
Python 文字識別 安裝Tesseract ORC
Tesseract,一款由HP實驗室開發由Google維護的開源OCR(Optical Character Recognition , 光學字元識別)引擎,特點是開源,免費,支援多語言,多平臺。
下載地址:https://github.com/tesseract-ocr/tesseract/wiki
這裡下載的是Windows版本
執行exe檔案
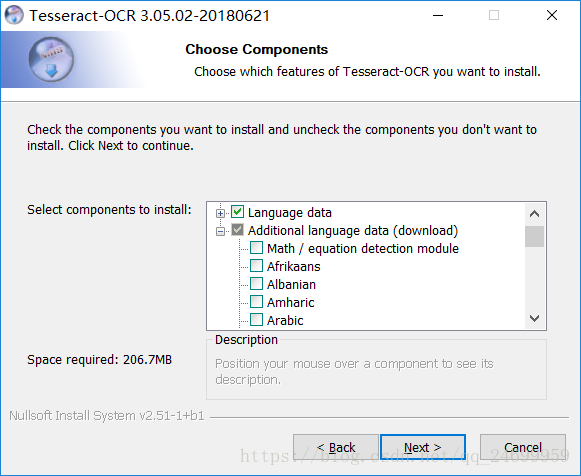
在這裡選擇新增語言資料檔案(預設只有英文,如果需要中文請勾選)
執行
錯誤1
Traceback (most recent call last):
File "C:/Users/User-name/PycharmProjects/orc/testforpackets.py", line 9,
version = pt.get_tesseract_version()
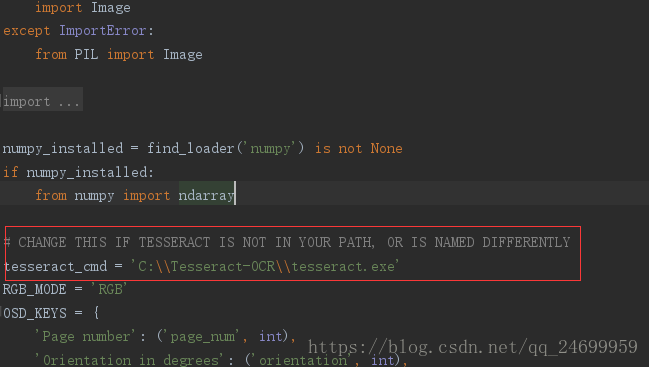
File "C:\Users 需要修改一下pytesseract.py中的tesseract_cmd指向的路徑
錯誤2
Error opening data file \Program Files (x86)\Tesseract-OCR\tessdata/eng.traineddata
Please make sure the TESSDATA_PREFIX environment variable is set to the parent directory of your "tessdata" directory.
Failed loading language 'eng'
Tesseract couldn't load any languages! 新增TESSDATA_PREFIX的環境變數,設定為安裝目錄下的tessdata目錄
如:C:\Tesseract-OCR\tessdata
如果還是不行請重啟電腦
相關推薦
Python 文字識別 安裝Tesseract ORC
Tesseract,一款由HP實驗室開發由Google維護的開源OCR(Optical Character Recognition , 光學字元識別)引擎,特點是開源,免費,支援多語言,多平臺。 下載地址:https://github.com/tesserac
圖片文字識別:Tesseract OCR庫在Python中基本使用
圖片識別:Tesseract OCR庫在Python中基本使用 一.Tesseract - Xmind的筆記 二. 程式碼案例: 基本使用程式碼 import pytesseract from
Python--文字識別--Tesseract
1.介紹 Tesseract 是一個 OCR 庫,目前由 Google 贊助(Google 也是一家以 OCR 和機器學習技術聞名於世的公司)。Tesseract 是目前公認最優秀、最精確的開源 OCR 系統。 除了極高的精確度,Tesseract 也具有很高
【python 文字識別】利用pytesseract庫進行圖片文字識別
關於中文的識別,效果比較好而且開源的應該就是Tesseract-OCR了,python 裡面也有一個包去使用Tesseract-OCR。 這個包 叫pytesseract 。 安裝pytesseract pip install pytesseract 除此之外
python36圖像文字識別安裝全過程
desktop pillow from -o ima 下載 .exe 安裝完成 目錄 1.安裝相應庫pip install pytesseractpip install pillow 2.下載並安裝tesseract-ocr鏈接:https://pan.baidu.com/
關於Python驗證碼識別安裝PIL、tesseract-ocr與pytesseract模組的錯誤解決
0x00:用Python進行驗證碼識別 近日接觸到了簡單web驗證碼識別的問題,安裝了 1、PIL 2、tesseract-ocr 3、pytesseract模組 0x01:然後是各種錯誤 (1): PIL for x64的不能正常安裝,原因是:
Tesseract-OCR-03-圖片文字識別
目錄名 sso 搜集 命令 發出 維護 結果 rac class Tesseract-OCR-03-圖片文字識別 本篇介紹使用 Tesseract-OCR 做圖片文字識別,識別手寫文字的時候,正確率能達到 90%,當訓練後正確率是極高的。這裏介紹的圖片文字識別,可以識別英文
Python配置圖片文字識別
ins 源代碼 logs 配置 mage pillow setup blog hub 以管理員權限打開cmd控制臺。 1.如何安裝PIL 輸入下面命令:pip install Pillow. 參考:https://www.cnblogs.com/mrgavin/
python學習----網頁圖片文字識別(簡單)
在接觸python後想對圖片進行一些處理 python實現的程式碼很簡單 但是關鍵在於一些包的匯入 我使用的python 軟體是 pycharm 可以在setting中去下載requests這個包 在安裝包PIL 和pytesseract這兩個包的時候 出
python呼叫百度圖片文字識別介面
# 登入百度api應用頁面獲取下面三相內容 APP_ID = 'xxxxx' API_KEY = 'xxxxxxx' SECRET_KEY = 'xxxxxxx' class BaiduImg(): def __init__(self, img_path): self.im
python 使用pytesseract圖片文字識別
python 使用pytesseract圖片文字識別 2017年03月02日 16:10:14 Saj_L 閱讀數:1742更多 個人分類: python 1. 安裝tesseract 下載地址:http://digi.bib.uni-mannheim.de/tesseract/t
linux安裝Tesseract文字提取
系統:CentOS7 1、安裝依賴包 依賴包: autoconf automake libtool libjpeg libpng libtiff zlib libjpeg-devel libpng-devel libtiff-devel zlib-devel 可以使用 rp
text-detection-ctpn 圖片文字識別 mac環境 cpu版安裝
1.git上下載原始碼 2.因為預設是gpu版本的,修改為不用gpu有幾個坑 把需要註釋的幾個地方註釋掉 然後修改setup.py, 用下面這段程式碼整個替換掉 from Cython.Build import cythonize import num
python自動識別文字編碼格式
#!/usr/bin/python3 # -*- coding: utf-8 -*- import codecs import os import chardet def detectCode(path): with open(path, 'rb') as file:
提取圖片文字——linux下tesseract-ocr安裝編譯
注:以下安裝以ubuntu16.04為例,本例中用到的檔案是1.71版的leptonica和3.04版的tesseract。不同的作業系統用到的檔案不同,請勿亂用。 一、Tesseract概述 Tesseract的OCR引擎最先由HP實驗室於1985年開始研發,
Python 利用百度文字識別 API 識別並提取圖片中文字
Python 利用百度文字識別 API 識別並提取圖片中文字 利用百度 AI 開發平臺的 OCR 文字識別 API 識別並提取圖片中的文字。首先需註冊獲取 API 呼叫的 ID 和 key,步驟如下: 開啟百度AI開放平臺,進入控制檯中的文字識別應用(需要有百度賬號)。
基於Eclipse下的 tesseract -OCR實現圖片文字識別過程簡單介紹
前言:最近忙於考研複習,好久沒有敲程式碼了,本人目前只是學生,寫部落格的目的只是為了記錄自己的學習過程,當然,如果能為他人提供一些幫助,那更好了。 一.Tesseract 簡介 Tesseract 是Ray Smith 在1985 - 1995年間在惠普布里斯托實驗室開發的一個ocr引擎(O
python使用百度aip文字識別
一、首先要有百度賬號 一般百度賬號都是通用的,如果沒有可以在百度AI開放平臺註冊一個賬號。 地址:http://ai.baidu.com 二、安裝sdk pip install baidu-aip 備註:在pycharm裡也可以在setting----Project I
基於百度AI的文字識別-Python
使用百度AI的文字識別庫,做出的呼叫示例,其中filePath是圖片的路徑,可以自行傳入一張帶有文字的圖片,進行識別。 下載baidu-aip這個庫,可以直接使用pip下載:pip install
Python程式設計:通過百度文字識別提取表格資料
百度文字識別文件: https://ai.baidu.com/docs#/OCR-Python-SDK/top 安裝sdk pip install baidu-aip 先建立應用,得到appid 要識別的表格圖片: 程式碼示例 from aip import