
實時流Streaming大資料:Storm,Spark和Samza
當前有許多分散式計算系統能夠實時處理大資料,這篇文章是對Apache的三個框架進行比較,試圖提供一個快速的高屋建瓴地異同性總結。
Apache Storm
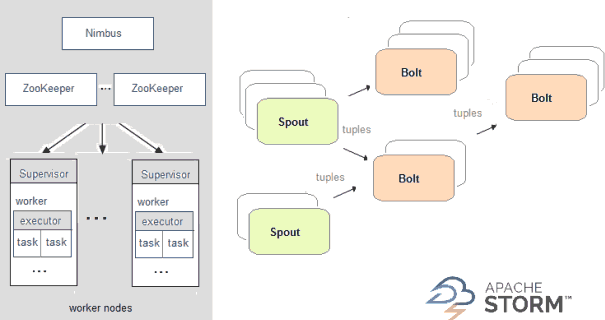
在Storm中,你設計的實時計算圖稱為toplogy,將其以叢集方式執行,其主節點會在工作節點之間分發程式碼並執行,在一個topology中,資料是在spout之間傳遞,它發射資料流作為不可變的key-value匹配集合,這種key-value配對值稱為tuple,bolt是用來轉換這些流如count計數或filter過濾等,bolt它們自己也可選擇發射資料到其它流處理管道下游的bolt。
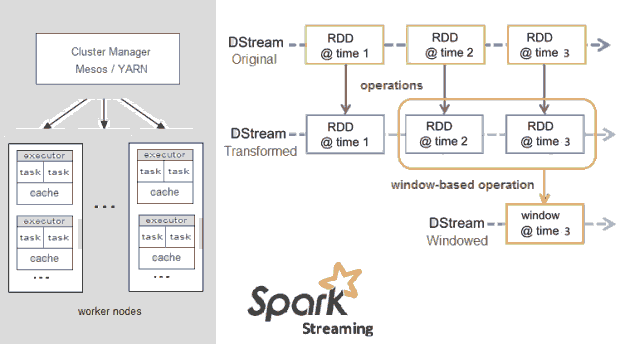
Apache Spark
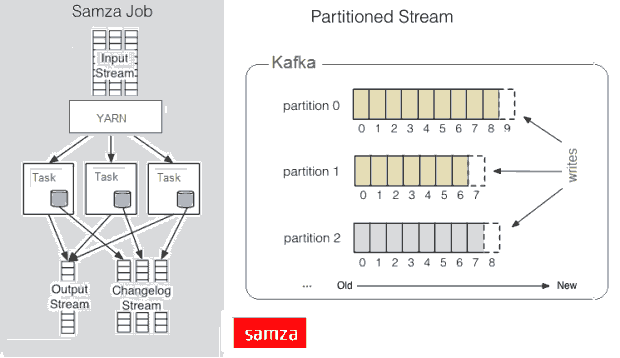
Apache Samza
Samza 的目標是將流作為接受到的訊息處理,同時,Samza的流初始元素並不是一個tuple或一個DStream,而是一個訊息,流被劃分到分割槽,每個分割槽是一個只讀訊息的排序的序列,每個訊息有一個唯一的ID(offset),系統也支援批處理,從同樣的流分割槽以順序消費幾個訊息,儘管Samza主要是依賴於Hadoop的Yarn和Apache Kafka,但是它的Execution & Streaming模組是可插拔的。
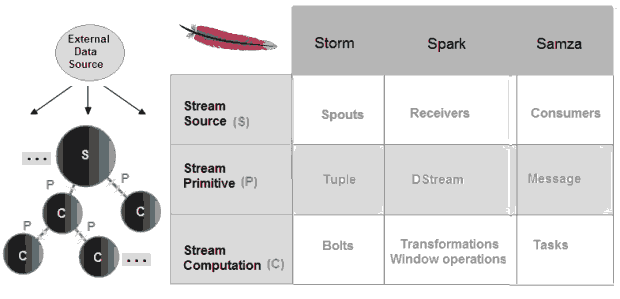
共同點
這三個實時計算系統都是開源的,低延遲的,分散式的,可擴充套件的和容錯的,他們都允許你在有錯誤恢復的叢集中通過並行任務執行流處理程式碼,他們也提供簡單的API抽象底層和複雜的實現。
這三個框架使用不同的詞彙表達相似的概念:
不同點
不同點總結如下表:

有三個delivery模式:
- At-most-once: 訊息也許丟失,這通常是最不理想的結果。
- At-least-once: 訊息可以被退回(沒有損失,但是會重複),這足夠支援很多用例場景了。
- Exactly-once: 每個訊息只傳遞一次,也只有一次(不會丟失,無重複),這是一個理想功能,在所有情況下很難達到。
另外一個方面是狀態管理,有許多不同的策略來儲存狀態,Spark Streaming寫資料到分散式檔案系統如HDFS,而Samza使用一個嵌入的key-value儲存,Storm則或在應用層使用自己的狀態管理,或使用一個高層次抽象稱為:Trident.
使用場景
所有這三個框架都特別適合處理連續的大量的實時資料,那麼選擇哪一個呢?並沒有硬性規則,基本是通用的指南。
如果你想要一個高速事件流處理系統,能夠進行增量計算,那麼Storm將非常適合,如果你還需要按需執行分散式計算,而客戶端正在同步等待結果,那麼你得在其外面使用分散式RPC(DRPC),最後但並非最不重要的是:因為Storm使用Apache Thrift,你能以任何語言編寫拓撲topology,如果你需要狀態持久或exactly-once傳遞,那麼你應當看看高級別的Trident API,它也提供微批處理(micro-batching)
使用Storm的公司有 Twitter, Yahoo!, Spotify, The Weather Channel...
談到微批處理,如果你必須有有態計算,exactly-once傳遞和不介意高延遲,你可以考慮Spark Streaming,特別如果計劃實現圖操作,機器學習或訪問SQL,Apache Spark能讓你通過結合Spark SQL, MLlib, GraphX幾個庫包實現,這些提供方便的統一的程式設計模型,特別是流演算法如流k-means允許Spark實時進行決策。
使用Spark有:Amazon, Yahoo!, NASA JPL, eBay Inc., Baidu
如果你有大量的狀態,比如每個分割槽有很多G位元組,Samza協同儲存和在同一機器處理的模型能讓你有效處理狀態,且不會塞滿記憶體。這個框架提供靈活的可插拔API:它的預設execution 訊息和儲存引擎能夠被你喜歡的選擇替代,更有甚者,如果你有很多流處理過程,它們分別來自於不同的程式碼庫不同的團隊,Samza細粒度的工作特點將特別適合,因為它們能最小的影響來進行加入和移除。
使用Samza公司有:LinkedIn, Intuit, Metamarkets, Quantiply, Fortscale…
相關推薦
實時流Streaming大資料:Storm,Spark和Samza
當前有許多分散式計算系統能夠實時處理大資料,這篇文章是對Apache的三個框架進行比較,試圖提供一個快速的高屋建瓴地異同性總結。 Apache Storm 在Storm中,你設計的實時計算圖稱為toplogy,將其以叢集方式執行,其主節點會在工作節點之間分發程式碼
【專治不明覺厲】之“大資料” Hadoop,Spark和Storm
虎嗅注:上一篇“專治不明覺厲”文章,虎嗅君為大家介紹了“雲端計算”領域中的那些“不明覺厲”的名詞。作為雲端計算最重要的應用,大資料領域也有很多看上去“不明覺厲”的詞彙。本篇文章,虎嗅君就為各位介紹“大資料”領域裡的“不明覺厲”。 大資料(Big Data) 大資料,官
大資料:Map終結和Spill檔案合併
當Mapper沒有資料輸入,mapper.run中的while迴圈會呼叫context.nextKeyValue就返回false,於是便返回到runNewMapper中,在這裡程式會關閉輸入通道和輸出通道,這裡關閉輸出通道並沒有關閉collector,必須要先flush一下。
大資料中的Spark和Hadoop的區別
大資料開發中Spark和Hadoop作為輔助模組受到了很大的歡迎,但是Spark和Hadoop區別在哪?哪種更適合我們呢,一起了解一下它們之間的區別。 Hadoop還會索引和跟蹤這些資料,讓大資料處理和分析效率達到前所未有的高度。Spark,則是那麼一個專門用來
流式大資料處理 (實時)的三種框架:Storm,Spark和Samza
摘要:許多分散式計算系統都可以實時或接近實時地處理大資料流。本文將對Storm、Spark和Samza等三種Apache框架分別進行簡單介紹,然後嘗試快速、高度概述其異同。 許多分散式計算系統都可以實時或接近實時地處理大資料流。本文將對三種Apache框架分別進行簡單介紹,
流式大資料處理的三種框架:Storm,Spark和Samza
許多分散式計算系統都可以實時或接近實時地處理大資料流。本文將對三種Apache框架分別進行簡單介紹,然後嘗試快速、高度概述其異同。Apache Storm在Storm中,先要設計一個用於實時計算的圖狀結構,我們稱之為拓撲(topology)。這個拓撲將會被提交給叢集,由叢集中
[BigData]流式大資料處理的三種框架:Storm,Spark和Samza
許多分散式計算系統都可以實時或接近實時地處理大資料流。本文將對三種Apache框架分別進行簡單介紹,然後嘗試快速、高度概述其異同。 Apache Storm 在Storm中,先要設計一個用於實時計算的圖狀結構,我們稱之為拓撲(topology)。這個拓撲將會被提交給叢集,由叢集中的主控節點(maste
流式大資料處理的三種框架:Storm,Spark和Flink
storm、spark streaming、flink都是開源的分散式系統,具有低延遲、可擴充套件和容錯性諸多優點,允許你在執行資料流程式碼時,將任務分配到一系列具有容錯能力的計算機上並行執行,都提供
處理大數據流常用的三種Apache框架:Storm、Spark和Samza。(主要介紹Storm)
領導 hdf 客戶端 orm 至少 per yar 持續性 apache 處理實時的大數據流最常用的就是分布式計算系統,下面分別介紹Apache中處理大數據流的三大框架: Apache Storm 這是一個分布式實時大數據處理系統。Storm設計用於在容錯和
大資料:spark叢集搭建
建立spark使用者組,組ID1000 groupadd -g 1000 spark 在spark使用者組下建立使用者ID 2000的spark使用者 獲取視訊中文件資料及完整視訊的夥伴請加QQ群:947967114useradd -u 2000 -g spark spark 設定密碼 passwd
Spark Streaming實時流處理筆記(6)—— Kafka 和 Flume的整合
1 整體架構 2 Flume 配置 https://flume.apache.org/releases/content/1.6.0/FlumeUserGuide.html 啟動kafka kafka-server-start.sh $KAFKA_HOME/config/se
Spark Streaming實時流處理筆記(1)——Spark-2.2.0原始碼編譯
1 下載原始碼 https://spark.apache.org/downloads.html 解壓 2 編譯原始碼 參考 https://www.imooc.com/article/18419 https://spark.apache.org/docs/2.2.2/bu
storm流式大資料處理流行嗎
在如今這個資訊高速增長的今天,資訊實時計算處理能力已經是一項專業技能了,正是因為有了這些需求的存在才使得分散式,同時具備高容錯的實時計算系統Storm才變得如此受歡迎,為什麼這麼說呢?下面看看新霸哥的介紹。 優點之一:高可靠性 對Storm有了解的朋友可能會知道sp
大資料求索(8):Spark Streaming簡易入門一
大資料求索(8):Spark Streaming簡易入門一 一、Spark Streaming簡單介紹 Spark Streaming是基於Spark Core上的一個應用程式,可伸縮,高吞吐,容錯(這裡主要是藉助Spark Core的容錯方式)處理線上資料流,資料可以有不同的來
大資料:Spark mlib(三) GradientDescent梯度下降演算法之Spark實現
1. 什麼是梯度下降?梯度下降法(英語:Gradient descent)是一個一階最優化演算法,通常也稱為最速下降法。 要使用梯度下降法找到一個函式的區域性極小值,必須向函式上當前點對應梯度(或者是近似梯度)的反方向的規定步長距離點進行迭代搜尋。先來看兩個函式:1. 擬合
大資料:Spark Core(二)Driver上的Task的生成、分配、排程
1. 什麼是Task?在前面的章節裡描述過幾個角色,Driver(Client),Master,Worker(Executor),Driver會提交Application到Master進行Worker上的Executor上的排程,顯然這些都不是Task.Spark上的幾個關係
大資料之Storm/實時資料處理視訊教程-李強強-專題視訊課程
大資料之Storm/實時資料處理視訊教程—28人已學習 課程介紹 大資料Storm實時資料處理視訊培訓課程:Strom是一個老牌的實時資料處理框架,在Spark Streaming流行前,Storm統治者整個流式計算的江湖。更詳細的說,Storm是一個實時資料處
大資料:Spark mlib(一) KMeans聚類演算法原始碼分析
1. 聚類1.1 什麼是聚類?所謂聚類問題,就是給定一個元素集合D,其中每個元素具有n個可觀察屬性,使用演算法將集合D劃分成k個子集,要求每個子集內部的元素之間相異度儘可能低,而不同子集的元素相異度儘可能高,其中每個子集叫做一個簇。1.2 KMeans 聚類演算法K-Mean
大資料:Spark Standalone 叢集排程(二)如何建立、分配Executors的資源
Standalone 的整體架構 在Spark叢集中的3個角色Client, Master, Worker, 下面的圖是Client Submit 一個任務的流程圖: 完整的流程:Driver 提交任務給Master, 由Master節點根據任務的引數對進行Worker
大資料:Spark Storage(二) 叢集下的broadcast
Spark BroadCast Broadcast 簡單來說就是將資料從一個節點複製到其他各個節點,常見用於資料複製到節點本地用於計算,在前面一章中討論過Storage模組中BlockManager,Block既可以儲存在記憶體中,也可以儲存在磁碟中,當Executor節點