
卷積神經網路卷積核大小、個數,卷積層數的確定
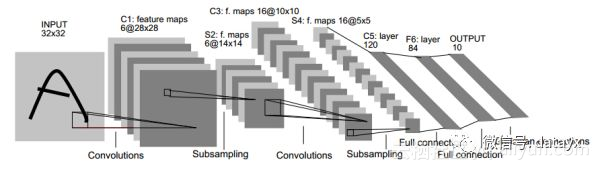
卷積神經網路的卷積核大小、卷積層數、每層map個數都是如何確定下來的呢?看到有些答案是剛開始隨機初始化卷積核大小,卷積層數和map個數是根據經驗來設定的,但這個裡面應該是有深層次原因吧,比如下面的手寫字卷積神經網路結構圖1,最後輸出為什麼是12個map,即輸出12個特徵?然後圖2又是輸出10個特徵了?

在達到相同感受野的情況下,卷積核越小,所需要的引數和計算量越小。
具體來說。卷積核大小必須大於1才有提升感受野的作用,1排除了。而大小為偶數的卷積核即使對稱地加padding也不能保證輸入feature map尺寸和輸出feature map尺寸不變(畫個圖算一下就可以發現),2排除了。所以一般都用3作為卷積核大小。
每一層卷積有多少channel數,以及一共有多少層卷積,這些暫時沒有理論支撐,一般都是靠感覺去設定幾組候選值,然後通過實驗挑選出其中的最佳值。這也是現在深度卷積神經網路雖然效果拔群,但是一直為人詬病的原因之一。
多說幾句,每一層卷積的channel數和網路的總卷積層數,構成了一個巨大的超參集合,這個超參集合裡的最優組合,很可能比目前業界各種fancy的結構還要高效。只是我們一來沒有理論去求解這個超參集合裡的最優,二來沒有足夠的計算資源去窮舉這個超參集合裡的每一個組合,因此我們不知道這個超參集合裡的最優組合是啥。
現在業界裡提出的各種fancy結構中不少都是不斷trial and error,試出來一個效果不錯的網路結構,然後講一個好聽的story,因為深度學習理論還不夠,所以story一般都是看上去很美,背後到底是不是這回事只有天知道。比如好用到不行的batch norm,它的story是解決internal covariate shift,然而最近有篇文章How Does Batch Normalization Help Optimization? (No, It Is Not About Internal Covariate Shift)通過實驗證明實際情況並不如此。
推薦一篇講如何設計CNN網路的文章A practical theory for designing very deep convolutional neural networks。
深度學習如何調參
調參就是trial-and-error. 沒有其他捷徑可以走. 唯一的區別是有些人盲目的嘗試, 有些人思考後再嘗試. 快速嘗試, 快速糾錯這是調參的關鍵.
首先說下視覺化:
我個人的理解, 對於視覺化, 更多的還是幫助人類以自己熟悉的方式來觀察網路. 因為, 你是不可能邊觀察網路, 還邊調參的. 你只是訓練完成後(或者準確率到達一個階段後), 才能視覺化. 在這之前, 網路沒有學習到良好的引數, 你可視化了也沒意義, 網路達到不錯的準確率了, 你看看其實也就聽個響. 同樣, 你的網路訓練的一塌糊塗, 你視覺化也沒什麼意義, 唯一能夠看到的就是中間結果亂七八糟, 或者全黑全白, 這時候你直接看最後準確率就可以知道這網路沒救了.
關於權重的視覺化Visualize Layer Weights(現在是否強求smooth其實意義不大, 這個後面說.):
同樣, 你看到一個不滿足平滑結果的影象, 你知道, 這網路訓練的不好, 但是為什麼呢? 是資料不好? 沒有預處理? 網路結構問題? Learning Rate太大或者太小? 或者就是差了一個LRN層(之前我就遇到, 加個LRN就能出smooth的weights, 當然這其實和預處理有關)?
Smooth是需要看一下的, 心裡有個數. 但是具體調參怎麼調是沒轍的. 第一, 你不可能告訴網路, 這層你得學個邊界檢測的功能出來. 第二, 不同任務下會有不同的weights(雖然底層的特徵有很大的通用性), 你覺得你憑什麼來指導一個看圖片比你快得多的機器?
再說現在是否需要強求smooth. 現在的趨勢是鼓勵使用小filter, 3x3大小, 多加層次(這樣, 非線性更好點). 換句話說, 3x3的圖片, 總共才9個畫素, 你怎麼判斷smooth與否呢? 當然如果你使用大的filter, 一般5x5往上, 運氣不差的話, 你是可以看到smooth的結果的.
咱們再說另外一個極端, 一個網路,執行的完美(滿足應用要求就算完美), 開啟一看, 這weights不smooth啊. 你告訴我, 你打算怎麼辦? 沒錯, 具有不平滑的權重的網路同樣可以獲得很好的結果(這種情況我都習以為常了).
那麼視覺化網路就不重要了?
非常重要, 但是不在訓練這塊, 而是幫助理解網路的原理這塊. 理解網路原理後, 你才能在設計結構的時候心裡有感覺(只是有感覺而已), 網路出了問題, 或者在某些情況下不滿意, 有更好的直覺去調整.(沒錯, 只是直覺, 雖然有些情況下的調整從網路原理來看邏輯上應該可以工作, 但是人家就是不工作, 你能咬機器去麼?)
那麼怎樣訓練一個不錯的網路呢?
這是一個很好的連結, 說明了如何從零開始不斷的trial-and-error(其實這裡面沒遇到什麼error):
Using convolutional neural nets to detect facial keypoints tutorial
對於調參我自己的經驗, 有下面這些:
基本原則:快速試錯
一些大的注意事項:
1.剛開始, 先上小規模資料, 模型往大了放, 只要不爆視訊記憶體, 能用256個filter你就別用128個. 直接奔著過擬合去. 沒錯, 就是訓練過擬合網路, 連測試集驗證集這些都可以不用.
為什麼?
- 你要驗證自己的訓練指令碼的流程對不對. 這一步小資料量, 生成速度快, 但是所有的指令碼都是和未來大規模訓練一致的(除了少跑點迴圈)
- 如果小資料量下, 你這麼粗暴的大網路奔著過擬合去都沒效果. 那麼, 你要開始反思自己了, 模型的輸入輸出是不是有問題? 要不要檢查自己的程式碼(永遠不要懷疑工具庫, 除非你動過程式碼)? 模型解決的問題定義是不是有問題? 你對應用場景的理解是不是有錯? 不要懷疑NN的能力, 不要懷疑NN的能力, 不要懷疑NN的能力. 就我們調參狗能遇到的問題, NN沒法擬合的, 這概率是有多小?
- 你可以不這麼做, 但是等你資料準備了兩天, 結果發現有問題要重新生成的時候, 你這周時間就醬油了.
2.Loss設計要合理.
- 一般來說分類就是Softmax, 迴歸就是L2的loss. 但是要注意loss的錯誤範圍(主要是迴歸), 你預測一個label是10000的值, 模型輸出0, 你算算這loss多大, 這還是單變數的情況下. 一般結果都是nan. 所以不僅僅輸入要做normalization, 輸出也要這麼弄.
- 多工情況下, 各loss想法限制在一個量級上, 或者最終限制在一個量級上, 初期可以著重一個任務的loss
3.觀察loss勝於觀察準確率
準確率雖然是評測指標, 但是訓練過程中還是要注意loss的. 你會發現有些情況下, 準確率是突變的, 原來一直是0, 可能保持上千迭代, 然後突然變1. 要是因為這個你提前中斷訓練了, 只有老天替你惋惜了. 而loss是不會有這麼詭異的情況發生的, 畢竟優化目標是loss.
給NN一點時間, 要根據任務留給NN的學習一定空間. 不能說前面一段時間沒起色就不管了. 有些情況下就是前面一段時間看不出起色, 然後開始穩定學習.
4.確認分類網路學習充分
分類網路就是學習類別之間的界限. 你會發現, 網路就是慢慢的從類別模糊到類別清晰的. 怎麼發現? 看Softmax輸出的概率的分佈. 如果是二分類, 你會發現, 剛開始的網路預測都是在0.5上下, 很模糊. 隨著學習過程, 網路預測會慢慢的移動到0,1這種極值附近. 所以, 如果你的網路預測分佈靠中間, 再學習學習.
5.Learning Rate設定合理
- 太大: loss爆炸, 或者nan
- 太小: 半天loss沒反映(但是, LR需要降低的情況也是這樣, 這裡視覺化網路中間結果, 不是weights, 有效果, 倆者視覺化結果是不一樣的, 太小的話中間結果有點水波紋或者噪點的樣子, 因為filter學習太慢的原因, 試過就會知道很明顯)
- 需要進一步降低了: loss在當前LR下一路降了下來, 但是半天不再降了.
- 如果有個複雜點的任務, 剛開始, 是需要人肉盯著調LR的. 後面熟悉這個任務網路學習的特性後, 可以扔一邊跑去了.
- 如果上面的Loss設計那塊你沒法合理, 初始情況下容易爆, 先上一個小LR保證不爆, 等loss降下來了, 再慢慢升LR, 之後當然還會慢慢再降LR, 雖然這很蛋疼.
- LR在可以工作的最大值下往小收一收, 免得ReLU把神經元弄死了. 當然, 我是個心急的人, 總愛設個大點的.
6 對比訓練集和驗證集的loss
判斷過擬合, 訓練是否足夠, 是否需要early stop的依據, 這都是中規中矩的原則, 不多說了.
7 清楚receptive field的大小
CV的任務, context window是很重要的. 所以你對自己模型的receptive field的大小要心中有數. 這個對效果的影響還是很顯著的. 特別是用FCN, 大目標需要很大的receptive field. 不像有fully connection的網路, 好歹有個fc兜底, 全域性資訊都有.
簡短的注意事項:
預處理: -mean/std zero-center就夠了, PCA, 白化什麼的都用不上. 我個人觀點, 反正CNN能學習encoder, PCA用不用其實關係不大, 大不了網路裡面自己學習出來一個.
shuffle, shuffle, shuffle.
網路原理的理解最重要, CNN的conv這塊, 你得明白sobel運算元的邊界檢測.
Dropout, Dropout, Dropout(不僅僅可以防止過擬合, 其實這相當於做人力成本最低的Ensemble, 當然, 訓練起來會比沒有Dropout的要慢一點, 同時網路引數你最好相應加一點, 對, 這會再慢一點).
CNN更加適合訓練回答是否的問題, 如果任務比較複雜, 考慮先用分類任務訓練一個模型再finetune.
無腦用ReLU(CV領域).
無腦用3x3.
無腦用xavier.
LRN一類的, 其實可以不用. 不行可以再拿來試試看.
filter數量2^n.
多尺度的圖片輸入(或者網路內部利用多尺度下的結果)有很好的提升效果.
第一層的filter, 數量不要太少. 否則根本學不出來(底層特徵很重要).
sgd adam 這些選擇上, 看你個人選擇. 一般對網路不是決定性的. 反正我無腦用sgd + momentum.
batch normalization我一直沒用, 雖然我知道這個很好, 我不用僅僅是因為我懶. 所以要鼓勵使用batch normalization.
不要完全相信論文裡面的東西. 結構什麼的覺得可能有效果, 可以拿去試試.
你有95%概率不會使用超過40層的模型.
shortcut的聯接是有作用的.
暴力調參最可取, 畢竟, 自己的生命最重要. 你調完這個模型說不定過兩天這模型就扔掉了.
機器, 機器, 機器.
Google的inception論文, 結構要好好看看.
一些傳統的方法, 要稍微瞭解瞭解. 我自己的程式就用過1x14的手寫filter, 寫過之後你看看inception裡面的1x7, 7x1 就會會心一笑。
原文釋出時間為:2018-07-14
本文作者:大資料探勘DT機器學習
本文來自雲棲社群合作伙伴“大資料探勘DT機器學習”,瞭解相關資訊可以關注“大資料探勘DT機器學習”
相關推薦
卷積神經網路卷積核大小、個數,卷積層數的確定
卷積神經網路的卷積核大小、卷積層數、每層map個數都是如何確定下來的呢?看到有些答案是剛開始隨機初始化卷積核大小,卷積層數和map個數是根據經驗來設定的,但這個裡面應該是有深層次原因吧,比如下面的手寫字卷積神經網路結構圖1,最後輸出為什麼是12個map,即輸出12個特徵?
卷積神經網路中十大拍案叫絕的操作:卷積核大小好處、變形卷積、可分離卷積等
文章轉自:https://www.leiphone.com/news/201708/0rQBSwPO62IBhRxV.html 從2012年的AlexNet發展至今,科學家們發明出各種各樣的CNN模型,一個比一個深,一個比一個準確,一個比一個輕量。我下面會對近幾年一些具有變革性的工作進行簡單盤點
卷積神經網路訓練三個概念(epoch,迭代次數,batchsize)
總結下訓練神經網路中最最基礎的三個概念:Epoch, Batch, Iteration。 1. 名詞解釋 epoch:訓練時,所有訓練資料集都訓練過一次。 batch_size:在訓練集中選擇一組樣本用來更新權值。1個batch包含的樣本的數目,通常設為2的n次冪,常用
如何確定卷積神經網路的卷積核大小、卷積層數、每層map個數
卷積核大小 卷積層數確定的原則是 長而深,不知道怎麼就選3*3 三層3*3的卷積效果和一層7*7的卷積效果一致,我們知道一次卷積的複雜度是卷積長寬*影象長寬,3次卷積的複雜度為3*(3*3)*影象長寬《(7*7)*影象長寬,既然效果一樣,那當然選多次小卷積啊。 卷積
卷積神經網路 CNN 的細節問題 濾波器的大小選擇
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
卷積神經網路的卷積核的每個通道是否相同?
假設輸入資料的格式是[?,28,28,16],卷積核的尺寸是[3,3,16,32] 輸入資料的格式的含義是: &
變形卷積核、可分離卷積?卷積神經網路中十大拍案叫絕的操作
大家還是去看原文好,作者的文章都不錯: https://zhuanlan.zhihu.com/p/28749411 https://www.zhihu.com/people/professor-ho/posts 一、卷積只能在同一組進行嗎?-- Group convo
3用於MNIST的卷積神經網路-3.4卷積濾波器核的數量與網路效能之間的關係
程式碼: #-*- coding:utf-8 -*- #實現簡單卷積神經網路對MNIST資料集進行分類:conv2d + activation + pool + fc import csv import tensorflow
深度學習:卷積神經網路物體檢測之感受野大小計算
1 感受野的概念 在卷積神經網路中,感受野的定義是 卷積神經網路每一層輸出的特徵圖(feature map)上的畫素點在原始影象上對映的區域大小。 RCNN論文中有一段描述,Alexnet網路pool5輸出的特徵圖上的畫
卷積神經網路池化後的特徵圖大小計算
卷積後的大小 W:矩陣寬,H:矩陣高,F:卷積核寬和高,P:padding(需要填充的0的個數),N:卷積核的個數,S:步長 width:卷積後輸出矩陣的寬,height:卷積後輸出矩陣的高 width = (W - F + 2P)/ S + 1 height = (
卷積神經網路 1*1 卷積核
卷積神經網路中卷積核的作用是提取影象更高維的特徵,一個卷積核代表一種特徵提取方式,對應產生一個特徵圖,卷積核的尺寸對應感受野的大小。 經典的卷積示意圖如下: 5*5的影象使用3*3的卷積核進行卷積,結果產生3*3(5-3+1)的特徵影象。 卷積核的大小一般是(2n+1
卷積神經網路物體檢測之感受野大小計算
學習RCNN系列論文時, 出現了感受野(receptive field)的名詞, 感受野的尺寸大小是如何計算的,在網上沒有搜到特別詳細的介紹, 為了加深印象,記錄下自己對這一感念的理解,希望對理解基於CNN的物體檢測過程有所幫助。1 感受野的概念 在卷積神經網路中,感受野的
一文讀懂卷積神經網路中的1x1卷積核
前言 在介紹卷積神經網路中的1x1卷積之前,首先回顧卷積網路的基本概念[1]。 卷積核(convolutional kernel):可以看作對某個區域性的加權求和;它是對應區域性感知,它的原理是在觀察某個物體時我們既不能觀察每個畫素也不能一次觀察整體,而是
Keras學習(四)——CNN卷積神經網路
本文主要介紹使用keras實現CNN對手寫資料集進行分類。 示例程式碼: import numpy as np from keras.datasets import mnist from keras.utils import np_utils from keras.models impo
深度學習(十九)基於空間金字塔池化的卷積神經網路物體檢測
原文地址:http://blog.csdn.net/hjimce/article/details/50187655 作者:hjimce 一、相關理論 本篇博文主要講解大神何凱明2014年的paper:《Spatial Pyramid Pooling in Dee
淺析卷積神經網路的內部結構
提到卷積神經網路(CNN),很多人的印象可能還停留在黑箱子,輸入資料然後輸出結果的狀態。裡面超級多的引數、眼花繚亂的命名可能讓你無法短時間理解CNN的真正內涵。這裡推薦斯坦福大學的CS231n課程,知乎上有筆記的中文翻譯。如果你需要更淺顯、小白的解釋,可以讀讀看本文。文章大部分理解都源自於CS3
TensorFlow官方文件樣例——三層卷積神經網路訓練MNIST資料
上篇部落格根據TensorFlow官方文件樣例實現了一個簡單的單層神經網路模型,在訓練10000次左右可以達到92.7%左右的準確率。但如果將神經網路的深度拓展,那麼很容易就能夠達到更高的準確率。官方中文文件中就提供了這樣的樣例,它的網路結構如
用TensorFlow訓練卷積神經網路——識別驗證碼
需要用到的包:numpy、tensorflow、captcha、matplotlib、PIL、random import numpy as np import tensorflow as tf # 深度學習庫 from captcha.image import ImageCaptcha
卷積神經網路(CNN)在語音識別中的應用
卷積神經網路(CNN)在語音識別中的應用 作者:侯藝馨 前言 總結目前語音識別的發展現狀,dnn、rnn/lstm和cnn算是語音識別中幾個比較主流的方向。2012年,微軟鄧力和俞棟老師將前饋神經網路FFDNN(Feed Forward Deep Neural Network)引入到聲學模
學習筆記之——基於pytorch的卷積神經網路
本博文為本人的學習筆記。參考材料為《深度學習入門之——PyTorch》 pytorch中文網:https://www.pytorchtutorial.com/ 關於反捲積:https://github.com/vdumoulin/conv_arithmetic/blob/ma