
py-R-FCN原始碼分析
github的地址https://github.com/Orpine/py-R-FCN
這裡以end to end訓練的網路為例,其網路結構定義如下
name: "ResNet-50" layer { name: 'input-data' type: 'Python' top: 'data' top: 'im_info' top: 'gt_boxes' python_param { module: 'roi_data_layer.layer' layer: 'RoIDataLayer' param_str: "'num_classes': 21" } } # ------------------------ conv1 ----------------------------- layer { bottom: "data" top: "conv1" name: "conv1" type: "Convolution" convolution_param { num_output: 64 kernel_size: 7 pad: 3 stride: 2 } param { lr_mult: 0.0 } param { lr_mult: 0.0 } } layer { bottom: "conv1" top: "conv1" name: "bn_conv1" type: "BatchNorm" batch_norm_param { use_global_stats: true } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } } ... ... ... layer { bottom: "res5b" bottom: "res5c_branch2c" top: "res5c" name: "res5c" type: "Eltwise" } layer { bottom: "res5c" top: "res5c" name: "res5c_relu" type: "ReLU" } #========= RPN ============ layer { name: "rpn_conv/3x3" type: "Convolution" bottom: "res4f" top: "rpn/output" param { lr_mult: 1.0 } param { lr_mult: 2.0 } convolution_param { num_output: 512 kernel_size: 3 pad: 1 stride: 1 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "rpn_relu/3x3" type: "ReLU" bottom: "rpn/output" top: "rpn/output" } layer { name: "rpn_cls_score" type: "Convolution" bottom: "rpn/output" top: "rpn_cls_score" param { lr_mult: 1.0 } param { lr_mult: 2.0 } convolution_param { num_output: 18 # 2(bg/fg) * 9(anchors) kernel_size: 1 pad: 0 stride: 1 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "rpn_bbox_pred" type: "Convolution" bottom: "rpn/output" top: "rpn_bbox_pred" param { lr_mult: 1.0 } param { lr_mult: 2.0 } convolution_param { num_output: 36 # 4 * 9(anchors) kernel_size: 1 pad: 0 stride: 1 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { bottom: "rpn_cls_score" top: "rpn_cls_score_reshape" name: "rpn_cls_score_reshape" type: "Reshape" reshape_param { shape { dim: 0 dim: 2 dim: -1 dim: 0 } } } layer { name: 'rpn-data' type: 'Python' bottom: 'rpn_cls_score' bottom: 'gt_boxes' bottom: 'im_info' bottom: 'data' top: 'rpn_labels' top: 'rpn_bbox_targets' top: 'rpn_bbox_inside_weights' top: 'rpn_bbox_outside_weights' python_param { module: 'rpn.anchor_target_layer' layer: 'AnchorTargetLayer' param_str: "'feat_stride': 16" } } layer { name: "rpn_loss_cls" type: "SoftmaxWithLoss" bottom: "rpn_cls_score_reshape" bottom: "rpn_labels" propagate_down: 1 propagate_down: 0 top: "rpn_cls_loss" loss_weight: 1 loss_param { ignore_label: -1 normalize: true } } layer { name: "rpn_loss_bbox" type: "SmoothL1Loss" bottom: "rpn_bbox_pred" bottom: "rpn_bbox_targets" bottom: 'rpn_bbox_inside_weights' bottom: 'rpn_bbox_outside_weights' top: "rpn_loss_bbox" loss_weight: 1 smooth_l1_loss_param { sigma: 3.0 } } #========= RoI Proposal ============ layer { name: "rpn_cls_prob" type: "Softmax" bottom: "rpn_cls_score_reshape" top: "rpn_cls_prob" } layer { name: 'rpn_cls_prob_reshape' type: 'Reshape' bottom: 'rpn_cls_prob' top: 'rpn_cls_prob_reshape' reshape_param { shape { dim: 0 dim: 18 dim: -1 dim: 0 } } } layer { name: 'proposal' type: 'Python' bottom: 'rpn_cls_prob_reshape' bottom: 'rpn_bbox_pred' bottom: 'im_info' top: 'rpn_rois' # top: 'rpn_scores' python_param { module: 'rpn.proposal_layer' layer: 'ProposalLayer' param_str: "'feat_stride': 16" } } #layer { # name: 'debug-data' # type: 'Python' # bottom: 'data' # bottom: 'rpn_rois' # bottom: 'rpn_scores' # python_param { # module: 'rpn.debug_layer' # layer: 'RPNDebugLayer' # } #} layer { name: 'roi-data' type: 'Python' bottom: 'rpn_rois' bottom: 'gt_boxes' top: 'rois' top: 'labels' top: 'bbox_targets' top: 'bbox_inside_weights' top: 'bbox_outside_weights' python_param { module: 'rpn.proposal_target_layer' layer: 'ProposalTargetLayer' param_str: "'num_classes': 2" } } #----------------------new conv layer------------------ layer { bottom: "res5c" top: "conv_new_1" name: "conv_new_1" type: "Convolution" convolution_param { num_output: 1024 kernel_size: 1 pad: 0 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } param { lr_mult: 1.0 } param { lr_mult: 2.0 } } layer { bottom: "conv_new_1" top: "conv_new_1" name: "conv_new_1_relu" type: "ReLU" } layer { bottom: "conv_new_1" top: "rfcn_cls" name: "rfcn_cls" type: "Convolution" convolution_param { num_output: 1029 #21*(7^2) cls_num*(score_maps_size^2) kernel_size: 1 pad: 0 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } param { lr_mult: 1.0 } param { lr_mult: 2.0 } } layer { bottom: "conv_new_1" top: "rfcn_bbox" name: "rfcn_bbox" type: "Convolution" convolution_param { num_output: 392 #8*(7^2) cls_num*(score_maps_size^2) kernel_size: 1 pad: 0 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } param { lr_mult: 1.0 } param { lr_mult: 2.0 } } #--------------position sensitive RoI pooling-------------- layer { bottom: "rfcn_cls" bottom: "rois" top: "psroipooled_cls_rois" name: "psroipooled_cls_rois" type: "PSROIPooling" psroi_pooling_param { spatial_scale: 0.0625 output_dim: 21 group_size: 7 } } layer { bottom: "psroipooled_cls_rois" top: "cls_score" name: "ave_cls_score_rois" type: "Pooling" pooling_param { pool: AVE kernel_size: 7 stride: 7 } } layer { bottom: "rfcn_bbox" bottom: "rois" top: "psroipooled_loc_rois" name: "psroipooled_loc_rois" type: "PSROIPooling" psroi_pooling_param { spatial_scale: 0.0625 output_dim: 8 group_size: 7 } } layer { bottom: "psroipooled_loc_rois" top: "bbox_pred" name: "ave_bbox_pred_rois" type: "Pooling" pooling_param { pool: AVE kernel_size: 7 stride: 7 } } #--------------online hard example mining-------------- layer { name: "per_roi_loss_cls" type: "SoftmaxWithLossOHEM" bottom: "cls_score" bottom: "labels" top: "temp_loss_cls" top: "temp_prob_cls" top: "per_roi_loss_cls" loss_weight: 0 loss_weight: 0 loss_weight: 0 propagate_down: false propagate_down: false } layer { name: "per_roi_loss_bbox" type: "SmoothL1LossOHEM" bottom: "bbox_pred" bottom: "bbox_targets" bottom: "bbox_inside_weights" top: "temp_loss_bbox" top: "per_roi_loss_bbox" loss_weight: 0 loss_weight: 0 propagate_down: false propagate_down: false propagate_down: false } layer { name: "per_roi_loss" type: "Eltwise" bottom: "per_roi_loss_cls" bottom: "per_roi_loss_bbox" top: "per_roi_loss" propagate_down: false propagate_down: false } layer { bottom: "rois" bottom: "per_roi_loss" bottom: "labels" bottom: "bbox_inside_weights" top: "labels_ohem" top: "bbox_loss_weights_ohem" name: "annotator_detector" type: "BoxAnnotatorOHEM" box_annotator_ohem_param { roi_per_img: 128 ignore_label: -1 } propagate_down: false propagate_down: false propagate_down: false propagate_down: false } layer { name: "silence" type: "Silence" bottom: "bbox_outside_weights" bottom: "temp_loss_cls" bottom: "temp_prob_cls" bottom: "temp_loss_bbox" } #-----------------------output------------------------ layer { name: "loss" type: "SoftmaxWithLoss" bottom: "cls_score" bottom: "labels_ohem" top: "loss_cls" loss_weight: 1 loss_param { ignore_label: -1 } propagate_down: true propagate_down: false } layer { name: "accuarcy" type: "Accuracy" bottom: "cls_score" bottom: "labels_ohem" top: "accuarcy" #include: { phase: TEST } accuracy_param { ignore_label: -1 } propagate_down: false propagate_down: false } layer { name: "loss_bbox" type: "SmoothL1LossOHEM" bottom: "bbox_pred" bottom: "bbox_targets" bottom: "bbox_loss_weights_ohem" top: "loss_bbox" loss_weight: 1 loss_param { normalization: PRE_FIXED pre_fixed_normalizer: 128 } propagate_down: true propagate_down: false propagate_down: false }
中間省掉了ResNet-50的部分結構,重點關注RPN、RoI Proposal、new conv layer、position sensitive RoI pooling、online hard example mining這幾個模組。
將網路結構視覺化後如下圖:

圖片比較大,可以下下來看。
RPN、RoI Proposal與faster RCNN裡的RPN、RoI Proposal結構和作用類似,可以看關於faster RCNN的介紹。
new conv layer
其中用到了1X1的卷積,它的作用下面給出瞭解釋
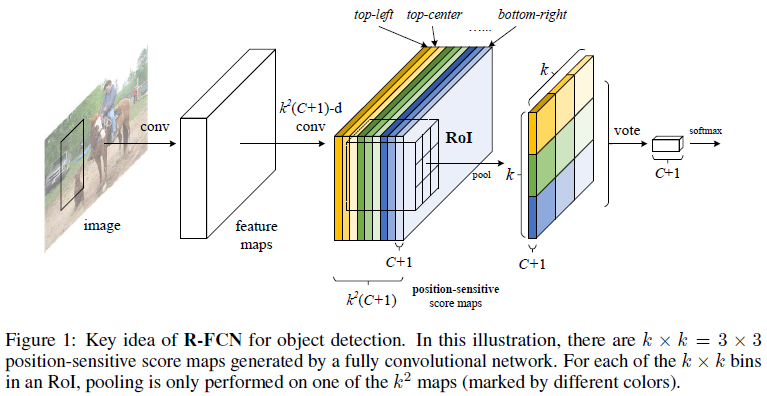
經過這一模組的卷積後,生成了位置敏感得分圖,如上圖每一類會得到3X3個數的位置敏感得分圖,比如橙色圖就只對這一類目標的左上角區域有較大的響應。
使用的都是普通的卷基層,這些卷積核的引數在訓練中不斷調整,最終可以訓練出對某一類目標的不同位置敏感的卷積核。
position sensitive RoI pooling
對於該層進行的操作,請看下面的示意圖
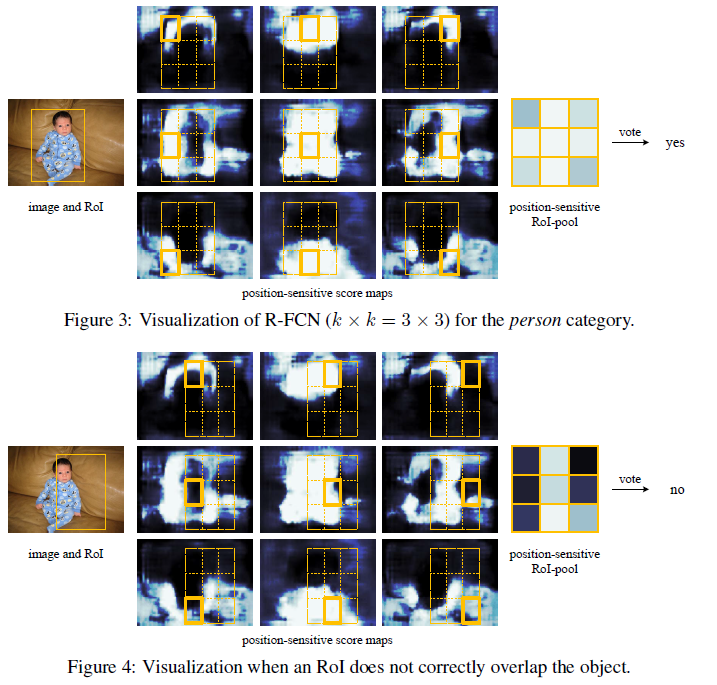
上圖psroi_pooling將roi分成3X3的bin,然後每個bin對映到相應的位置敏感得分圖上相應的位置,最終roi每一類的9個bin可以從這一類的9張位置敏感得分圖摳出來的相應區塊拼接而成。最後pooling得到這一類的得分,這個得分可以直接接softmax進行分類
psroi_pooling_layer.cpp
// ------------------------------------------------------------------ // R-FCN // Written by Yi Li // ------------------------------------------------------------------ #include <cfloat> #include <string> #include <utility> #include <vector> #include "caffe/layers/psroi_pooling_layer.hpp" using std::max; using std::min; using std::floor; using std::ceil; namespace caffe { template <typename Dtype> void PSROIPoolingLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { PSROIPoolingParameter psroi_pooling_param = this->layer_param_.psroi_pooling_param(); spatial_scale_ = psroi_pooling_param.spatial_scale(); LOG(INFO) << "Spatial scale: " << spatial_scale_; CHECK_GT(psroi_pooling_param.output_dim(), 0) << "output_dim must be > 0"; CHECK_GT(psroi_pooling_param.group_size(), 0) << "group_size must be > 0"; output_dim_ = psroi_pooling_param.output_dim(); group_size_ = psroi_pooling_param.group_size(); pooled_height_ = group_size_; pooled_width_ = group_size_; } template <typename Dtype> void PSROIPoolingLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { channels_ = bottom[0]->channels(); CHECK_EQ(channels_, output_dim_*group_size_*group_size_) << "input channel number does not match layer parameters"; height_ = bottom[0]->height(); width_ = bottom[0]->width(); top[0]->Reshape( bottom[1]->num(), output_dim_, pooled_height_, pooled_width_); mapping_channel_.Reshape( bottom[1]->num(), output_dim_, pooled_height_, pooled_width_); } template <typename Dtype> void PSROIPoolingLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { NOT_IMPLEMENTED; } template <typename Dtype> void PSROIPoolingLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) { NOT_IMPLEMENTED; } #ifdef CPU_ONLY STUB_GPU(PSROIPoolingLayer); #endif INSTANTIATE_CLASS(PSROIPoolingLayer); REGISTER_LAYER_CLASS(PSROIPooling); } // namespace caffe
psroi_pooling_layer.cu
// --------------------------------------------------------
// R-FCN
// Written by Yi Li, 2016.
// --------------------------------------------------------
#include <algorithm>
#include <cfloat>
#include <vector>
#include "caffe/layers/psroi_pooling_layer.hpp"
#include "caffe/util/gpu_util.cuh"
using std::max;
using std::min;
namespace caffe {
template <typename Dtype>
__global__ void PSROIPoolingForward(
const int nthreads,
const Dtype* bottom_data,
const Dtype spatial_scale,
const int channels,
const int height, const int width,
const int pooled_height, const int pooled_width,
const Dtype* bottom_rois,
const int output_dim,
const int group_size,
Dtype* top_data,
int* mapping_channel) {
CUDA_KERNEL_LOOP(index, nthreads) {
// The output is in order (n, ctop, ph, pw)
int pw = index % pooled_width;
int ph = (index / pooled_width) % pooled_height;
int ctop = (index / pooled_width / pooled_height) % output_dim;
int n = index / pooled_width / pooled_height / output_dim;
// [start, end) interval for spatial sampling
bottom_rois += n * 5;
int roi_batch_ind = bottom_rois[0];
Dtype roi_start_w =
static_cast<Dtype>(round(bottom_rois[1])) * spatial_scale;
Dtype roi_start_h =
static_cast<Dtype>(round(bottom_rois[2])) * spatial_scale;
Dtype roi_end_w =
static_cast<Dtype>(round(bottom_rois[3]) + 1.) * spatial_scale;
Dtype roi_end_h =
static_cast<Dtype>(round(bottom_rois[4]) + 1.) * spatial_scale;
// Force too small ROIs to be 1x1
Dtype roi_width = max(roi_end_w - roi_start_w, 0.1); // avoid 0
Dtype roi_height = max(roi_end_h - roi_start_h, 0.1);
// Compute w and h at bottom
Dtype bin_size_h = roi_height / static_cast<Dtype>(pooled_height);
Dtype bin_size_w = roi_width / static_cast<Dtype>(pooled_width);
int hstart = floor(static_cast<Dtype>(ph) * bin_size_h
+ roi_start_h);
int wstart = floor(static_cast<Dtype>(pw)* bin_size_w
+ roi_start_w);
int hend = ceil(static_cast<Dtype>(ph + 1) * bin_size_h
+ roi_start_h);
int wend = ceil(static_cast<Dtype>(pw + 1) * bin_size_w
+ roi_start_w);
// Add roi offsets and clip to input boundaries
hstart = min(max(hstart, 0), height);
hend = min(max(hend, 0), height);
wstart = min(max(wstart, 0), width);
wend = min(max(wend, 0), width);
bool is_empty = (hend <= hstart) || (wend <= wstart);
int gw = pw;
int gh = ph;
int c = (ctop*group_size + gh)*group_size + gw;
bottom_data += (roi_batch_ind * channels + c) * height * width;
Dtype out_sum = 0;
for (int h = hstart; h < hend; ++h) {
for (int w = wstart; w < wend; ++w) {
int bottom_index = h*width + w;
out_sum += bottom_data[bottom_index];
}
}
Dtype bin_area = (hend - hstart)*(wend - wstart);
top_data[index] = is_empty? 0. : out_sum/bin_area;
mapping_channel[index] = c;
}
}
template <typename Dtype>
void PSROIPoolingLayer<Dtype>::Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->gpu_data();
const Dtype* bottom_rois = bottom[1]->gpu_data();
Dtype* top_data = top[0]->mutable_gpu_data();
int* mapping_channel_ptr = mapping_channel_.mutable_gpu_data();
int count = top[0]->count();
caffe_gpu_set(count, Dtype(0), top_data);
caffe_gpu_set(count, -1, mapping_channel_ptr);
// NOLINT_NEXT_LINE(whitespace/operators)
PSROIPoolingForward<Dtype> << <CAFFE_GET_BLOCKS(count),
CAFFE_CUDA_NUM_THREADS >> >(count, bottom_data, spatial_scale_,
channels_, height_, width_, pooled_height_,
pooled_width_, bottom_rois, output_dim_, group_size_,
top_data, mapping_channel_ptr);
CUDA_POST_KERNEL_CHECK;
}
template <typename Dtype>
__global__ void PSROIPoolingBackwardAtomic(
const int nthreads,
const Dtype* top_diff,
const int* mapping_channel,
const int num_rois,
const Dtype spatial_scale,
const int channels,
const int height, const int width,
const int pooled_height, const int pooled_width,
const int output_dim,
Dtype* bottom_diff,
const Dtype* bottom_rois) {
CUDA_KERNEL_LOOP(index, nthreads) {
// The output is in order (n, ctop, ph, pw)
int pw = index % pooled_width;
int ph = (index / pooled_width) % pooled_height;
int n = index / pooled_width / pooled_height / output_dim;
// [start, end) interval for spatial sampling
bottom_rois += n * 5;
int roi_batch_ind = bottom_rois[0];
Dtype roi_start_w =
static_cast<Dtype>(round(bottom_rois[1])) * spatial_scale;
Dtype roi_start_h =
static_cast<Dtype>(round(bottom_rois[2])) * spatial_scale;
Dtype roi_end_w =
static_cast<Dtype>(round(bottom_rois[3]) + 1.) * spatial_scale;
Dtype roi_end_h =
static_cast<Dtype>(round(bottom_rois[4]) + 1.) * spatial_scale;
// Force too small ROIs to be 1x1
Dtype roi_width = max(roi_end_w - roi_start_w, 0.1); // avoid 0
Dtype roi_height = max(roi_end_h - roi_start_h, 0.1);
// Compute w and h at bottom
Dtype bin_size_h = roi_height / static_cast<Dtype>(pooled_height);
Dtype bin_size_w = roi_width / static_cast<Dtype>(pooled_width);
int hstart = floor(static_cast<Dtype>(ph)* bin_size_h
+ roi_start_h);
int wstart = floor(static_cast<Dtype>(pw)* bin_size_w
+ roi_start_w);
int hend = ceil(static_cast<Dtype>(ph + 1) * bin_size_h
+ roi_start_h);
int wend = ceil(static_cast<Dtype>(pw + 1) * bin_size_w
+ roi_start_w);
// Add roi offsets and clip to input boundaries
hstart = min(max(hstart, 0), height);
hend = min(max(hend, 0), height);
wstart = min(max(wstart, 0), width);
wend = min(max(wend, 0), width);
bool is_empty = (hend <= hstart) || (wend <= wstart);
// Compute c at bottom
int c = mapping_channel[index];
Dtype* offset_bottom_diff = bottom_diff +
(roi_batch_ind * channels + c) * height * width;
Dtype bin_area = (hend - hstart)*(wend - wstart);
Dtype diff_val = is_empty ? 0. : top_diff[index] / bin_area;
for (int h = hstart; h < hend; ++h) {
for (int w = wstart; w < wend; ++w) {
int bottom_index = h*width + w;
caffe_gpu_atomic_add(diff_val, offset_bottom_diff + bottom_index);
}
}
}
}
template <typename Dtype>
void PSROIPoolingLayer<Dtype>::Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {
if (!propagate_down[0]) {
return;
}
const Dtype* bottom_rois = bottom[1]->gpu_data();
const Dtype* top_diff = top[0]->gpu_diff();
Dtype* bottom_diff = bottom[0]->mutable_gpu_diff();
const int bottom_count = bottom[0]->count();
const int* mapping_channel_ptr = mapping_channel_.gpu_data();
caffe_gpu_set(bottom[1]->count(), Dtype(0), bottom[1]->mutable_gpu_diff());
caffe_gpu_set(bottom_count, Dtype(0), bottom_diff);
const int count = top[0]->count();
// NOLINT_NEXT_LINE(whitespace/operators)
PSROIPoolingBackwardAtomic<Dtype> << <CAFFE_GET_BLOCKS(count),
CAFFE_CUDA_NUM_THREADS >> >(count, top_diff, mapping_channel_ptr,
top[0]->num(), spatial_scale_, channels_, height_, width_,
pooled_height_, pooled_width_, output_dim_, bottom_diff,
bottom_rois);
CUDA_POST_KERNEL_CHECK;
}
INSTANTIATE_LAYER_GPU_FUNCS(PSROIPoolingLayer);
} // namespace caffe
online hard example mining
softmax_loss_ohem_layer.cpp
#include <algorithm>
#include <cfloat>
#include <vector>
#include "caffe/layers/softmax_loss_ohem_layer.hpp"
#include "caffe/util/math_functions.hpp"
namespace caffe {
template <typename Dtype>
void SoftmaxWithLossOHEMLayer<Dtype>::LayerSetUp(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
LossLayer<Dtype>::LayerSetUp(bottom, top);
LayerParameter softmax_param(this->layer_param_);
// Fix a bug which occurs with more than one output
softmax_param.clear_loss_weight();
softmax_param.set_type("Softmax");
softmax_layer_ = LayerRegistry<Dtype>::CreateLayer(softmax_param);
softmax_bottom_vec_.clear();
softmax_bottom_vec_.push_back(bottom[0]);
softmax_top_vec_.clear();
softmax_top_vec_.push_back(&prob_);
softmax_layer_->SetUp(softmax_bottom_vec_, softmax_top_vec_);
has_ignore_label_ =
this->layer_param_.loss_param().has_ignore_label();
if (has_ignore_label_) {
ignore_label_ = this->layer_param_.loss_param().ignore_label();
}
if (!this->layer_param_.loss_param().has_normalization() &&
this->layer_param_.loss_param().has_normalize()) {
normalization_ = this->layer_param_.loss_param().normalize() ?
LossParameter_NormalizationMode_VALID :
LossParameter_NormalizationMode_BATCH_SIZE;
} else {
normalization_ = this->layer_param_.loss_param().normalization();
}
}
template <typename Dtype>
void SoftmaxWithLossOHEMLayer<Dtype>::Reshape(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
LossLayer<Dtype>::Reshape(bottom, top);
softmax_layer_->Reshape(softmax_bottom_vec_, softmax_top_vec_);
softmax_axis_ =
bottom[0]->CanonicalAxisIndex(this->layer_param_.softmax_param().axis());
outer_num_ = bottom[0]->count(0, softmax_axis_);
inner_num_ = bottom[0]->count(softmax_axis_ + 1);
CHECK_EQ(outer_num_ * inner_num_, bottom[1]->count())
<< "Number of labels must match number of predictions; "
<< "e.g., if softmax axis == 1 and prediction shape is (N, C, H, W), "
<< "label count (number of labels) must be N*H*W, "
<< "with integer values in {0, 1, ..., C-1}.";
if (top.size() >= 2) {
// softmax output
top[1]->ReshapeLike(*bottom[0]);
}
// top[2] stores per-instance loss, which takes the shape of N*1*H*W
if (top.size() >= 3) {
top[2]->ReshapeLike(*bottom[1]);
}
}
template <typename Dtype>
Dtype SoftmaxWithLossOHEMLayer<Dtype>::get_normalizer(
LossParameter_NormalizationMode normalization_mode, int valid_count) {
Dtype normalizer;
switch (normalization_mode) {
case LossParameter_NormalizationMode_FULL:
normalizer = Dtype(outer_num_ * inner_num_);
break;
case LossParameter_NormalizationMode_VALID:
if (valid_count == -1) {
normalizer = Dtype(outer_num_ * inner_num_);
} else {
normalizer = Dtype(valid_count);
}
break;
case LossParameter_NormalizationMode_BATCH_SIZE:
normalizer = Dtype(outer_num_);
break;
case LossParameter_NormalizationMode_NONE:
normalizer = Dtype(1);
break;
default:
LOG(FATAL) << "Unknown normalization mode: "
<< LossParameter_NormalizationMode_Name(normalization_mode);
}
// Some users will have no labels for some examples in order to 'turn off' a
// particular loss in a multi-task setup. The max prevents NaNs in that case.
return std::max(Dtype(1.0), normalizer);
}
template <typename Dtype>
void SoftmaxWithLossOHEMLayer<Dtype>::Forward_cpu(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
NOT_IMPLEMENTED;
}
template <typename Dtype>
void SoftmaxWithLossOHEMLayer<Dtype>::Backward_cpu(
const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
NOT_IMPLEMENTED;
}
#ifdef CPU_ONLY
STUB_GPU(SoftmaxWithLossOHEMLayer);
#endif
INSTANTIATE_CLASS(SoftmaxWithLossOHEMLayer);
REGISTER_LAYER_CLASS(SoftmaxWithLossOHEM);
} // namespace caffe
softmax_loss_ohem_layer.cu
#include <algorithm>
#include <cfloat>
#include <vector>
#include "caffe/layers/softmax_loss_ohem_layer.hpp"
#include "caffe/util/math_functions.hpp"
namespace caffe {
template <typename Dtype>
__global__ void SoftmaxLossForwardGPU(const int nthreads,
const Dtype* prob_data, const Dtype* label, Dtype* loss,
const int num, const int dim, const int spatial_dim,
const bool has_ignore_label_, const int ignore_label_,
Dtype* counts) {
CUDA_KERNEL_LOOP(index, nthreads) {
const int n = index / spatial_dim;
const int s = index % spatial_dim;
const int label_value = static_cast<int>(label[n * spatial_dim + s]);
if (has_ignore_label_ && label_value == ignore_label_) {
loss[index] = 0;
counts[index] = 0;
} else {
loss[index] = -log(max(prob_data[n * dim + label_value * spatial_dim + s],
Dtype(FLT_MIN)));
counts[index] = 1;
}
}
}
template <typename Dtype>
void SoftmaxWithLossOHEMLayer<Dtype>::Forward_gpu(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
softmax_layer_->Forward(softmax_bottom_vec_, softmax_top_vec_);
const Dtype* prob_data = prob_.gpu_data();
const Dtype* label = bottom[1]->gpu_data();
const int dim = prob_.count() / outer_num_;
const int nthreads = outer_num_ * inner_num_;
// Since this memory is not used for anything until it is overwritten
// on the backward pass, we use it here to avoid having to allocate new GPU
// memory to accumulate intermediate results in the kernel.
Dtype* loss_data = bottom[0]->mutable_gpu_diff();
// Similarly, this memory is never used elsewhere, and thus we can use it
// to avoid having to allocate additional GPU memory.
Dtype* counts = prob_.mutable_gpu_diff();
// NOLINT_NEXT_LINE(whitespace/operators)
SoftmaxLossForwardGPU<Dtype><<<CAFFE_GET_BLOCKS(nthreads),
CAFFE_CUDA_NUM_THREADS>>>(nthreads, prob_data, label, loss_data,
outer_num_, dim, inner_num_, has_ignore_label_, ignore_label_, counts);
Dtype loss;
caffe_gpu_asum(nthreads, loss_data, &loss);
Dtype valid_count = -1;
// Only launch another CUDA kernel if we actually need the count of valid
// outputs.
if (normalization_ == LossParameter_NormalizationMode_VALID &&
has_ignore_label_) {
caffe_gpu_asum(nthreads, counts, &valid_count);
}
top[0]->mutable_cpu_data()[0] = loss / get_normalizer(normalization_,
valid_count);
if (top.size() >= 2) {
top[1]->ShareData(prob_);
}
if (top.size() >= 3) {
// Output per-instance loss
caffe_gpu_memcpy(top[2]->count() * sizeof(Dtype), loss_data,
top[2]->mutable_gpu_data());
}
// Fix a bug, which happens when propagate_down[0] = false in backward
caffe_gpu_set(bottom[0]->count(), Dtype(0), bottom[0]->mutable_gpu_diff());
}
template <typename Dtype>
__global__ void SoftmaxLossBackwardGPU(const int nthreads, const Dtype* top,
const Dtype* label, Dtype* bottom_diff, const int num, const int dim,
const int spatial_dim, const bool has_ignore_label_,
const int ignore_label_, Dtype* counts) {
const int channels = dim / spatial_dim;
CUDA_KERNEL_LOOP(index, nthreads) {
const int n = index / spatial_dim;
const int s = index % spatial_dim;
const int label_value = static_cast<int>(label[n * spatial_dim + s]);
if (has_ignore_label_ && label_value == ignore_label_) {
for (int c = 0; c < channels; ++c) {
bottom_diff[n * dim + c * spatial_dim + s] = 0;
}
counts[index] = 0;
} else {
bottom_diff[n * dim + label_value * spatial_dim + s] -= 1;
counts[index] = 1;
}
}
}
template <typename Dtype>
void SoftmaxWithLossOHEMLayer<Dtype>::Backward_gpu(
const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
if (propagate_down[1]) {
LOG(FATAL) << this->type()
<< " Layer cannot backpropagate to label inputs.";
}
if (propagate_down[0]) {
Dtype* bottom_diff = bottom[0]->mutable_gpu_diff();
const Dtype* prob_data = prob_.gpu_data();
const Dtype* top_data = top[0]->gpu_data();
caffe_gpu_memcpy(prob_.count() * sizeof(Dtype), prob_data, bottom_diff);
const Dtype* label = bottom[1]->gpu_data();
const int dim = prob_.count() / outer_num_;
const int nthreads = outer_num_ * inner_num_;
// Since this memory is never used for anything else,
// we use to to avoid allocating new GPU memory.
Dtype* counts = prob_.mutable_gpu_diff();
// NOLINT_NEXT_LINE(whitespace/operators)
SoftmaxLossBackwardGPU<Dtype><<<CAFFE_GET_BLOCKS(nthreads),
CAFFE_CUDA_NUM_THREADS>>>(nthreads, top_data, label, bottom_diff,
outer_num_, dim, inner_num_, has_ignore_label_, ignore_label_, counts);
Dtype valid_count = -1;
// Only launch another CUDA kernel if we actually need the count of valid
// outputs.
if (normalization_ == LossParameter_NormalizationMode_VALID &&
has_ignore_label_) {
caffe_gpu_asum(nthreads, counts, &valid_count);
}
const Dtype loss_weight = top[0]->cpu_diff()[0] /
get_normalizer(normalization_, valid_count);
caffe_gpu_scal(prob_.count(), loss_weight , bottom_diff);
}
}
INSTANTIATE_LAYER_GPU_FUNCS(SoftmaxWithLossOHEMLayer);
} // namespace caffe
smooth_L1_loss_ohem_layer.cu
// --------------------------------------------------------
// R-FCN
// Written by Yi Li, 2016.
// --------------------------------------------------------
#include <algorithm>
#include <cfloat>
#include <vector>
#include "thrust/device_vector.h"
#include "caffe/layers/smooth_l1_loss_ohem_layer.hpp"
#include "caffe/util/math_functions.hpp"
namespace caffe {
template <typename Dtype>
__global__ void SmoothL1ForwardGPU(const int n, const Dtype* in, Dtype* out) {
// f(x) = 0.5 * x^2 if |x| < 1
// |x| - 0.5 otherwise
CUDA_KERNEL_LOOP(index, n) {
Dtype val = in[index];
Dtype abs_val = abs(val);
if (abs_val < 1) {
out[index] = 0.5 * val * val;
} else {
out[index] = abs_val - 0.5;
}
}
}
template <typename Dtype>
__global__ void kernel_channel_sum(const int num, const int channels,
const int spatial_dim, const Dtype* data, Dtype* channel_sum) {
CUDA_KERNEL_LOOP(index, num * spatial_dim) {
int n = index / spatial_dim;
int s = index % spatial_dim;
Dtype sum = 0;
for (int c = 0; c < channels; ++c) {
sum += data[(n * channels + c) * spatial_dim + s];
}
channel_sum[index] = sum;
}
}
template <typename Dtype>
void SmoothL1LossOHEMLayer<Dtype>::Forward_gpu(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
int count = bottom[0]->count();
caffe_gpu_sub(
count,
bottom[0]->gpu_data(),
bottom[1]->gpu_data(),
diff_.mutable_gpu_data()); // d := b0 - b1
if (has_weights_) {
caffe_gpu_mul(
count,
bottom[2]->gpu_data(),
diff_.gpu_data(),
diff_.mutable_gpu_data()); // d := w * (b0 - b1)
}
SmoothL1ForwardGPU<Dtype> << <CAFFE_GET_BLOCKS(count),
CAFFE_CUDA_NUM_THREADS >> >(count, diff_.gpu_data(),
errors_.mutable_gpu_data());
CUDA_POST_KERNEL_CHECK;
Dtype loss;
caffe_gpu_asum(count, errors_.gpu_data(), &loss);
int spatial_dim = diff_.height() * diff_.width();
Dtype pre_fixed_normalizer =
this->layer_param_.loss_param().pre_fixed_normalizer();
top[0]->mutable_cpu_data()[0] = loss / get_normalizer(normalization_,
pre_fixed_normalizer);
// Output per-instance loss
if (top.size() >= 2) {
kernel_channel_sum<Dtype> << <CAFFE_GET_BLOCKS(top[1]->count()),
CAFFE_CUDA_NUM_THREADS >> > (outer_num_, bottom[0]->channels(),
inner_num_, errors_.gpu_data(), top[1]->mutable_gpu_data());
}
}
template <typename Dtype>
__global__ void SmoothL1BackwardGPU(
const int n, const Dtype* in, Dtype* out) {
// f'(x) = x if |x| < 1
// = sign(x) otherwise
CUDA_KERNEL_LOOP(index, n) {
Dtype val = in[index];
Dtype abs_val = abs(val);
if (abs_val < 1) {
out[index] = val;
} else {
out[index] = (Dtype(0) < val) - (val < Dtype(0));
}
}
}
template <typename Dtype>
void SmoothL1LossOHEMLayer<Dtype>::Backward_gpu(
const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
int count = diff_.count();
SmoothL1BackwardGPU<Dtype> << <CAFFE_GET_BLOCKS(count),
CAFFE_CUDA_NUM_THREADS >> >(count, diff_.gpu_data(),
diff_.mutable_gpu_data());
CUDA_POST_KERNEL_CHECK;
for (int i = 0; i < 2; ++i) {
if (propagate_down[i]) {
const Dtype sign = (i == 0) ? 1 : -1;
int spatial_dim = diff_.height() * diff_.width();
Dtype pre_fixed_normalizer =
this->layer_param_.loss_param().pre_fixed_normalizer();
Dtype normalizer = get_normalizer(normalization_, pre_fixed_normalizer);
Dtype alpha = sign * top[0]->cpu_diff()[0] / normalizer;
caffe_gpu_axpby(
bottom[i]->count(), // count
alpha, // alpha
diff_.gpu_data(), // x
Dtype(0), // beta
bottom[i]->mutable_gpu_diff()); // y
}
}
}
INSTANTIATE_LAYER_GPU_FUNCS(SmoothL1LossOHEMLayer);
} // namespace caffe
box_annotator_ohem_layer.cpp
// ------------------------------------------------------------------
// R-FCN
// Written by Yi Li
// ------------------------------------------------------------------
#include <cfloat>
#include <string>
#include <utility>
#include <vector>
#include "caffe/blob.hpp"
#include "caffe/common.hpp"
#include "caffe/layer.hpp"
#include "caffe/layers/box_annotator_ohem_layer.hpp"
#include "caffe/proto/caffe.pb.h"
using std::max;
using std::min;
using std::floor;
using std::ceil;
namespace caffe {
template <typename Dtype>
void BoxAnnotatorOHEMLayer<Dtype>::LayerSetUp(
const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
BoxAnnotatorOHEMParameter box_anno_param =
this->layer_param_.box_annotator_ohem_param();
roi_per_img_ = box_anno_param.roi_per_img();
CHECK_GT(roi_per_img_, 0);
ignore_label_ = box_anno_param.ignore_label();
}
template <typename Dtype>
void BoxAnnotatorOHEMLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
num_ = bottom[0]->num();
CHECK_EQ(5, bottom[0]->channels());
height_ = bottom[0]->height();
width_ = bottom[0]->width();
spatial_dim_ = height_*width_;
CHECK_EQ(bottom[1]->num(), num_);
CHECK_EQ(bottom[1]->channels(), 1);
CHECK_EQ(bottom[1]->height(), height_);
CHECK_EQ(bottom[1]->width(), width_);
CHECK_EQ(bottom[2]->num(), num_);
CHECK_EQ(bottom[2]->channels(), 1);
CHECK_EQ(bottom[2]->height(), height_);
CHECK_EQ(bottom[2]->width(), width_);
CHECK_EQ(bottom[3]->num(), num_);
bbox_channels_ = bottom[3]->channels();
CHECK_EQ(bottom[3]->height(), height_);
CHECK_EQ(bottom[3]->width(), width_);
// Labels for scoring
top[0]->Reshape(num_, 1, height_, width_);
// Loss weights for bbox regression
top[1]->Reshape(num_, bbox_channels_, height_, width_);
}
template <typename Dtype>
void BoxAnnotatorOHEMLayer<Dtype>::Forward_cpu(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
NOT_IMPLEMENTED;
}
template <typename Dtype>
void BoxAnnotatorOHEMLayer<Dtype>::Backward_cpu(
const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
NOT_IMPLEMENTED;
}
#ifdef CPU_ONLY
STUB_GPU(BoxAnnotatorOHEMLayer);
#endif
INSTANTIATE_CLASS(BoxAnnotatorOHEMLayer);
REGISTER_LAYER_CLASS(BoxAnnotatorOHEM);
} // namespace caffe
box_annotator_ohem_layer.cu
// ------------------------------------------------------------------
// R-FCN
// Written by Yi Li
// ------------------------------------------------------------------
#include <algorithm>
#include <cfloat>
#include <vector>
#include "caffe/layers/box_annotator_ohem_layer.hpp"
using std::max;
using std::min;
namespace caffe {
template <typename Dtype>
void BoxAnnotatorOHEMLayer<Dtype>::Forward_gpu(
const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_rois = bottom[0]->cpu_data();
const Dtype* bottom_loss = bottom[1]->cpu_data();
const Dtype* bottom_labels = bottom[2]->cpu_data();
const Dtype* bottom_bbox_loss_weights = bottom[3]->cpu_data();
Dtype* top_labels = top[0]->mutable_cpu_data();
Dtype* top_bbox_loss_weights = top[1]->mutable_cpu_data();
caffe_set(top[0]->count(), Dtype(ignore_label_), top_labels);
caffe_set(top[1]->count(), Dtype(0), top_bbox_loss_weights);
int num_rois_ = bottom[1]->count();
int num_imgs = -1;
for (int n = 0; n < num_rois_; n++) {
for (int s = 0; s < spatial_dim_; s++) {
num_imgs = bottom_rois[0] > num_imgs ? bottom_rois[0] : num_imgs;
bottom_rois++;
}
bottom_rois += (5-1)*spatial_dim_;
}
num_imgs++;
CHECK_GT(num_imgs, 0)
<< "number of images must be greater than 0 at BoxAnnotatorOHEMLayer";
bottom_rois = bottom[0]->cpu_data();
// Find rois with max loss
vector<int> sorted_idx(num_rois_);
for (int i = 0; i < num_rois_; i++) {
sorted_idx[i] = i;
}
std::sort(sorted_idx.begin(), sorted_idx.end(),
[bottom_loss](int i1, int i2) {
return bottom_loss[i1] > bottom_loss[i2];
});
// Generate output labels for scoring and loss_weights for bbox regression
vector<int> number_left(num_imgs, roi_per_img_);
for (int i = 0; i < num_rois_; i++) {
int index = sorted_idx[i];
int s = index % (width_*height_);
int n = index / (width_*height_);
int batch_ind = bottom_rois[n*5*spatial_dim_+s];
if (number_left[batch_ind] > 0) {
number_left[batch_ind]--;
top_labels[index] = bottom_labels[index];
for (int j = 0; j < bbox_channels_; j++) {
int bbox_index = (n*bbox_channels_+j)*spatial_dim_+s;
top_bbox_loss_weights[bbox_index] =
bottom_bbox_loss_weights[bbox_index];
}
}
}
}
template <typename Dtype>
void BoxAnnotatorOHEMLayer<Dtype>::Backward_gpu(
const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
return;
}
INSTANTIATE_LAYER_GPU_FUNCS(BoxAnnotatorOHEMLayer);
} // namespace caffe
相關推薦
py-R-FCN原始碼分析
github的地址https://github.com/Orpine/py-R-FCN 這裡以end to end訓練的網路為例,其網路結構定義如下 name: "ResNet-50" layer { name: 'input-data' type: 'Py
py-R-FCN的caffe配置(轉)
參考:https://blog.csdn.net/wei_guo_xd/article/details/74451443 下載程式,git clone https://github.com/Orpine/py-R-FCN.git開啟py-R-FCN,下載caffegit clone http
R-FCN在linux下的配置(py-R-FCN)並訓練自己的資料集
本文是R-FCN程式碼的python版原始碼配置,作業系統為Ubuntu16.04R-FCN: Object Detection via Region-based Fully Convolutional Networks,與先前的基於區域的檢測器(諸如Fast/Faster
搭建及訓練py-R-FCN遇到的問題
搭建py-R-FCN遇到的問題記錄。 make pycaffe 報錯 [html] view plain copy src/caffe/layers/box_annotator_ohem_layer.cu(49): error: a template argumen
分享《R語言資料分析與挖掘實戰(張良均等)》中文PDF+原始碼
下載:https://pan.baidu.com/s/1I7hm-LP5H3-57vsUjOxeNw 更多資料分享:https://pan.baidu.com/s/1g4hv05UZ_w92uh9NNNkCaA 《R語言資料分析與挖掘實戰(張良均等)》PDF+原始碼 PDF,339頁。 配套資料與原始
FCN原始碼解讀之solve.py
solve.py是FCN中解決方案檔案,即通過執行solve.py檔案可以實現FCN模型的訓練和測試過程。以下拿voc-fcn32s資料夾裡的solve.py舉例分析。 一、原始碼及分析如下: #coding=utf-8 import caffe import surgery, score i
web.py原始碼分析: application
本文主要分析的是web.py庫的 application.py 這個模組中的程式碼。總的來說, 這個模組主要實現了WSGI相容的介面,以便應用程式能夠被WSGI應用伺服器呼叫 。WSGI是 Web Server Gat
TensorFlow學習筆記之原始碼分析(3)---- retrain.py
"""簡單呼叫Inception V3架構模型的學習在tensorboard顯示了摘要。 這個例子展示瞭如何採取一個Inception V3架構模型訓練ImageNet影象和訓練新的頂層,可以識別其他類的影象。 每個影象裡,頂層接收作為輸入的一個2048維向量。這
FCN原始碼解讀之score.py
score.py是FCN中用於測試測試集/驗證集的,並輸出相應的畫素準確度、平均準確度、mean IU和頻率加權交併比(frequency weighted IU)四個指標的python檔案。score.py的原始碼如下:from __future__ import divi
Scrapy-Redis分散式的原理原始碼分析R
Scrapy Scrapy是一個比較好用的Python爬蟲框架,你只需要編寫幾個元件就可以實現網頁資料的爬取。但是當我們要爬取的頁面非常多的時候,單個主機的處理能力就不能滿足我們的需求了(無論是處理速度還是網路請求的併發數),這時候分散式爬蟲的優勢就顯現出來。 而Scra
R語言統計分析技術研究——嶺回歸技術的原理和應用
gts 根據 誤差 med 分享 jce not -c rt4 嶺回歸技術的原理和應用
R-FCN:基於區域的全卷積網絡來檢測物體
速度慢 obj ogl ott 不用 插入 編碼 邊框 sco http://blog.csdn.net/shadow_guo/article/details/51767036 原文標題為“R-FCN: Object Detection via Region-based F
R語言關聯分析之啤酒和尿布
mea mar 簡單 active 兩個 mark 情況 rgb efault 關聯分析概述啤酒和尿布的故事,我估計大家都聽過,這是數據挖掘裏面最經典的案例之一。它分析的方法就關聯分析。關聯分析,顧名思義,就是研究不同商品之前的關系。這裏就發現了啤酒和尿布這兩個看起來毫不相
基於R進行相關性分析--轉載
使用 型號 num blue 計算 散點 heatmap mat end https://www.cnblogs.com/fanling999/p/5857122.html 一、相關性矩陣計算: [1] 加載數據: >data = read.csv("231-6
R語言︱情感分析—詞典型代碼實踐(最基礎)(一)
text cto 關於 ora 訓練集 其他 查找 rap boa R語言︱情感分析—基於監督算法R語言實現筆記。 可以與博客 R語言︱詞典型情感分析文本操作技巧匯總(打標簽、詞典與數據匹配等)對著看。 詞典型情感分析大致有以下幾個步驟: 訓練數據集、neg/pos情感
R: 聚類分析
.net 註意 們的 每次 應用領域 str 就是 比較 記錄 判別與聚類的比較: 聚類分析和判別分析有相似的作用,都是起到分類的作用。 判別分析是已知分類然後總結出判別規則,是一種有指導的學習; 聚類分析則是有了一批樣本,不知道它們的分類,甚至連分成幾類也不知道,希望用某
R-基本統計分析--描述性統計分析
及其 pre dice 數據集 returns length 平均值 sun 52.0 描述性統計分析主要包括 基本信息:樣本數、總和 集中趨勢:均值、中位數、眾數 離散趨勢:方差(標準差)、變異系數、全距(最小值、最大值)、內四分位距(25%分位數、75%分位數) 分布
mybatis原理,配置介紹及原始碼分析
前言 mybatis核心元件有哪些?它是工作原理是什麼? mybatis配置檔案各個引數是什麼含義? mybatis只添加了介面類,沒有實現類,為什麼可以直接查詢呢? mybatis的mapper對映檔案各個引數又是什麼含義? mybatis-spring提供哪些機制簡化了原生mybatis? m
Spark原始碼分析之Spark Shell(上)
https://www.cnblogs.com/xing901022/p/6412619.html 文中分析的spark版本為apache的spark-2.1.0-bin-hadoop2.7。 bin目錄結構: -rwxr-xr-x. 1 bigdata bigdata 1089 Dec
Android與JS之JsBridge使用與原始碼分析
在Android開發中,由於Native開發的成本較高,H5頁面的開發更靈活,修改成本更低,因此前端網頁JavaScript(下面簡稱JS)與Java之間的互相呼叫越來越常見。 JsBridge就是一個簡化Android與JS通訊的框架,原始碼:https://github.com/lzyzsd