN進行分類時,
圖說十大資料探勘演算法(一)K最近鄰演算法
用官方的話來說,所謂K近鄰演算法,即是給定一個訓練資料集,對新的輸入例項,在訓練資料集中找到與該例項最鄰近的K個例項(也就是上面所說的K個鄰居), 這K個例項的多數屬於某個類,就把該輸入例項分類到這個類中。 如果你之前沒有學習過K最近鄰演算法,那今天幾張圖,讓你明白什麼是K最近鄰
python -- K最近鄰演算法
KNN核心演算法函式 #! /usr/bin/env python3 # -*- coding: utf-8 -*- # fileName : KNNdistance.py # author : [email protected] import
tensorflow100天—第5天:最近鄰演算法
python程式碼 import tensorflow as tf import numpy as np from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_
K最近鄰演算法(KNN)---sklearn+python實現
def main(): import numpy as np from sklearn import datasets digits=datasets.load_digits() x=digits.data y=digits.target from sklear
KNN K最近鄰演算法
K Nearest Neighbor,KNN,K最近鄰演算法。 演算法原理: (1)計算未知類別資料點與已知類別資
機器學習-簡單的K最近鄰演算法及python實現
根據前人的成果進行了學習 https://www.cnblogs.com/ahu-lichang/p/7161613.html#commentform 1、演算法介紹 其實k最近鄰演算法算是聚類演算法中最淺顯易懂的一種了,考慮你有一堆二維資料,你想很簡單的把它分開,像下圖這
機器學習(4)K最近鄰演算法
定義:根據最近的樣本決定測試樣本的類別。為了判斷未知例項的類別,以所有已知類別的例項作為參照 選擇引數K 計算未知例項與所有已知例項的距離 選擇最近K個已知例項 根據少數服從多數的投票法則(majority-voting),讓未知例項歸類為K個
K最近鄰演算法
設想你想了解一個陌生人的飲食風格,如果你對他所知無幾,那麼最容易想到的一個捷徑就是看看他生存的周圍人群的口味。但是如果你對他的資訊知道更多,例如知道他的年齡、收入等,那麼這個時候就最好從他周圍的人群中去挑選與他年齡、收入相近的人的飲食風格,這樣預測會更準確一點。這其中蘊含的
《機器學習實戰》k最近鄰演算法(K-Nearest Neighbor,Python實現)
============================================================================================ 《機器學習實
資料探勘十大經典演算法之K最近鄰演算法
k-最近鄰演算法是基於例項的學習方法中最基本的,先介紹基於例項學習的相關概念。 基於例項的學習 1.已知一系列的訓練樣例,很多學習方法為目標函式建立起明確的一般化描述;但與此不同,基於例項的學習方法只是簡單地把訓練樣例儲存起來。 從這些例項中泛化
K最近鄰演算法(KNN)
K最近鄰 (k-Nearest Neighbors,KNN) 演算法是一種分類演算法,也是最簡單易懂的機器學習演算法,沒有之一。1968年由 Cover 和 Hart 提出,應用場景有字
scikit-learn學習之K最近鄰演算法(KNN)
======================================================================本系列部落格主要參考 Scikit-Learn 官方網站上的每一個演算法進行,並進行部分翻譯,如有錯誤,請大家指正 ========
利用Python實現k最近鄰演算法 並識別手寫數字(詳細註釋)
K最近鄰(k-Nearest Neighbor,KNN)分類演算法,是一個理論上比較成熟的方法,也是較為簡單的機器學習演算法之一。該方法的思路是:如果一個樣本在特徵空間中的k個最相似(即特徵空間中最鄰近)的樣本中的大多數屬於某一個類別,則該樣本也屬於這個類別。K最近鄰
k最近鄰演算法(K-Nearest Neighbor)理解與python實現
numpy 模組參考教程:http://old.sebug.net/paper/books/scipydoc/index.html 一:什麼是KNN演算法? kNN演算法全稱是k-最近鄰演算法(K-Nearest Neighbor) kNN演算法的核心思想是如果一個樣本在特
第九章 KNN(K最近鄰分類演算法)
1、惰性學習法 說到惰性學習法,就要提到急切學習法。 急切學習法:給定訓練集, 在接收待分類的新元祖(如檢驗元組)之前,就構造泛化(即分類)模型。如:決策樹歸納、貝葉斯分類、基於規則的分類、後向傳播分類、支援向量機和基於關聯規則挖掘的分類等。
《Machine Learning in Action》| 第1章 k-近鄰演算法
準備:使用 Python 匯入資料 """ @函式說明: 建立資料集 """ def createDataSet(): # 四組二維特徵 group = np.array([[3,104],[2,100],[101,10],[99,5]])