
深度學習中Dropout原理解析
“微信公眾號”

1. Dropout簡介
1.1 Dropout出現的原因
在機器學習的模型中,如果模型的引數太多,而訓練樣本又太少,訓練出來的模型很容易產生過擬合的現象。在訓練神經網路的時候經常會遇到過擬合的問題,過擬合具體表現在:模型在訓練資料上損失函式較小,預測準確率較高;但是在測試資料上損失函式比較大,預測準確率較低。
過擬合是很多機器學習的通病。如果模型過擬合,那麼得到的模型幾乎不能用。為了解決過擬合問題,一般會採用模型整合的方法,即訓練多個模型進行組合。此時,訓練模型費時就成為一個很大的問題,不僅訓練多個模型費時,測試多個模型也是很費時。
綜上所述,訓練深度神經網路的時候,總是會遇到兩大缺點:
(1)容易過擬合
(2)費時
Dropout可以比較有效的緩解過擬合的發生,在一定程度上達到正則化的效果。
1.2 什麼是Dropout
在2012年,Hinton在其論文《Improving neural networks by preventing co-adaptation of feature detectors》中提出Dropout。當一個複雜的前饋神經網路被訓練在小的資料集時,容易造成過擬合。為了防止過擬合,可以通過阻止特徵檢測器的共同作用來提高神經網路的效能。
在2012年,Alex、Hinton在其論文《ImageNet Classification with Deep Convolutional Neural Networks》中用到了Dropout演算法,用於防止過擬合。並且,這篇論文提到的AlexNet網路模型引爆了神經網路應用熱潮,並贏得了2012年影象識別大賽冠軍,使得CNN成為影象分類上的核心演算法模型。
隨後,又有一些關於Dropout的文章《Dropout:A Simple Way to Prevent Neural Networks from Overfitting》、《Improving Neural Networks with Dropout》、《Dropout as data augmentation》。
從上面的論文中,我們能感受到Dropout在深度學習中的重要性。那麼,到底什麼是Dropout呢?
Dropout可以作為訓練深度神經網路的一種trick供選擇。在每個訓練批次中,通過忽略一半的特徵檢測器(讓一半的隱層節點值為0),可以明顯地減少過擬合現象。這種方式可以減少特徵檢測器(隱層節點)間的相互作用,檢測器相互作用是指某些檢測器依賴其他檢測器才能發揮作用。
Dropout說的簡單一點就是:我們在前向傳播的時候,讓某個神經元的啟用值以一定的概率p停止工作,這樣可以使模型泛化性更強,因為它不會太依賴某些區域性的特徵,如圖1所示。
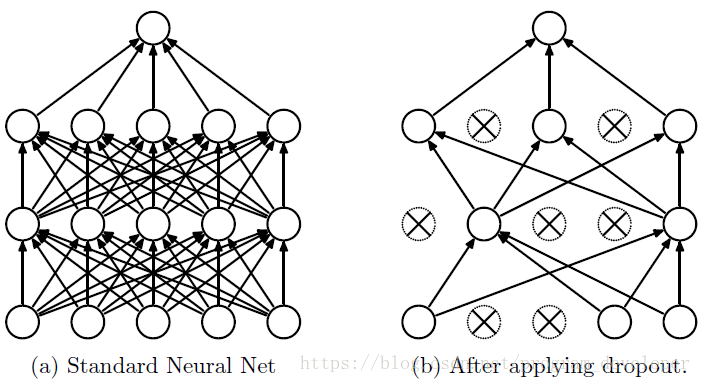
圖1:使用Dropout的神經網路模型
2. Dropout工作流程及使用
2.1 Dropout具體工作流程
假設我們要訓練這樣一個神經網路,如圖2所示。
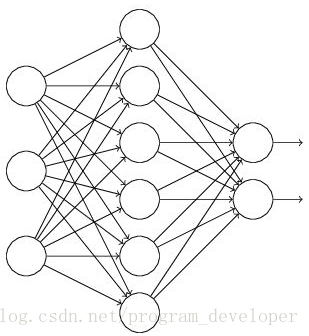
圖2:標準的神經網路
輸入是x輸出是y,正常的流程是:我們首先把x通過網路前向傳播,然後把誤差反向傳播以決定如何更新引數讓網路進行學習。使用Dropout之後,過程變成如下:
(1)首先隨機(臨時)刪掉網路中一半的隱藏神經元,輸入輸出神經元保持不變(圖3中虛線為部分臨時被刪除的神經元)
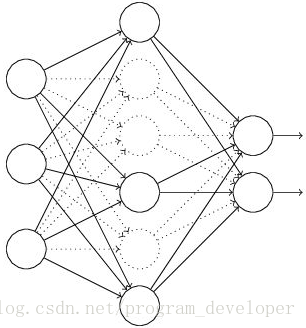
圖3:部分臨時被刪除的神經元
(2) 然後把輸入x通過修改後的網路前向傳播,然後把得到的損失結果通過修改的網路反向傳播。一小批訓練樣本執行完這個過程後,在沒有被刪除的神經元上按照隨機梯度下降法更新對應的引數(w,b)。
(3)然後繼續重複這一過程:
- . 恢復被刪掉的神經元(此時被刪除的神經元保持原樣,而沒有被刪除的神經元已經有所更新)
- . 從隱藏層神經元中隨機選擇一個一半大小的子集臨時刪除掉(備份被刪除神經元的引數)。
- . 對一小批訓練樣本,先前向傳播然後反向傳播損失並根據隨機梯度下降法更新引數(w,b) (沒有被刪除的那一部分引數得到更新,刪除的神經元引數保持被刪除前的結果)。
不斷重複這一過程。
2.2 Dropout在神經網路中的使用
Dropout的具體工作流程上面已經詳細的介紹過了,但是具體怎麼讓某些神經元以一定的概率停止工作(就是被刪除掉)?程式碼層面如何實現呢?
下面,我們具體講解一下Dropout程式碼層面的一些公式推導及程式碼實現思路。
(1)在訓練模型階段
無可避免的,在訓練網路的每個單元都要新增一道概率流程。
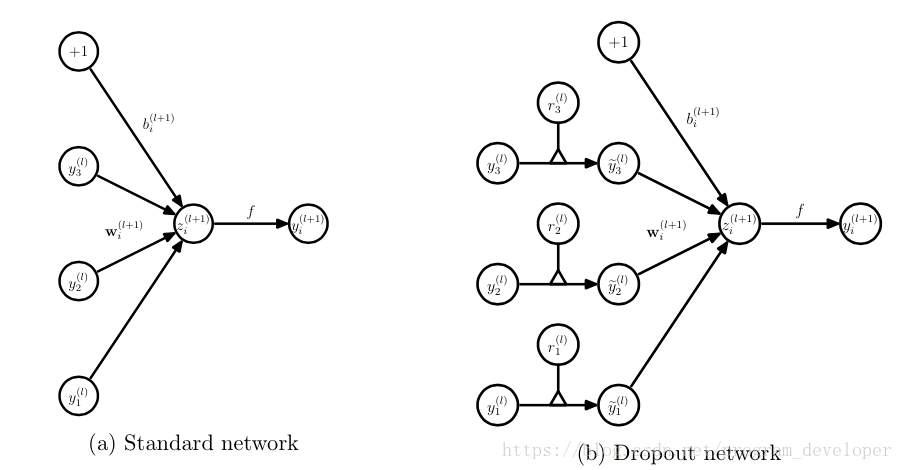
對應的公式變化如下:
- . 沒有Dropout的網路計算公式:
-
- . 採用Dropout的網路計算公式:
上面公式中Bernoulli函式是為了生成概率r向量,也就是隨機生成一個0、1的向量。
程式碼層面實現讓某個神經元以概率p停止工作,其實就是讓它的啟用函式值以概率p變為0。比如我們某一層網路神經元的個數為1000個,其啟用函式輸出值為y1、y2、y3、......、y1000,我們dropout比率選擇0.4,那麼這一層神經元經過dropout後,1000個神經元中會有大約400個的值被置為0。
注意: 經過上面遮蔽掉某些神經元,使其啟用值為0以後,我們還需要對向量y1……y1000進行縮放,也就是乘以1/(1-p)。如果你在訓練的時候,經過置0後,沒有對y1……y1000進行縮放(rescale),那麼在測試的時候,就需要對權重進行縮放,操作如下。
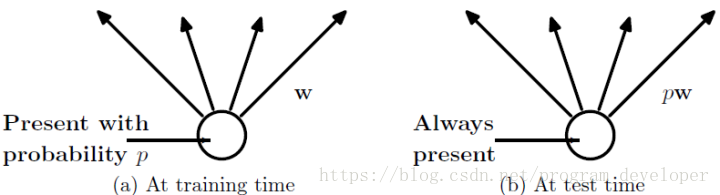
(2)在測試模型階段
預測模型的時候,每一個神經單元的權重引數要乘以概率p。
- 圖5:預測模型時Dropout的操作
- 測試階段Dropout公式:
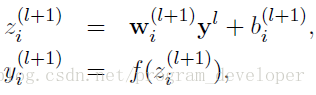
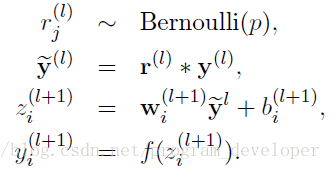
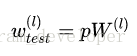
3. 為什麼說Dropout可以解決過擬合?
(1)取平均的作用: 先回到標準的模型即沒有dropout,我們用相同的訓練資料去訓練5個不同的神經網路,一般會得到5個不同的結果,此時我們可以採用 “5個結果取均值”或者“多數取勝的投票策略”去決定最終結果。例如3個網路判斷結果為數字9,那麼很有可能真正的結果就是數字9,其它兩個網路給出了錯誤結果。這種“綜合起來取平均”的策略通常可以有效防止過擬合問題。因為不同的網路可能產生不同的過擬合,取平均則有可能讓一些“相反的”擬合互相抵消。dropout掉不同的隱藏神經元就類似在訓練不同的網路,隨機刪掉一半隱藏神經元導致網路結構已經不同,整個dropout過程就相當於對很多個不同的神經網路取平均。而不同的網路產生不同的過擬合,一些互為“反向”的擬合相互抵消就可以達到整體上減少過擬合。
(2)減少神經元之間複雜的共適應關係: 因為dropout程式導致兩個神經元不一定每次都在一個dropout網路中出現。這樣權值的更新不再依賴於有固定關係的隱含節點的共同作用,阻止了某些特徵僅僅在其它特定特徵下才有效果的情況 。迫使網路去學習更加魯棒的特徵 ,這些特徵在其它的神經元的隨機子集中也存在。換句話說假如我們的神經網路是在做出某種預測,它不應該對一些特定的線索片段太過敏感,即使丟失特定的線索,它也應該可以從眾多其它線索中學習一些共同的特徵。從這個角度看dropout就有點像L1,L2正則,減少權重使得網路對丟失特定神經元連線的魯棒性提高。
(3)Dropout類似於性別在生物進化中的角色:物種為了生存往往會傾向於適應這種環境,環境突變則會導致物種難以做出及時反應,性別的出現可以繁衍出適應新環境的變種,有效的阻止過擬合,即避免環境改變時物種可能面臨的滅絕。
4. Dropout在Keras中的原始碼分析
下面,我們來分析Keras中Dropout實現原始碼。
Keras開源專案GitHub地址為:
其中Dropout函式程式碼實現所在的檔案地址:
Dropout實現函式如下:

圖6:Keras中實現Dropout功能
我們對keras中Dropout實現函式做一些修改,讓dropout函式可以單獨執行。
# coding:utf-8
import numpy as np
# dropout函式的實現
def dropout(x, level):
if level < 0. or level >= 1: #level是概率值,必須在0~1之間
raise ValueError('Dropout level must be in interval [0, 1[.')
retain_prob = 1. - level
# 我們通過binomial函式,生成與x一樣的維數向量。binomial函式就像拋硬幣一樣,我們可以把每個神經元當做拋硬幣一樣
# 硬幣 正面的概率為p,n表示每個神經元試驗的次數
# 因為我們每個神經元只需要拋一次就可以了所以n=1,size引數是我們有多少個硬幣。
random_tensor = np.random.binomial(n=1, p=retain_prob, size=x.shape) #即將生成一個0、1分佈的向量,0表示這個神經元被遮蔽,不工作了,也就是dropout了
print(random_tensor)
x *= random_tensor
print(x)
x /= retain_prob
return x
#對dropout的測試,大家可以跑一下上面的函式,瞭解一個輸入x向量,經過dropout的結果
x=np.asarray([1,2,3,4,5,6,7,8,9,10],dtype=np.float32)
dropout(x,0.4)函式中,x是本層網路的啟用值。Level就是dropout就是每個神經元要被丟棄的概率。
注意: Keras中Dropout的實現,是遮蔽掉某些神經元,使其啟用值為0以後,對啟用值向量x1……x1000進行放大,也就是乘以1/(1-p)。
思考:上面我們介紹了兩種方法進行Dropout的縮放,那麼Dropout為什麼需要進行縮放呢?
因為我們訓練的時候會隨機的丟棄一些神經元,但是預測的時候就沒辦法隨機丟棄了。如果丟棄一些神經元,這會帶來結果不穩定的問題,也就是給定一個測試資料,有時候輸出a有時候輸出b,結果不穩定,這是實際系統不能接受的,使用者可能認為模型預測不準。那麼一種”補償“的方案就是每個神經元的權重都乘以一個p,這樣在“總體上”使得測試資料和訓練資料是大致一樣的。比如一個神經元的輸出是x,那麼在訓練的時候它有p的概率參與訓練,(1-p)的概率丟棄,那麼它輸出的期望是px+(1-p)0=px。因此測試的時候把這個神經元的權重乘以p可以得到同樣的期望。
總結:
當前Dropout被大量利用於全連線網路,而且一般認為設定為0.5或者0.3,而在卷積網路隱藏層中由於卷積自身的稀疏化以及稀疏化的ReLu函式的大量使用等原因,Dropout策略在卷積網路隱藏層中使用較少。總體而言,Dropout是一個超參,需要根據具體的網路、具體的應用領域進行嘗試。
Reference:
Hinton G E, Srivastava N, Krizhevsky A, et al. Improving neural networks by preventing co-adaptation of feature detectors[J]. arXiv preprint arXiv:1207.0580, 2012.
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems. 2012: 1097-1105.
Srivastava N, Hinton G, Krizhevsky A, et al. Dropout: A simple way to prevent neural networks from overfitting[J]. The Journal of Machine Learning Research, 2014, 15(1): 1929-1958.
Srivastava N. Improving neural networks with dropout[J]. University of Toronto, 2013, 182.
Bouthillier X, Konda K, Vincent P, et al. Dropout as data augmentation[J]. arXiv preprint arXiv:1506.08700, 2015.
深度學習(二十二)Dropout淺層理解與實現,地址:https://blog.csdn.net/hjimce/article/details/50413257
理解dropout,地址:https://blog.csdn.net/stdcoutzyx/article/details/49022443
Dropout解決過擬合問題 - 曉雷的文章 - 知乎,地址:https://zhuanlan.zhihu.com/p/23178423
李理:卷積神經網路之Dropout,地址:https://blog.csdn.net/qunnie_yi/article/details/80128463
Dropout原理,程式碼淺析,地址:https://blog.csdn.net/whiteinblue/article/details/37808623
Deep learning:四十一(Dropout簡單理解),地址:https://www.cnblogs.com/tornadomeet/p/3258122.html?_t_t_t=0.09445037946091872
相關推薦
深度學習中Dropout原理解析
“微信公眾號”1. Dropout簡介1.1 Dropout出現的原因在機器學習的模型中,如果模型的引數太多,而訓練樣本又太少,訓練出來的模型很容易產生過擬合的現象。在訓練神經網路的時候經常會遇到過擬合的問題,過擬合具體表現在:模型在訓練資料上損失函式較小,預測準確率較高;但
深度學習中Dropout和Layer Normalization技術的使用
兩者的論文: Dropout:http://www.jmlr.org/papers/volume15/srivastava14a/srivastava14a.pdf Layer Normaliza
關於深度學習中的注意力機制,這篇文章從例項到原理都幫你參透了(很系統,重點看)
最近兩年,注意力模型(Attention Model)被廣泛使用在自然語言處理、影象識別及語音識別等各種不同型別的深度學習任務中,是深度學習技術中最值得關注與深入瞭解的核心技術之一。 本文以機器翻譯為例,深入淺出地介紹了深度學習中注意力機制的原理及關鍵計算機制,同時也抽
深度學習中的dropout
看過很多關於dropout方面的部落格,但是感覺寫太一般,不能達到我想要的水平,所以決定自己寫一下。 1.dropout解決的問題 深度神經網路的訓練是一件非常困難的事,涉及到很多因素,比如損失函式的非凸性導致的區域性最優值、計算過程中的數值穩定性、訓練
深度學習中Attention Mechanism詳細介紹:原理、分類及應用
Attention是一種用於提升基於RNN(LSTM或GRU)的Encoder + Decoder模型的效果的的機制(Mechanism),一般稱為Attention Mechanism。Attention Mechanism目前非常流行,廣泛應用於機器翻譯、語音識別、影象標
深度學習中如何選擇好的優化方法(optimizer)【原理】
除了隨機梯度初始化(SGD),在深度學習中還有很多其他的方法可以對網路進行優化1. 減少網路收斂時間2. 除了學習率(learning rate)還有更多其他的引數3. 比SGD到達更高的分類準確率一. 自適應學習率為了更好的理解優化的方法,這裡我們都是用虛擬碼的方式來進行描
資深程序員帶你玩轉深度學習中的正則化技術(附Python代碼)!
c51 進行 ros batch num 簡單的 oat 深度學習 repr 目錄 1. 什麽是正則化? 2. 正則化如何減少過擬合? 3. 深度學習中的各種正則化技術: L2和L1正則化 Dropout 數據增強(Data augmentation) 提前停止(Ear
卷積在深度學習中的作用(轉自http://timdettmers.com/2015/03/26/convolution-deep-learning/)
範圍 SM 全連接 判斷 contact con 發展 .dsp length 卷積可能是現在深入學習中最重要的概念。卷積網絡和卷積網絡將深度學習推向了幾乎所有機器學習任務的最前沿。但是,卷積如此強大呢?它是如何工作的?在這篇博客文章中,我將解釋卷積並將其與其他概念聯系起來
機器學習算法原理解析——分類
窮舉 dataset array amp 正則 learn 構造 epo sub 1. KNN分類算法原理及應用 1.1 KNN概述 K最近鄰(k-Nearest Neighbor,KNN)分類算法是最簡單的機器學習算法。 KNN算法的指導思想是“近朱者赤
機器學習算法原理解析——協同過濾推薦
3.6 新用戶 準確率 用戶偏好 tab tag 相同 pty cin 1. CF協同過濾推薦算法原理及應用 1.1 概述 什麽是協同過濾(Collaborative Filtering,簡稱CF)? 首先想一個簡單的問題,如果你現在想看個電影,但你不知道具體看哪部,
關於深度學習中的batch_size
line question 代價函數 online 由於 數據 減少 使用 矛盾 5.4.1 關於深度學習中的batch_size batch_size可以理解為批處理參數,它的極限值為訓練集樣本總數,當數據量比較少時,可以將batch_size值設置為全數據集(Full
深度學習中 GPU 和視訊記憶體分析 深度學習中 GPU 和視訊記憶體分析
轉 深度學習中 GPU 和視訊記憶體分析 2017年12月21日 14:05:01 lien0906 閱讀數:5941 更多
【遷移學習】簡述遷移學習在深度學習中的應用
選自MachineLearningMastery 作者:Jason Brownlee 機器之心編譯 參與:Nurhachu Null、劉曉坤 本文介紹了遷移學習的基本概念,以及該方法在深度學習中的應用,引導構建預測模型的時候使用遷移學習的基本策略。 遷移學習是一種機器學習
深度學習中的英文專有名詞
最近在讀深度學習的文獻資料,覺得專有名詞還是挺多的。網上搜集到一些,背一下。 activation
深度學習中張量flatten處理(flatten,reshape,reduce)
先看一下flatten的具體用法 1-對於一般數值,可以直接flatten >>> a=array([[1,2],[3,4],[5,6]]) >>> a array([[1, 2], [3, 4], [5, 6]]) &
深度學習基礎--DL原理研究2
深度學習神經網路需要更深而非更廣 《On the Number of Linear Regions of Deep Neural Networks》中有解釋。 這篇文章證明了,在神經元總數相當的情況下,增加網路深度可以使網路產生更多的線性區域。 深度的貢獻是指數增長的,而寬度的貢
深度學習基礎--DL原理研究1
DL的原理研究 深度網路是手段,特徵學習是目的 任何一種方法,特徵越多,給出的參考資訊就越多,準確性會得到提升。但特徵多意味著計算複雜,探索的空間大,可以用來訓練的資料在每個特徵上就會稀疏,都會帶來各種問題,並不一定特徵越多越好。 基本思想 形象地表示為: I =
深度學習中embedding的含義
Embedding在數學上表示一個maping, f: X ->Y 也就是一個function,其中該函式是injective(就是我們所說的單射函式,每個Y只有唯一的X對應,反之亦然)和structure-preserving (結構儲存,比如在X所屬的空間上X1 < X2,那
聊一聊深度學習中常用的激勵函式
大家都知道,人腦的基本計算單元叫做神經元。現代生物學表明,人的神經系統中大概有860億神經元,而這數量巨大的神經元之間大約是通過1014−1015個突觸連線起來的。上面這一幅示意圖,粗略地描繪了一下人體神經元與我們簡化過後的數學模型。每個神經元都從樹突接受訊號,同時順著某個軸突傳遞
機器學習:深度學習中的遷移學習
遷移學習也是最近機器學習領域很火熱的一個方向,尤其是基於深度學習的遷移學習。遷移學習,顧名思義,就是要遷移,有句成語叫觸類旁通,模型在某個任務上學習到知識,當遇到類似任務的時候,應該可以很快的把以前任務學到知識遷移過來。這是擬人化的描述,按照目前主流的 “資料驅動” 型的學習方式,我們所