
ALS推薦演算法在Spark上的優化從50分鐘到3分鐘
從50多分鐘到3分鐘的優化
某推薦系統需要基於Spark用ALS演算法對近一天的資料進行實時訓練, 然後進行推薦. 輸入的資料有114G, 但訓練時間加上預測的時間需要50多分鐘, 而業務的要求是在15分鐘左右, 遠遠達不到實時推薦的要求, 因此, 我們與業務側一起對Spark應用進行了優化.
另外提一下, 該文最好與之前我寫的另一篇blog < Spark + Kafka 流計算優化 > 一起看, 因為一些細節我不會再在該文中描述.
優化分析
從資料分析, 雖然資料有114G, 但ALS的模型訓練時間並不長, 反而是資料載入和ALS預測所佔用的時間較長. 因此我們把重點放在這兩點的優化中.
從Spark的Web UI可以看到, 資料載入的job中task的數量較多, 較小. 模型預測的job也是有這樣的問題, 因此, 可以猜測並行度過大造成了叢集的協調負荷過重.
僅降低並行度和優化JVM 引數
我們用常見的”rdd.repartitionBy”把並行度降低後, 作業計算耗時減少並不明顯, 且在模型預測的job中會有executor死掉的現象. 進而檢視日誌, 發現是記憶體佔用過多, yarn把Spark應用給kill了.
為解決該現象, 加入這些JVM引數: “ -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:MaxTenuringThreshold=72 -XX:NewRatio=2 -XX:SurvivorRatio=6 -XX:+CMSParallelRemarkEnabled -XX:+ParallelRefProcEnabled -XX:+CMSPermGenSweepingEnabled -XX:+CMSClassUnloadingEnabled -XX:MaxTenuringThreshold=31 -XX:SurvivorRatio=8 -XX:+ExplicitGCInvokesConcurrent -XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses -XX:+AlwaysPreTouch -XX:-OmitStackTraceInFastThrow -XX:+UseCompressedStrings -XX:+UseStringCache -XX:+OptimizeStringConcat -XX:+UseCompressedOops -XX:+CMSScavengeBeforeRemark -XX:+UseBiasedLocking -XX:+AggressiveOpts " 具體說明和原因請參考本人的另一篇blog < Spark + Kafka 流計算優化 >.
笛卡爾積操作中的預先分塊
作了上述例行優化後, ALS預測步驟的耗時減少依然不明顯, 為發掘原因, 我們看了下原始碼, 驚奇的發現在ALS預測中竟然是用了笛卡爾積操作, 114G的資料少說也有幾千萬行記錄, 幾千萬行記錄進行笛卡爾積, 不慢才怪吧.
還好, 我們有擴充套件版的ALS預測方法, 可以將資料預先分塊, 而不必一行行的進行笛卡爾積, 加快了笛卡爾積的速度.
val recommendations = ExtMatrixFactorizationModelHelper.recommendProductsForUsers( model.get, numRecommendations
該方法會對model中的userFeatures和itemFeatures矩陣進行預先分塊, 減少網路包的傳輸量和笛卡爾積的計算量.
這裡的第三個引數是每一個塊所包含的行數, 此處的420000表示當我們對userFeatures或itemFeatures進行分塊時, 每一個塊包含了矩陣的420000行.
如何計算這裡的一個塊要包含多少行呢, 舉例如下:
由於ALS演算法中設定的rank是10, 因此生成的userFeatures和itemFeatures的個數是10, 它們的每一行是(Int,Array[Double]), 其中Array.size是10.
因此可根據如下計算每行所佔的空間大小:
空Array[10]的大小=16+8*10=96Byte. 陣列中的元素是Double, 十個Double物件的大小是 16*10=160Byte. 作為key的Integer的大小是16Byte. 因此每行佔空間96+160+16=212Byte.
另外,要計算頻寬: 由於是千兆網絡卡,因此頻寬為1Gbit,轉換為Byte也就是128MByte的頻寬.
考慮到” spark.akka.frameSize=100”以及網路包包頭需要佔的空間, 和Java的各種封裝要佔的空間, 我們計劃讓1個block就幾乎佔滿頻寬, 也就是一個block會在100MByte左右.
因此, 一個block要佔 60*1024*1024/212=296766行, 因此blocksize=494611, 考慮到各個object也佔記憶體, 因此行數定為420000左右.
在分塊後ExtMatrixFactorizationModelHelper.recommendProductsForUsers中會對塊進行重新分割槽, 以達到基於塊的均勻分佈.
提高檔案載入速度
以前都是載入小檔案, 每個檔案才幾M大小, 遠遠低於Hadoop的塊大小, 使得IO頻繁, 檔案也頻繁開啟關閉, 載入速度自然就慢. 為解決該問題, 我們使用sc.wholeTextFiles(dirstr,inputSplitNum)來載入HDFS的檔案到Spark中. 該方法使用Hadoop的CombineFileInputFormat把多個小檔案合併成一個Split再載入到Spark中.
但其實, 載入速度對整個Job的執行效率影響不大, 效果有限.

上圖,是val inputData = sc.wholeTextFiles(dirstr,80) 和RangePartition.
貌似載入速度也好不到哪兒去.第一個job用了11min
'
上圖, 用的是valinputData = sc.textFile(dirstr)和RangeRepartition,同等情況下,載入也需要11min.
(見job6)

上圖,是val inputData = sc.wholeTextFiles(dirstr,120) 和RangePartition.
貌似提高了wholeTextFiles()的split數量可以提升效能, 從8.4min多(此時split為80左右)到現在的8.1min

上圖,是val inputData = sc.wholeTextFiles(dirstr,220) 和RangePartition. 第一次載入提升到6.0min.
其它job由於loclity的問題,時間有所拉長, 影響不大.

上圖,是val inputData = sc.wholeTextFiles(dirstr,512) 和RangePartition. 第一次載入要7.1min. 估計220個split應該是個比較好的值了. 按比例就是 220(file split數) / 27000(小檔案數) = 0.8% , 該場景中每個小檔案10M左右. 也就是每個file split包含123個小檔案, 每個file split 1230M, 也就是約1G左右.
減少笛卡爾積計算量
回到對笛卡爾積計算的優化, 因為50分鐘的計算量基本上都是耗在笛卡爾積的計算上的.
我們先看一下task的分佈圖, 由圖看到, 資料並不是十分雜湊:
 猜測原因肯是通過Array.mkString.hashCode作為key並不能保證資料的均勻雜湊.因此, 我們disable掉了在笛卡爾積計算前的預分塊時的再分割槽, 而是把再分割槽提到分塊之前.
猜測原因肯是通過Array.mkString.hashCode作為key並不能保證資料的均勻雜湊.因此, 我們disable掉了在笛卡爾積計算前的預分塊時的再分割槽, 而是把再分割槽提到分塊之前.
這樣一來, task分佈稍微均衡了一些, 但依然不甚理想. 為了合理的降低task數量和均勻task的分佈, 我們進一步使用了Spark擴充套件版本的自動分割槽功能.
val userFactors = ExtSparkHelper.repartionPairRDDBySize(oldUsrFact, ThreeM)
這個方法有兩個引數, 第一個是需要分割槽的RDD, 第二個是我們期望的每一個task的input data的大小. 一般來說, input data與計算產生的data的大小相差不大, 但笛卡爾積卻不同, 有可能產生上百倍的中間資料量. 因此, 我這裡設定的每個task的input data是3M, 計算產生的中間資料剛好在1G左右, 一個executor可以同時跑3個task, 也算是比較理想的.
優化後的task分佈圖也比較理想, 十分均勻且沒有任何浪費, 如下:

因此, 這一步優化後, 原笛卡爾積的執行速度從幾十分鐘變為十幾秒.
整個ALS應用原來跑114G資料需要20多分鐘,如下圖現在只需要不到4min:
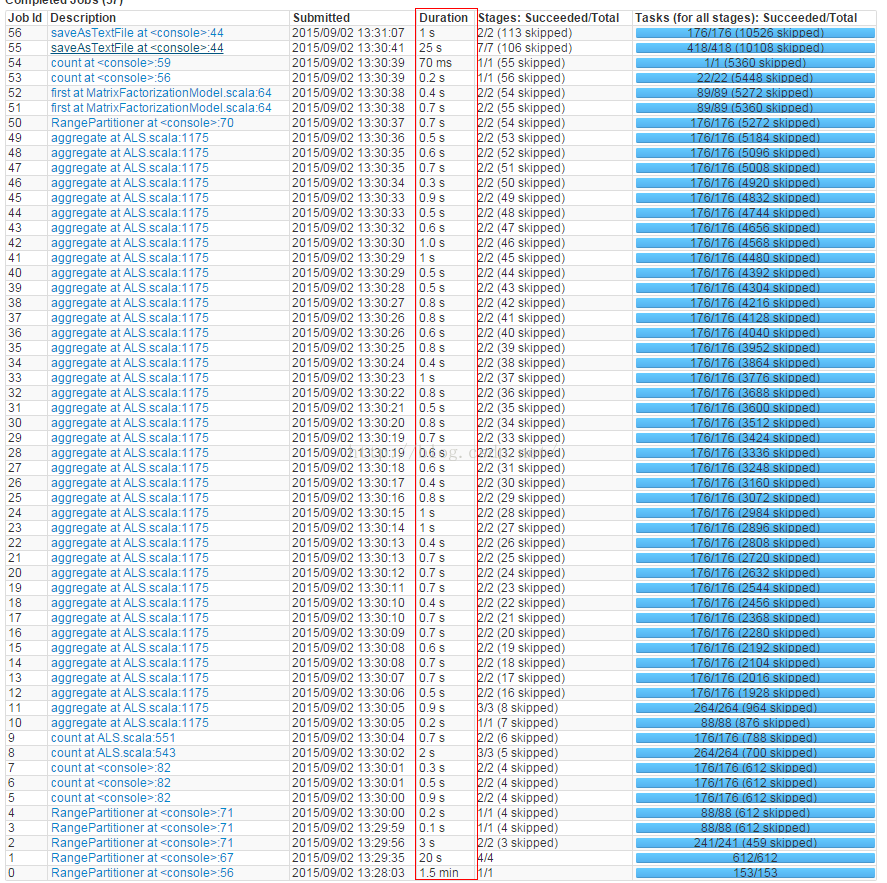
試了一下跑一天的全量資料, 共231.9G, 則原來需要1個多小時,現在只要不到6分鐘, 如下圖:
