
Recurrent Neural Network系列3--理解RNN的BPTT演算法和梯度消失_0
作者:zhbzz2007 出處:http://www.cnblogs.com/zhbzz2007 歡迎轉載,也請保留這段宣告。謝謝!
這是RNN教程的第三部分。
在前面的教程中,我們從頭實現了一個迴圈神經網路,但是並沒有涉及隨時間反向傳播(BPTT)演算法如何計算梯度的細節。在這部分,我們將會簡要介紹BPTT並解釋它和傳統的反向傳播有何區別。我們也會嘗試著理解梯度消失問題,這也是LSTM和GRU(目前NLP及其它領域中最為流行和有用的模型)得以發展的原因。梯度消失問題最早是由 Sepp Hochreiter 在1991年發現,最近由於深度框架的廣泛應用再次獲得很多關注。
為了能夠完全理解這部分,我建議你熟悉偏微分和基本的反向傳播工作原理。如果你不熟悉這些內容,你需要看這些教程 CS231n Convolutional Neural Networks for Visual Recognition 、 Calculus on Computational Graphs: Backpropagation 、 How the backpropagation algorithm works ,這些教程的難度依次增加 。
1 BPTT
讓我們快速回憶一下迴圈神經網路中的一些基本公式。定義中略微有些變化,我們將 \(o\) 修改為 \(\hat{y}\) 。這是為了與一些參考文獻保持一致。
\(s_{t} = tanh(U x_{t} + W s_{t-1})\)
\(\hat{y_{t}} = softmax(V s_{t})\)
我們定義損失或者誤差為互熵損失,如下所示,
\(E_{t}(y_{t},\hat{y_{t}}) = -y_{t}log(\hat{y_{t}})\)
\(E_{t}(y,\hat{y}) = \sum_{t}E_{t}(y_{t},\hat{y_{t}})=-\sum_{t}y_{t}log(\hat{y_{t}})\)
在這裡, \(y_{t}\) 是時刻 t 上正確的詞, \(\hat{y_{t}}\) 是預測出來的詞。我們通常將一整個序列(一個句子)作為一個訓練例項,所以總的誤差就是各個時刻(詞)的誤差之和。
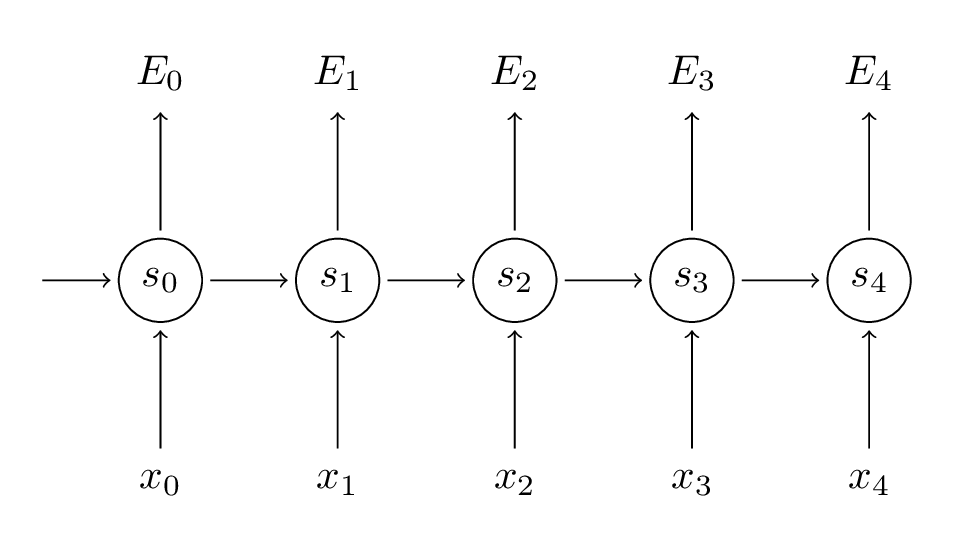
請牢記,我們的目標是計算誤差關於引數U、V和W的梯度,然後使用梯度下降法學習出好的引數。正如我們將誤差相加,我們也將一個訓練例項在每時刻的梯度相加: \(\frac{\partial E}{\partial W} = \sum_{t}\frac{\partial E_{t}}{\partial W}\) 。
為了計算這些梯度,我們需要使用微分的鏈式法則。當從誤差開始向後時,這就是 反向傳播 。在本文後續的部分,我們將會以 \(E_{3}\)
\(\frac{\partial E_{3}}{\partial V} = \frac{\partial E_{3}}{\partial \hat{y_{3}}} \frac{\partial \hat{y_{3}}}{\partial V} =\frac{\partial E_{3}}{\partial \hat{y_{3}}} \frac{\partial \hat{y_{3}}}{\partial z_{3}} \frac{\partial z_{3}}{\partial V}=(\hat{y_{3}} - y_{3}) \otimes s_{3}\)
在上述定義中,我們定義 \(z_{3} = V s_{3}\) ,\(\otimes\) 是兩個向量的外積。如果你暫時跟不上,不要擔心,我忽略了其中幾步,你也可以嘗試著自己計算這些梯度。我想要強調的是 \(\frac{\partial E_{3}}{\partial V}\) 僅僅依賴當前時刻的值,如 \(\hat{y_{3}}\) , \(y_{3}\) , \(s_{3}\) 。如果你已經有這些值,計算變數V的梯度就是一個簡單的矩陣相乘。
計算 \(\frac{\partial E_{3}}{\partial W}\) 卻有所不同,對於U也是。為了瞭解原因,我們寫出鏈式法則,正如上面所示,
\(\frac{\partial E_{3}}{\partial W}=\frac{\partial E_{3}}{\partial \hat{y_{3}}} \frac{\partial \hat{y_{3}}}{\partial s_{3}} \frac{\partial s_{3}}{\partial W}\)
其中, \(s_{3} = tanh(U x_{t} + W s_{2})\) (應該為 \(s_{3} = tanh(U x_{3} + W s_{2})\) )依賴於 \(s_{2}\) ,而 \(s_{2}\) 依賴於 W和 \(s_{1}\) 。所以如果我們對 W 求導數,我們不能簡單的將 \(s_{2}\) 視為一個常量。我們需要再次應用鏈式法則,我們真正想要的如下所示:
\(\frac{\partial E_{3}}{\partial W}=\sum_{k=0}^{3}\frac{\partial E_{3}}{\partial \hat{y_{3}}} \frac{\partial \hat{y_{3}}}{\partial s_{3}} \frac{\partial s_{3}}{\partial s_{k}} \frac{\partial s_{k}}{\partial W}\)
我們將每時刻對梯度的貢獻相加。也就是說,由於 W 在每時刻都用在我們所關心的輸出上,我們需要從時刻 t = 3 通過網路的所有路徑到時刻 t = 0 來反向傳播梯度:
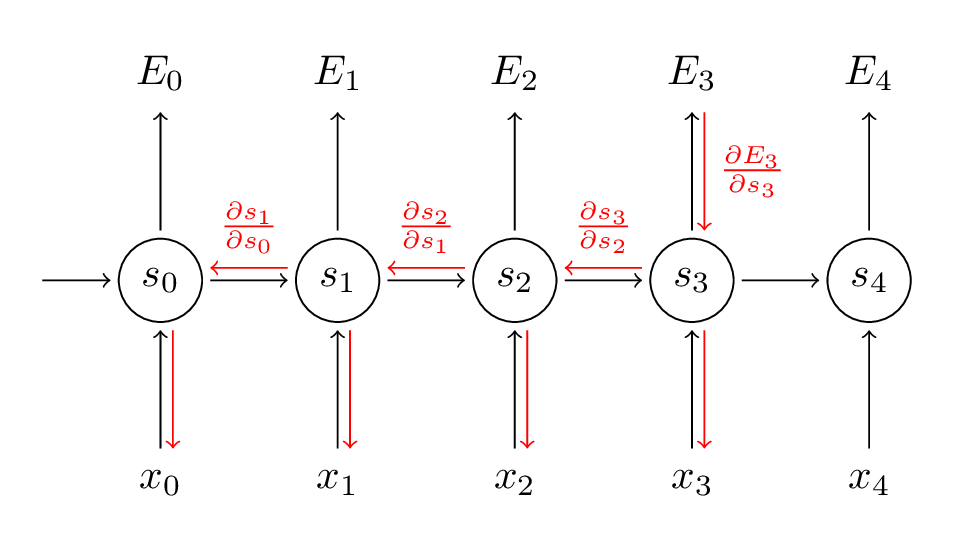
請留意,這與我們在深度前饋神經網路中使用的標準反向傳播演算法完全相同。主要的差異就是我們將每時刻 W 的梯度相加。在傳統的神經網路中,我們在層之間並沒有共享引數,所以我們不需要相加。但是我認為,BPTT就是標準反向傳播演算法在展開的迴圈神經網路上一個花哨的名稱。正如在反向傳播演算法中,你可以定義一個反向傳播的 delta 向量,例如 \(\delta_{2}^{(3)} = \frac{\partial E_{3}}{\partial z_{2}} = \frac{\partial E_{3}}{\partial s_{3}} \frac{\partial s_{3}}{\partial s_{2}} \frac{\partial s_{2}}{\partial z_{2}}\) ,其中 \(z_{2} = U x_{2} + W s_{1}\) , 然後應用相同的方程。
一個樸素的BPTT實現,程式碼如下,
def bptt(self, x, y):
T = len(y)
# Perform forward propagation
o, s = self.forward_propagation(x)
# We accumulate the gradients in these variables
dLdU = np.zeros(self.U.shape)
dLdV = np.zeros(self.V.shape)
dLdW = np.zeros(self.W.shape)
delta_o = o
delta_o[np.arange(len(y)), y] -= 1.
# For each output backwards...
for t in np.arange(T)[::-1]:
dLdV += np.outer(delta_o[t], s[t].T)
# Initial delta calculation: dL/dz
delta_t = self.V.T.dot(delta_o[t]) * (1 - (s[t] ** 2))
# Backpropagation through time (for at most self.bptt_truncate steps)
for bptt_step in np.arange(max(0, t-self.bptt_truncate), t+1)[::-1]:
# print "Backpropagation step t=%d bptt step=%d " % (t, bptt_step)
# Add to gradients at each previous step
dLdW += np.outer(delta_t, s[bptt_step-1])
dLdU[:,x[bptt_step]] += delta_t
# Update delta for next step dL/dz at t-1
delta_t = self.W.T.dot(delta_t) * (1 - s[bptt_step-1] ** 2)
return [dLdU, dLdV, dLdW]這應該會給你一個印象:為什麼標準的迴圈神經網路很難訓練?序列(句子)可以很長,可能20個詞或者更多,因此你需要反向傳播很多層。實際上,許多人會在反向傳播數步之後進行截斷。
2 梯度消失
在前面的博文 Recurrent Neural Network系列1--RNN(迴圈神經網路)概述 中,我已經提到迴圈神經網路很難學習到長期的依賴 -- 在相隔數步的詞之間的影響。這就會導致一些問題,因為英文句子通常被一些不是很近的詞所決定,例如:“The man who wore a wig on his head went inside” 。這個句子是關於一個人走進屋裡,不是關於假髮的。對於普通的迴圈神經網路,不太可能捕獲這些資訊。為了理解為什麼,讓我們仔細分析一下上面推匯出來的梯度:
\(\frac{\partial E_{3}}{\partial W}=\sum_{k=0}^{3}\frac{\partial E_{3}}{\partial \hat{y_{3}}} \frac{\partial \hat{y_{3}}}{\partial s_{3}} \frac{\partial s_{3}}{\partial s_{k}} \frac{\partial s_{k}}{\partial W}\)
請注意, \(\frac{\partial s_{3}}{\partial s_{k}}\) 本身就是一個鏈式法則。例如, \(\frac{\partial s_{3}}{\partial s_{1}} = \frac{\partial s_{3}}{\partial s_{2}} \frac{\partial s_{2}}{\partial s_{1}}\) 。也要注意,我們是在一個向量上對向量函式求導,結果會是一個矩陣(稱之為 雅克比矩陣 ),所有的元素都是對應的導數。我可以將上述的梯度重寫為:
\(\frac{\partial E_{3}}{\partial W}=\sum_{k=0}^{3}\frac{\partial E_{3}}{\partial \hat{y_{3}}} \frac{\partial \hat{y_{3}}}{\partial s_{3}} (\prod_{j = k+1}^{3} \frac{\partial s_{j}}{\partial s_{j-1}}) \frac{\partial s_{k}}{\partial W}\)
上述雅克比矩陣中的2範數(你可以認為是絕對值)上限是1(具體參考這篇 On the difficulty of training recurrent neural networks)。tanh(或者sigmoid)啟用函式將所有的值對映到-1到1這個區間,導數的範圍在0到1這個區間(sigmoid是0到 \(\frac{1}{4}\) 這個區間),如下圖所示:
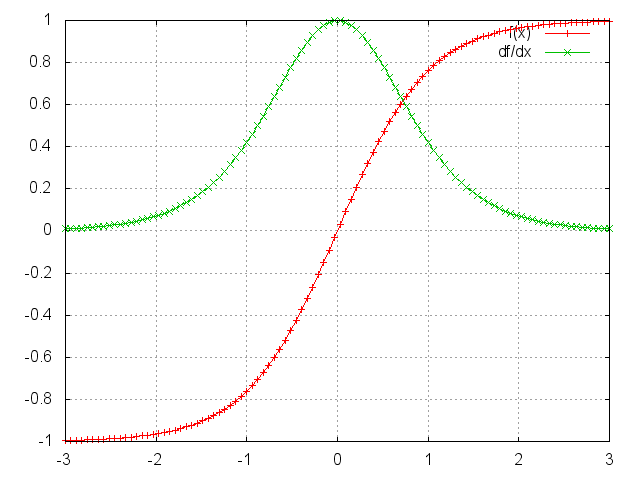
你可以看到tanh和sigmoid函式在兩端導數均為0。它們逐漸成為一條直線,當這個現象發生時,我們就說相應的神經元已經飽和了。它們的梯度為0,驅動前一層的其它梯度也趨向於0。因此,矩陣中有小值,並且經過矩陣相乘(t - k次),梯度值快速的以指數形式收縮,最終在幾個時刻之後完全消失。較遠的時刻貢獻的梯度變為0,這些時刻的狀態不會對你的學習有所貢獻:你最終以無法學習到長期依賴而結束。梯度消失不僅僅出現在迴圈神經網路中。它們也出現深度前饋神經網路中。它僅僅是迴圈神經網路趨向於很深(在我們這個例子中,深度與句子長度一樣),這將會導致很多問題。
依賴於我們的啟用函式和網路引數,如果雅克比矩陣的值非常大,我們沒有出現梯度消失,但是卻可能出現梯度爆炸。這就是梯度爆炸問題。梯度消失問題比梯度爆炸問題受到更多的關注,主要有兩個原因:1)梯度爆炸很明顯,你的梯度將會變成Nan(不是一個數字),你的程式將會掛掉;2)在預定義閾值處將梯度截斷(具體參考這篇 On the difficulty of training recurrent neural networks)是一種簡單有效的方法去解決梯度爆炸問題。梯度消失問題更加複雜是因為它不明顯,如論是當它們發生或者如何處理它們時。
幸運的是,目前已經有了一些緩解梯度消失問題的方法。對矩陣 W 合理的初始化可以減少梯度消失的影響。也可以加入正則化項。一個更好的方案是使用 ReLU而不是tanh或者sigmoid啟用函式。ReLU函式的導數是個常量,要麼是0,要麼是1,所以它不太可能出現梯度消失。更加流行的方法是使用長短時記憶(LSTM)或者門控迴圈單元(GRU)架構。LSTM是在 1997年提出,在NLP領域可能是目前最為流行的模型。GRU是在2014年提出,是LSTM的簡化版。這些迴圈神經網路的設計都是為了處理梯度消失和有效學習長期依賴。我們將會在後面的博文中介紹。
3 Reference
wiki-Backpropagation through time
BPTT演算法推導(需要注意此文中W和U與本文的W和U是相反的)
A Beginner’s Guide to Recurrent Networks and LSTMs
Backpropagation Through Time (BPTT)
相關推薦
Recurrent Neural Network系列3--理解RNN的BPTT演算法和梯度消失
這是RNN教程的第三部分。 在前面的教程中,我們從頭實現了一個迴圈神經網路,但是並沒有涉及隨時間反向傳播(BPTT)演算法如何計算梯度的細節。在這部分,我們將會簡要介紹BPTT並解釋它和傳統的反向傳播有何區別。我們也會嘗試著理解梯度消失問題,這也是LSTM和
Recurrent Neural Network系列3--理解RNN的BPTT演算法和梯度消失_0
作者:zhbzz2007 出處:http://www.cnblogs.com/zhbzz2007 歡迎轉載,也請保留這段宣告。謝謝! 這是RNN教程的第三部分。 在前面的教程中,我們從頭實現了一個迴圈神經網路,但是並沒有涉及隨時間反向傳播(BPTT)演算法如何計算梯度的細節
基於時間的反向傳播演算法和梯度消失 -part3
本文翻譯自 前文從零開始實現了RNN,但是沒有詳細介紹Backpropagation Through Time (BPTT) 演算法如何實現梯度計算。這篇文章將詳細介紹BPTT。之後會分析梯度消失問題,它導致了LSTM和GRU的發展,這是兩個在NLP領域最為流
論文《Chinese Poetry Generation with Recurrent Neural Network》閱讀筆記
code employ 是個 best rec AS Coding ack ase 這篇文章是論文‘Chinese Poetry Generation with Recurrent Neural Network’的閱讀筆記,這篇論文2014年發表在EMNLP。 ABSTRA
Recurrent Neural Network(1):Architecture
func isp ram soft 期望 UNC ural att 時間序列 Recurrent Neural Network是在單個神經元上,除了輸入與輸出外,添加了一條Recurrent回路。如下圖左側,將前一時刻神經元的輸出狀態s,作為下一時刻的一個輸入值,加權並入輸
Recurrent Neural Network for Text Classification with Multi-Task Learning
引言 Pengfei Liu等人在2016年的IJCAI上發表的論文,論文提到已存在的網路都是針對單一任務進行訓練,但是這種模型都存在問題,即缺少標註資料,當然這是任何機器學習任務都面臨的問題。 為了應對資料量少,常用的方法是使用一個無監督的預訓練模型,比如詞向量,實驗中也取得了不錯
迴圈神經網路(Recurrent Neural Network, RNN)
1. 前向傳播 at=g(a)(Waaa<t−1>+Waxx<t>+ba)a^{t}=g^{(a)}(W_{aa}a^{<t-1>}+W_{ax}x^{<t&a
論文:用RNN書寫及識別漢字, Drawing and Recognizing Chinese Characters with Recurrent Neural Network
論文地址:用RNN書寫及識別漢字 摘要 目前識別漢字的通常方法是使用CNN模型,而識別線上(online)漢字時,CNN需要將線上手寫軌跡轉換成像影象一樣的表示。文章提出RNN框架,結合LSTM和GRU。包括識別模型和生成模型(即自動生成手寫體漢字),基於端到端,直接處理序列結構,不
吳恩達Deeplearning.ai 第五課 Sequence Model 第一週------Recurrent Neural Network Model
這一節內容比較多,主要講述瞭如何搭建一個RNN標準單元 使用標準神經網路的不足: 1.不同樣本的輸入輸出長度不等(雖然都可以padding成最大長度的樣本) 2.(更主要的原因)text不同的位置之間不共享學習到的引數 RNN模型,可以用左邊也可
How to Visualize Your Recurrent Neural Network with Attention in Keras
Now for the interesting part: the decoder. For any given character at position t in the sequence, our decoder accepts the encoded sequence h=(h1,...,hT) as
論文筆記:DRAW: A Recurrent Neural Network For Image Generation
DRAW: A Recurrent Neural Network For Image Generation 2019-01-14 19:42:50 Paper:http://proceedings.mlr.press/v37/gregor15.pdf 本文將 V
李巨集毅機器學習課程筆記9:Recurrent Neural Network
臺灣大學李巨集毅老師的機器學習課程是一份非常好的ML/DL入門資料,李巨集毅老師將課程錄影上傳到了YouTube,地址:NTUEE ML 2016 。 這篇文章是學習本課程第25-26課所做的筆記和自己的理解。 Lecture 25,26: Recu
臺灣大學深度學習課程 學習筆記 lecture3-1 Recurrent Neural Network (RNN)
Recurrent Neural Network (RNN)迴圈神經網路常被用到的領域是Language Modeling,下面就從Language Modeling方法的發展,引入RNN。 Language Modeling 多個word組成一句話
『 論文閱讀』Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling
來自於論文:《Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling》 基於attention的encoder-decoder網
詳解迴圈神經網路(Recurrent Neural Network)
在文末有關於 RNN 的文章彙總,之前寫的大多是概覽式的模型結構,公式,和一些應用,今天主要放在訓練演算法的推導。 本文結構: 模型 訓練演算法 基於 RNN 的語言模型例子 程式碼實現 1. 模型 和全連線網路的區別 更細緻到向量級的
python爬蟲系列(3.4-使用xpath和lxml爬取伯樂線上)
一、爬取的程式碼 1、網站地址 2、具體實現程式碼 import requests from lxml import etree class JobBole(object): def __init__(self): &
JAVA學習筆記系列3-JVM、JRE和JDK的區別
JVM(Java Virtual Machine)就是一個虛擬的用於執行bytecode位元組碼的“虛擬計算機”。它和os打交道 JRE(Java Runtime Environment)包含:Java虛擬機器、庫函式、執行java應用程式所必須的檔案。它包含了JVM JDK(Java Developme
pytorch系列 --3 Variable,Tensor 和 Gradient
Variable & Automatic Gradient Calculation Tensor vs Variable graph and gradient 注意,在pytorch0.4中,tensor和pytorch合併了。 https://pytorch.
[GAN學習系列3]採用深度學習和 TensorFlow 實現圖片修復(上)
在之前的兩篇 GAN 系列文章--[GAN學習系列1]初識GAN以及[GAN學習系列2] GAN的起源中簡單介紹了 GAN 的基本思想和原理,這次就介紹利用 GAN 來做一個圖片修復的應用,主要採用的也是 GAN 在網路結構上的升級版--DCGAN,最初始的 GAN 採用的還是神經網路,即全連線網路,而 DC
java多執行緒系列3:悲觀鎖和樂觀鎖
1.悲觀鎖和樂觀鎖的基本概念 悲觀鎖: 總是認為當前想要獲取的資源存在競爭(很悲觀的想法),因此獲取資源後會立刻加鎖,於是其他執行緒想要獲取該資源的時候就會一直阻塞直到能夠獲取到鎖; 在傳統的關係型資料庫中,例如行鎖、表鎖、讀鎖、寫鎖等,都用到了悲觀鎖。還有java中的同步關鍵字Synchroniz