
機器學習-*-MeanShift聚類演算法及程式碼實現
MeanShift
該演算法也叫做均值漂移,在目標追蹤中應用廣泛。本身其實是一種基於密度的聚類演算法。
主要思路是:計算某一點A與其周圍半徑R內的向量距離的平均值M,計算出該點下一步漂移(移動)的方向(A=M+A)。當該點不再移動時,其與周圍點形成一個類簇,計算這個類簇與歷史類簇的距離,滿足小於閾值D即合併為同一個類簇,不滿足則自身形成一個類簇。直到所有的資料點選取完畢。
一般形式
對於給定的 n 維空間
中的 m 個樣本點
,i=1…m,對於其中一個樣本X,他的均值漂移向量為:
,其中
指的是一個半徑為h的球狀領域,定義為
,如下圖所示
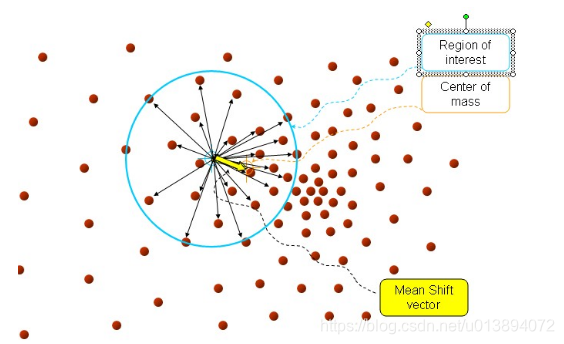
藍色圈內表示半徑h的區域
,黃色箭頭尾部指的是計算前的資料點
,箭頭本身是指的計算後的漂移向量
。由上圖可以看出,均值漂移會不斷的往密度較大的區域移動。熟悉的同學可能瞭解到,一般用的均值漂移都是經過核函式改進的,那為什麼要引入核函式呢?
首先,我們再看一下上圖和公式:藍色圈區域內,每一個與
相鄰的
在計算過程中對均值漂移向量的貢獻都是一樣的,不以這個點與X的距離遠近而變化。按照我們人類的思想,近朱者赤 近墨者黑,離得中心點越近,受影響/反影響的力度就會越大。比如,都是程式設計師,但是三線城市程式設計師和北京程式設計師在知識廣度、能力、成長速度等方面都有較大差距,畢竟北京是網際網路行業的中心城市嘛。應用到演算法裡也是一樣的,因此就有人提出鄰域內的點需要設定不同的權重來進行漂移計算,故提出了核函式的概念
核函式形式
設
是輸入空間,是實數空間的一個子集。設
為希爾伯特空間(完備的空間,抽象意義上對有限維歐式空間的擴充套件),設存在一個對映:
,此時有函式
,其中
。關於希爾伯特空間和核函式的概念,本人瞭解的也不深,歡迎探討。
高斯核函式是一種應用廣泛的核函式:
其中h為bandwidth 頻寬,不同頻寬的核函式形式也不一樣
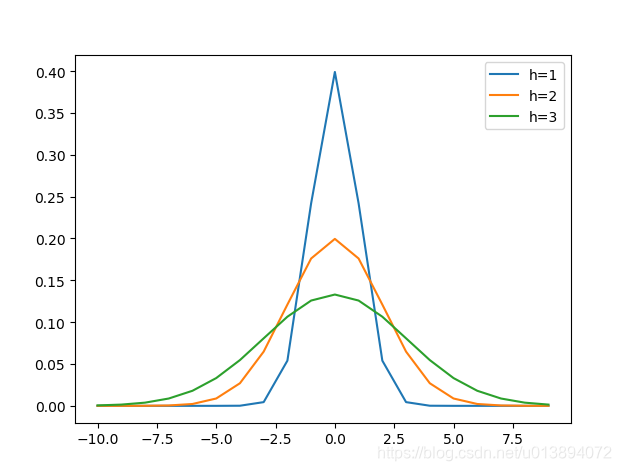
由上圖可以看到,橫座標指的是兩變數之間的距離。距離越近(接近於0)則函式值越大,否則越小。h越大,相同距離的情況下 函式值會越小。因此我們可以選取適當的h值,得到滿足上述要求的那種權重(兩變數距離越近,得到權重越大),故經過核函式改進後的均值漂移為:
其中
就是高斯核函式
看到其他的文章說,經過核函式改進後的均值漂移,經過證明(求導),會朝著概率密度上升的區域移動。
上程式碼及實驗結果:
Python程式碼
class MeanShift(object):
"""
均值漂移聚類-基於密度
"""
def __init__(self,radius = 0.5,distance_between_groups = 2.5,bandwidth = 1,use_gk = True):
self._radius = radius
self._groups = []
self._bandwidth = bandwidth
self._distance_between_groups = distance_between_groups
self._use_gk = use_gk #是否啟用高斯核函式
def _find_nearst_indexes(self,xi,XX):
if XX.shape[0] == 0:
return []
distances= eculide(xi,XX)
nearst_indexes = np.where(distances <= self._distance_between_groups)[0].tolist()
return nearst_indexes
def _compute_mean_vector(self,xi,datas):
distances = datas-xi
if self._use_gk:
sum1 = self.gaussian_kernel(distances)
sum2 = sum1*(distances)
mean_vector = np.sum(sum2,axis=0)/np.sum(sum1,axis=0)
else:
mean_vector = np.sum(datas - xi, axis=0) / datas.shape[0]
return mean_vector
def fit(self,X):
XX = X
while(XX.shape[0]!=0):
# 1.從原始資料選取一箇中心點及其半徑周邊的點 進行漂移運算
index = np.random.randint(0,XX.shape[0],1).squeeze()
group = Group()
xi = XX[index]
XX = np.delete(XX,index,axis=0) # 刪除XX中的一行並重新賦值
nearest_indexes = self._find_nearst_indexes(xi, XX)
nearest_datas = None
mean_vector = None
if len(nearest_indexes) != 0:
nearest_datas = None
# 2.不斷進行漂移,中心點達到穩定值
epos = 1.0
while (True):
nearest_datas = XX[nearest_indexes]
mean_vector = self._compute_mean_vector(xi,nearest_datas)
xi = mean_vector + xi
nearest_indexes = self._find_nearst_indexes(xi, XX)
epos = np.abs(np.sum(mean_vector))
if epos < 0.00001 : break
if len(nearest_indexes) == 0 : break
# 有些部落格說在一次漂移過程中 每個漂移點周邊的點都需要納入該類簇中,我覺得不妥,此處不是這樣實現的,
# 只把穩定點周邊的資料納入該類簇中
group.members = nearest_datas.tolist()
group.center = xi
XX = np.delete(XX, nearest_indexes, axis=0)
else:
group.center = xi
# 3.與歷史類簇進行距離計算,若小於閾值則加入歷史類簇,並更新類簇中心及成員
for i in range(len(self._groups)):
h_group = self._groups[i]
distance = eculide(h_group.center,group.center)
if distance <= self._distance_between_groups:
h_group.members = group.members
h_group.center = (h_group.center+group.center)/2
else:
group.name = len(self._groups) + 1
self._groups.append(group)
break
if len(self._groups) == 0:
group.name = len(self._groups) + 1
self._groups.append(group)
# 4.從餘下的點中重複1-3的計算,直到所有資料完成選取
def plot_example(self):
figure = plt.figure()
ax = figure.add_subplot(111)
ax.set_title("MeanShift Iris Example")
plt.xlabel("first dim")
plt.ylabel("third dim")
legends = []
cxs = []