
Precision,Recall and F1-measure 準確率、召回率以及綜合評價指標
阿新 • • 發佈:2018-12-17
通俗易懂,故轉一下。 轉自: http://www.cnblogs.com/bluepoint2009/archive/2012/09/18/precision-recall-f_measures.html
在資訊檢索和自然語言處理中經常會使用這些引數,下面簡單介紹如下:
1.準確率與召回率(Precision & Recall)
我們先看下面這張圖來加深對概念的理解,然後再具體分析。其中,用P代表Precision,R代表Recall
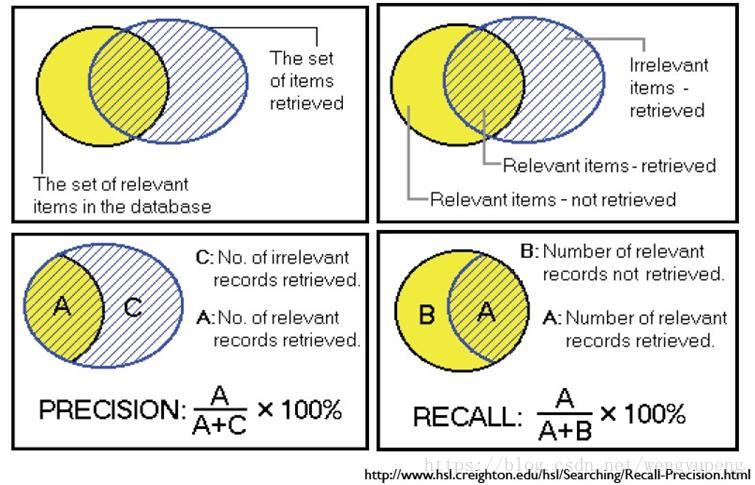
一般來說,Precision 就是檢索出來的條目中(比如:文件、網頁等)有多少是準確的,Recall就是所有準確的條目有多少被檢索出來了。
下面這張表介紹了True Positive,False Negative等常見的概念,P和R也往往和它們聯絡起來。
| Relevant | NonRelevant | |
| Retrieved | true positives (tp) | false positives(fp) |
| Not Retrieved | false negatives(fn) | true negatives (tn) |
那麼,
我們當然希望檢索的結果P越高越好,R也越高越好,但事實上這兩者在某些情況下是矛盾 的。比如極端情況下,我們只搜出了一個結果,且是準確的,那麼P就是100%,但是R就很低;而如果我們把所有結果都返回,那麼必然R是100%,但是P很低。
因此在不同的場合中需要自己判斷希望P比較高還是R比較高。如果是做實驗研究,可以繪製Precision-Recall曲線來幫助分析。
2. F1-Measure
前面已經講了,P和R指標有的時候是矛盾的,那麼有沒有辦法綜合考慮他們呢?我想方法肯定是有很多的,最常見的方法應該就是F-Measure了,有些地方也叫做F-Score,其實都是一樣的。
F-Measure是Precision和Recall加權調和平均:
當引數a=1時,就是最常見的F1了:
很容易理解,F1綜合了P和R的結果,當F1較高時則比較說明實驗方法比較理想。