
分類聚類區別及聚類概述
在初學分類聚類時,對這兩個概念不是很瞭解。隨著深入的瞭解,現有了一些基本的認識。現對聚類進行個人理解上的總結,歡迎大家批評指正。
一、分類和聚類的區別
分類和聚類的概念是比較容易混淆的。
對於分類來說,在對資料集分類時,我們是知道這個資料集是有多少種類的,比如對一個學校的在校大學生進行性別分類,我們會下意識很清楚知道分為“男”,“女”
而對於聚類來說,在對資料集操作時,我們是不知道該資料集包含多少類,我們要做的,是將資料集中相似的資料歸納在一起。比如預測某一學校的在校大學生的好朋友團體,我們不知道大學生和誰玩的好玩的不好,我們通過他們的相似度進行聚類,聚成n個團體,這就是聚類。
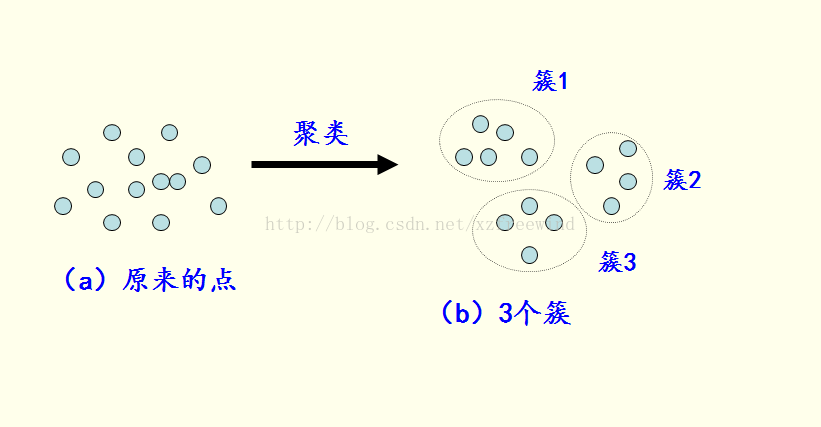
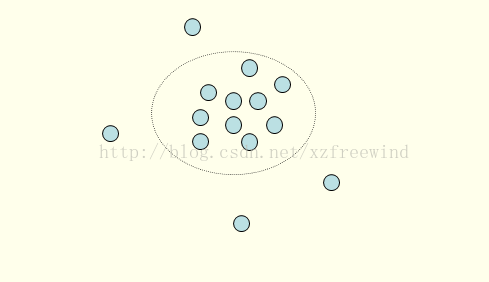
按照李春葆老師的話說,聚類是將資料物件的集合分成相似的物件類的過程。使得同一個簇(或類)中的物件之間具有較高的相似性,而不同簇中的物件具有較高的相異性。如下圖所示
二、 聚類的定義
我們這樣來對聚類進行定義。聚類可形式描述為:D={o1,o2,…,on}表示n個物件的集合,oi表示第i(i=1,2,…,n)個物件,Cx表示第x(x=1,2,…,k)個簇,CxÍD。用sim(oi,oj)表示物件oi與物件oj之間的相似度。若各簇Cx是剛性聚類結果,則各Cx需滿足如下條件:
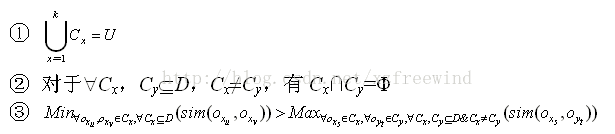
其中,條件①和②表示所有Cx是D的一個劃分,條件③表示簇內任何物件的相似度均大於簇間任何物件的相似度。
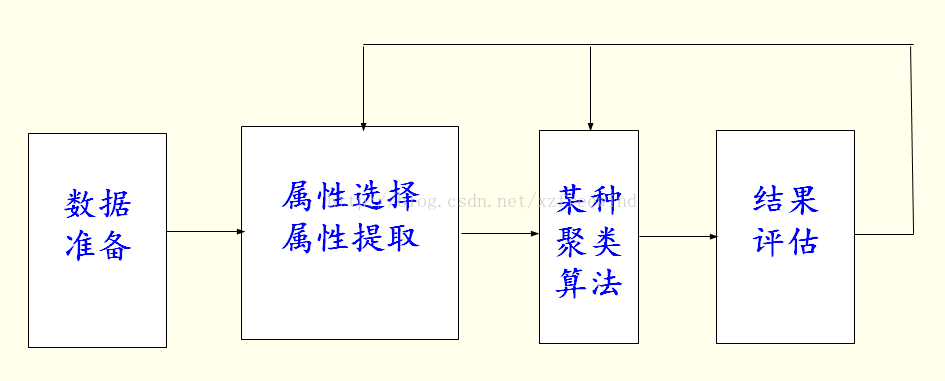
聚類的整體流程如下:
三、聚類的方法
根據定義我們知道,聚類,簡單的來說,是通過“臭味相投”的原理來進行選擇“戰友”的。
那麼這個“臭味相投”的原理或準則是什麼呢?
前人想出了四種相似度的比對方法,即距離相似度度量、密度相似度度量、連通性相似度度量和概念相似度度量。
3.1距離相似度量
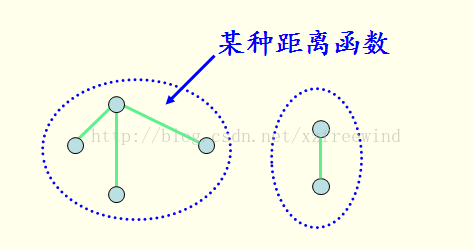
距離相似度度量是指樣本間的距離越近,那麼這倆樣本間的相似度就越高。距離這個詞我們可以這麼理解,把資料集的每一個特徵當做空間上的一個維度,這樣就確定了兩個點,這兩個點間的“連線”直線就可以當做是它們的距離。一般有三種距離度量,曼哈頓距離、歐氏距離、閔可夫斯基距離,這三個距離表示方式都是原始距離的變形,具體形式如下:

因為相似度與距離是反比的關係,因此在確定好距離後可以設計相似函式如下:
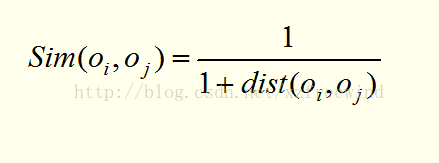
其中,K-means演算法就是基於距離的聚類演算法
3.2密度相似度度量 密度相似度的出發點是“物以類聚,人以群分”,相同類別的物體往往會“抱團取暖”,也就是說,每個團體都會圍在一個圈子裡,這個圈子呢,密度會很大,所以就有密度相似度度量這一考察形式。密度是單位區域內的物件個數。密度相似性度量定義為:
density(Ci,Cj)=|di-dj|
其中di、dj表示簇Ci、Cj的密度。其值越小,表示密度越相近,Ci、Cj相似性越高。這樣情況下,簇是物件的稠密區域,被低密度的區域環繞。
其中,DBSCAN就是基於密度的聚類演算法
3.3連通性相似度度量
資料集用圖表示,圖中結點是物件,而邊代表物件之間的聯絡,這種情況下可以使用連通性相似性,將簇定義為圖的連通分支,即圖中互相連通但不與組外物件連通的物件組。
也就是說,在同一連通分支中的物件之間的相似性度量大於不同連通分支之間物件的相似性度量。
3.4概念相似度度量
若聚類方法是基於物件具有的概念,則需要採用概念相似性度量,共同性質(比如最近鄰)越多的物件越相似。簇定義為有某種共同性質的物件的集合。

四、聚類的評定標準
說了這麼多聚類演算法,我們都知道,聚類演算法沒有好壞,但聚類之後的結果根據資料集等環境不同有著好壞之分,那麼該怎麼評價聚類的好壞呢?
一個好的聚類演算法產生高質量的簇,即高的簇內相似度和低的簇間相似度。通常估聚類結果質量的準則有內部質量評價準則和外部質量評價準則。比如,我們可以用CH指標來進行評定。CH指標定義如下:
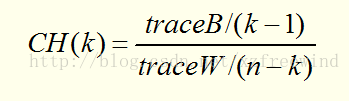
其中:


traceB表示簇間距離,traceW表示簇內距離,CH值越大,則聚類效果越好。
相關推薦
分類聚類區別及聚類概述
在初學分類聚類時,對這兩個概念不是很瞭解。隨著深入的瞭解,現有了一些基本的認識。現對聚類進行個人理解上的總結,歡迎大家批評指正。 一、分類和聚類的區別 分類和聚類的概念是比較容易混淆的。 對於分類來說,在對資料集分類時,我們是知道這個資料集是有多少種類的,比如對一個學校的
超連結a標籤中的偽類區別及用法
首先“超連結”就是我們 html 中的 a 標籤,這個應該大家都沒問題。再接著,"偽類":什麼是偽類? css 對於偽類的解釋是用於向某些選擇器新增特殊的效果。簡單點說,就是你沒定義這個類,但它確
Integer 和 int 的區別及 Integer類的方法
本文參考: Integer 和 int 的區別 1、Integer是int提供的封裝類,而int是Java的基本資料型別; 2、Integer的預設值是null,而int的預設值是0; 3、生命為Integer的變數需要例項化,而宣告為int的變數不需要例項化;
JavaScript判斷對象類型及節點類型、節點名稱和節點值
table 屬性節點 定義 ring pan nod undefined tel gpo 一、JavaScript判斷對象類型 1、可以使用typeof函數判斷對象類型 1 function checkObject1(){ 2 var str="st
第13周-任務3-抽象基類Shape及派生類Circle Rectangle和Triangle
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
分類和聚類的區別及各自的常見演算法
1、分類和聚類的區別: Classification (分類),對於一個classifier,通常需要你告訴它“這個東西被分為某某類”這樣一些例子,理想情況下,一個 classifier 會從它得到的訓練集中進行“學習”,從而具備對未知資料進行分類的能力
聚類分析及R程式設計實現
目錄 什麼是聚類分析 聚類分析法的型別 聚類統計量 系統聚類法 R語言實現 最短距離法 最長距離法 中間距離法 類平均法 重心法 ward法 什麼是聚類分析 聚類分析法-cluster ana
機器學習-*-MeanShift聚類演算法及程式碼實現
MeanShift 該演算法也叫做均值漂移,在目標追蹤中應用廣泛。本身其實是一種基於密度的聚類演算法。 主要思路是:計算某一點A與其周圍半徑R內的向量距離的平均值M,計算出該點下一步漂移(移動)的方向(A=M+A)。當該點不再移動時,其與周圍點形成一個類簇,計算這個類簇與歷史類簇的距
模糊C均值聚類演算法及實現
模糊C均值聚類演算法的實現 研究背景 https://blog.csdn.net/liu_xiao_cheng/article/details/50471981 聚類分析是多元統計分析的一種,也是無監督模式識別的一個重要分支,在模式分類 影象處理和模糊
目錄:空間聚類演算法及時空聚類演算法
1.在本例項中,如果想將程式碼直接執行需注意以下幾點: Python版本3.X(本人使用的是Python 3.6) numpy版本 1.13.3(其他版本未實驗) scipy版本 0.19.1(其他版本未實驗) matplotlib版本 2.1.0(其他版本
聚類分析層次聚類及k-means演算法
參考文獻: [1]Jure Leskovec,Anand Rajaraman,Jeffrey David Ullman.大資料網際網路大規模資料探勘與分散式處理(第二版) [M]北京:人民郵電出版社,2015.,190-199; [2]蔣盛益,李霞,鄭琪.資料探勘原理與實踐 [M]北京:電子工業出版社,20
機器學習總結(十):常用聚類演算法(Kmeans、密度聚類、層次聚類)及常見問題
任務:將資料集中的樣本劃分成若干個通常不相交的子集。 效能度量:類內相似度高,類間相似度低。兩大類:1.有參考標籤,外部指標;2.無參照,內部指標。 距離計算:非負性,同一性(與自身距離為0),對稱性
kmeans聚類演算法及複雜度
kmeans是最簡單的聚類演算法之一,kmeans一般在資料分析前期使用,選取適當的k,將資料分類後,然後分類研究不同聚類下資料的特點。 演算法原理 隨機選取k箇中心點; 遍歷所有資料,將每個資料劃分到最近的中心點中; 計算每個聚類的平均值,並作為新的中心點; 重複
一篇文章透徹解讀聚類分析及案例實操
1 聚類分析介紹 1.1 基本概念 聚類就是一種尋找資料之間一種內在結構的技術。聚類把全體資料例項組織成一些相似組,而這些相似組被稱作聚類。處於相同聚類中的資料例項彼此相同,處於不同聚類中的例項彼此不同。聚類技術通常又被稱為無監督學習,因為與監督學習不同,在聚類中那
分級聚類——部落格分類 (畫出分級聚類樹狀圖)
《集體智慧程式設計》的第三章——發現組群 下面的測試資料可以在網上下載 通過分級聚類的方式將資料一層一層的聚類,最終聚類為一個大的物件。畫了一個樣例圖如下: 其中將A、B、C、D、E五個物件進行層級聚類,最終的聚類步驟上面已經標出(1,2,3,4)。
(相似度、鄰近及聚類)Similarity, Neighbors, and Clusters
主要內容: 相似度(Similarity) (can be used for classification and regression) 距離函式(Distance Function) Nearest - Neighbor Hierarchical Clustering
機器學習筆記(九)聚類演算法及實踐(K-Means,DBSCAN,DPEAK,Spectral_Clustering)
這一週學校的事情比較多所以拖了幾天,這回我們來講一講聚類演算法哈。 首先,我們知道,主要的機器學習方法分為監督學習和無監督學習。監督學習主要是指我們已經給出了資料和分類,基於這些我們訓練我們的分類器以
[Python聚類] K-Means聚類演算法分類
根據資料將客戶分類成不同客戶群,並評價這些客戶群的價值。 資料示例 部分餐飲客戶的消費行為特徵資料如下: R最近一次消費時間間隔 F消費頻率 M消費總金額 方法 採用K-Means
經典聚類演算法及在網際網路的應用
此處並不會列舉每一種聚類(Clustering)演算法,因為學術界Clustering演算法如果真要細分,還真有很多變種。此處只會介紹幾種在我近幾年網際網路工作生涯中實際碰到的具體問題, 以及如何使用Clustering演算法解決這些問題。 一般來說,我們可以將Clus
四種聚類方法及程式碼實現。K-means 高斯聚類 密度聚類 均值漂移聚類
四種方法的matlab程式碼實現:連結: https://pan.baidu.com/s/1b6pKH65rYrRcBLnczz-EnA 密碼: 4iag1.K-means聚類:演算法步驟: (1) 首先我們選擇一些類/組,並隨機初始化它們各自的中心點。中心點是與每個資料點向