
主題模型初學者指南[Python]
引言
近年來湧現出越來越多的非結構化資料,我們很難直接利用傳統的分析方法從這些資料中獲得資訊。但是新技術的出現使得我們可以從這些輕易地解析非結構化資料,並提取出重要資訊。
主題模型是處理非結構化資料的一種常用方法,從名字中就可以看出,該模型的主要功能就是從文字資料中提取潛在的主題資訊。主題模型不同於其他的基於規則或字典的搜尋方法,它是一種無監督學習的方法。
主題可以由語料庫中的共現詞項所定義,一個好的主題模型的擬合結果應該如下所示——“health”、“doctor”、“patient”、“hospital”構成醫療保健主題,而“farm”、“crops”、“wheat”則構成農業主題。
主題模型的適用領域有:文件聚類、資訊提取和特徵選擇。比如,紐約時報利用主題模型的結果來提升文章推薦引擎的功能。許多專家將主題模型應用到招聘領域中,利用主題模型來提取工作要求中的潛在資訊,並用模型的擬合結果來匹配候選人。此外,主題模型還被用於處理大規模的非結構化資料,如郵件、顧客評論和使用者社交資料。
如果你不熟悉主題模型的話,那麼本文將告訴你主題模型的原理以及如何利用Python來構建主題模型。
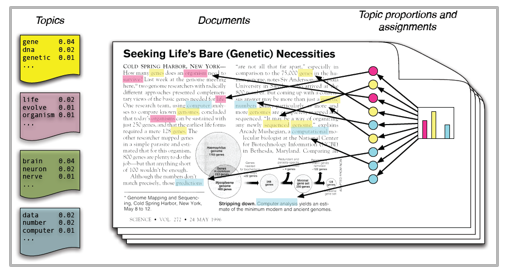 如果你不熟悉主題模型的話,那麼本文將告訴你主題模型的原理以及如何利用Python來構建主題模型。
如果你不熟悉主題模型的話,那麼本文將告訴你主題模型的原理以及如何利用Python來構建主題模型。目錄
- LDA(Latent Dirichlet Allocation) 模型
- LDA 模型的引數
- Python 實現過程
- 資料準備
- 資料清洗與預處理
- 計算文件詞頻矩陣
- 構建 LDA 模型
- 擬合結果
- 建議
- 頻數過濾法
- 標記過濾法
- Batch Wise LDA
- 特徵選擇
LDA 模型
我們可以用多種方法來處理文字資料,比如 TF 和 IDF 方法。LDA模型是最流行的主題模型,我們接下來將詳細介紹 LDA 模型。
LDA 模型假設文件是由一系列主題構成的,然後再從這些主題中依據相應的概率分佈生成詞語。給定一個文件資料集,LDA 模型主要用於識別文件中的主題分佈情況。
LDA 模型是一種矩陣分解技術,在向量空間模型中,任何語料都能被表示成一個文件詞頻矩陣。如下所示,矩陣中包含 N 篇文件,M 個詞語,矩陣中的數值表示詞語在文件中出現的頻率。
LDA 模型將上述的文件詞頻矩陣轉換成兩個低維的矩陣—— M1 和 M2。其中 M1 表示文件主題矩陣,M2 表示主題詞語矩陣,它們的維度分別是
N*K 和 K*M,K 表示文件中主題的個數,M 表示詞語的數量。
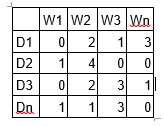 LDA 模型將上述的文件詞頻矩陣轉換成兩個低維的矩陣—— M1 和 M2。其中 M1 表示文件主題矩陣,M2 表示主題詞語矩陣,它們的維度分別是
N*K 和 K*M,K 表示文件中主題的個數,M 表示詞語的數量。
LDA 模型將上述的文件詞頻矩陣轉換成兩個低維的矩陣—— M1 和 M2。其中 M1 表示文件主題矩陣,M2 表示主題詞語矩陣,它們的維度分別是
N*K 和 K*M,K 表示文件中主題的個數,M 表示詞語的數量。 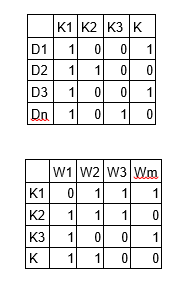
需要注意的是,上述兩個矩陣提供了文件主題和主題詞語的初始分佈情況,LDA 模型通過抽樣的方法來更新這兩個矩陣。該模型通過更新文件中每個詞語的主題歸屬情況來調整模型的引數值 p1 和 p2,其中 $p1 = p(\frac{topict}{documentd})$,$p2 = p(\frac{wordw}{topict})$。經過一系列的迭代計算後,LDA 模型達到收斂狀態,此時我們即可得到一組最佳引數值。
LDA 模型的引數
超引數 alpha 和 beta —— alpha 表示文件—主題密度,beta 則表示主題—詞語密度,其中 alpha 值越大表示文件中包含更多的主題,而更大的 beta 值則表示主題中包含更多的詞語。
主題中的詞數——這個引數取決於你的真實需求,如果你的目標是提取主題資訊,那麼你最好選擇較多的詞語。如果你的目標是提取特徵,那麼你應該選擇較少的詞項。
迭代次數—— LDA 演算法的迭代次數
Python 實現
資料準備
以下是一些示例資料:

資料清洗與預處理
資料清洗是文字建模分析過程中的一個重要環節,在這個過程中我們將移除標點符號、停止詞並規整資料集:

計算文件詞頻矩陣

構建 LDA 模型

擬合結果

建議
主題模型的擬合結果完全取決於語料庫中的特徵項,而語料是由一個稀疏的文件詞頻矩陣所構成的。降低該矩陣的維度可以提升主題模型的擬合結果,根據我的個人經驗,主要有以下幾個降維方法:
頻數過濾法
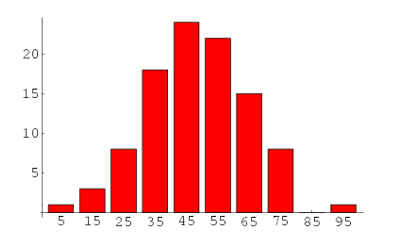
我們可以按照詞語的頻數進行排序,然後保留頻數較高的詞語並將頻數較低的詞語剔除掉。此外我們還可以藉助探索性分析的方法來決定如何設定閾值。
標記過濾法
通常情況下,標記過濾法的效果優於頻數過濾法。主題模型通過詞語的共現情況來反映主題資訊,然而在每個主題中並不是所有的詞語都是同等重要的。我們可以將這些無關緊要的詞語剔除掉,提升模型的擬合效果。
Batch Wise LDA
為了提取出文件中最重要的主題資訊,我們可以將語料庫分割成一系列固定大小的子集。然後我們可以對每個子集資料構建多個 LDA 模型,出現次數最多的主題就是該文件中最重要的主題資訊。
特徵選擇
有些時候,我們還可以利用 LDA 模型來選擇特徵。以文字分類問題為例,如果訓練集中包含多個類別的文件,我們可以首先構建 LDA 模型,然後剔除掉不同類別文件中共同出現的主題資訊,剩餘的特徵即為有助於提升文字分類模型的準確率。
結語
到此為止,我們已經介紹完主題模型了,我希望本文能夠幫你瞭解如何處理文字資料。如果你想加深對主題模型的理解,那麼我建議你最好親自練習下本文的程式碼並檢查模型的擬合結果。
相關推薦
主題模型初學者指南[Python]
引言 近年來湧現出越來越多的非結構化資料,我們很難直接利用傳統的分析方法從這些資料中獲得資訊。但是新技術的出現使得我們可以從這些輕易地解析非結構化資料,並提取出重要資訊。 主題模型是處理非結構化資料的一種常用方法,從名字中就可以看出,該模型的主要功能就是從文字資料中提
初試主題模型LDA-基於python的gensim包
rpo nco reload tps 代碼 list sdn str height http://blog.csdn.net/a_step_further/article/details/51176959 LDA是文本挖掘中常用的主題模型,用來從大量文檔中提取出最能表達各個
在PYTHON中使用TMTOOLKIT進行主題模型LDA評估
統一 進行 常量 註意 參數 cti 8.0 數列 ng- 主題建模的英文一種在大量文檔中查找抽象藝術主題藝術的方法。有了它,就有可能發現隱藏或“潛在”主題的混合,這些主題因給定語料庫中的文檔而異。一種作為監督無的機器學習方法,主題模型不容易評估,因為沒有標記的“基礎事實”
《PYTHON程式設計初學者指南》pdf
這本電子書是我偶然在網上買的別人的付費資源,現在免費分享給大家。 需要這本書pdf版的朋友,可掃文末二維碼加博主好友免費獲取。 //為了不影響排版,所以放在最後啦..... 以下是本書的一些介紹: 【作 者】(美)道森著 【形態項】 392 【出版項】 北
lda主題模型python實現篇
個人部落格地址:http://xurui.club/2018/06/01/lda/ 最近在做一個動因分析的專案,自然想到了主題模型LDA。這次先把模型流程說下,原理後面再講。 lda實現有很多開源庫,這裡用的是gensim. 1 文字預處理 大概說下文字
主題模型 LDA 入門(附 Python 程式碼)
一、主題模型 在文字挖掘領域,大量的資料都是非結構化的,很難從資訊中直接獲取相關和期望的資訊,一種文字挖掘的方法:主題模型(Topic Model)能夠識別在文件裡的主題,並且挖掘語料裡隱藏資訊,並且在主題聚合、從非結構化文字中提取資訊、特徵選擇等場景有廣泛的
LDA主題模型及python實現
LDA(Latent Dirichlet Allocation)中文翻譯為:潛在狄利克雷分佈。LDA主題模型是一種文件生成模型,是一種非監督機器學習技術。它認為一篇文件是有多個主題的,而每個主題又對應著不同的詞。一篇文件的構造過程,首先是以一定的概率選擇某個主題,然後再在這個主題下以一定
終極指南:構建用於檢測汽車損壞的Mask R-CNN模型(附Python演練)
介紹 計算機視覺領域的應用繼續令人驚歎著。從檢測視訊中的目標到計算人群中的人數,計算機視覺似乎沒有無法克服的挑戰。 這篇文章的目的是建立一個自定義Mask R-CNN模型,可以檢測汽車上的損壞區域(參見上面的影象示例)。這種模型的基本應用場景為,如果使用
LDA主題模型原理解析與python實現
LDA(Latent dirichlet allocation)[1]是有Blei於2003年提出的三層貝葉斯主題模型,通過無監督的學習方法發現文字中隱含的主題資訊,目的是要以無指導學習的方法從文字中發現隱含的語義維度-即“Topic”或者“Concept”。隱性語義分析的
用scikit-learn學習LDA主題模型
大小 href 房子 鏈接 size 目標 文本 訓練樣本 papers 在LDA模型原理篇我們總結了LDA主題模型的原理,這裏我們就從應用的角度來使用scikit-learn來學習LDA主題模型。除了scikit-learn, 還有spark MLlib和gen
Spark機器學習(8):LDA主題模型算法
算法 ets 思想 dir 骰子 cati em算法 第一個 不同 1. LDA基礎知識 LDA(Latent Dirichlet Allocation)是一種主題模型。LDA一個三層貝葉斯概率模型,包含詞、主題和文檔三層結構。 LDA是一個生成模型,可以用來生成一篇文
LDA主題模型
.com img png src 技術 nbsp ima blog com LDA主題模型
統計參數語音合成的初學者指南
專註 global 地址 .org 衡量 nco format represent feature 原文地址鏈接:https://shartoo.github.io/texttospeech/ 譯自:A beginners’ guide to statistical p
比特幣這麽火熱,看看這篇比特幣初學者指南
htm 愛好者 新增 wechat 如何 通過 中新 人的 說明 原文:ruanyifeng.com/blog/2018/01/bitcoin-tutorial.html 作者: 阮一峰 如有侵權,請及時聯系,謝謝! 2017 年對比特幣來說,是極為瘋狂的一年。
Familia:百度NLP開源的中文主題模型應用工具包
ica 用戶 font 文本內容分析 adb 文本相似度 表示 2.0 wiki 參考:Familia的Github項目地址、百度NLP專欄介紹 Familia 開源項目包含文檔主題推斷工具、語義匹配計算工具以及基於工業級語料訓練的三種主題模型:Latent Dir
Hulu機器學習問題與解答系列 | 十九:主題模型
cat jpeg ebp sel onf earch -s 2nf aic 今天的內容是 【主題模型】 場景描述 基於Bag-Of-Words(或N-gram)的文本表示模型有一個明顯的缺陷,就是無法識別出不同的詞(或詞組)具有相同主題的情況。我們需要一種技術能夠將具有
大O符號初學者指南
ner ont 計算機 org 增加 str 數據 contain 如果 原文地址:https://rob-bell.net/2009/06/a-beginners-guide-to-big-o-notation/ 計算機科學中,大O表示法被用來描述一個算法的性能或復雜度。
LDA主題模型三連擊-入門/理論/代碼
矩陣 ota 函數 dom 主題模型 估計 chart news span 本文將從三個方面介紹LDA主題模型——整體概況、數學推導、動手實現。 關於LDA的文章網上已經有很多了,大多都是從經典的《LDA 數學八卦》中引出來的,原創性不太多。 本文將用盡量少的公式,跳過不
Nginx初學者指南
direct ror trie bsp ear sin explain err outside Beginner’s Guide Starting, Stopping, and Reloading ConfigurationConfiguration File’s S
深網與暗網初學者指南
信息 瀏覽器 付費 需要 必須 fire 經濟 提供商 invisible 一、深網 深網是互聯網上無法通過普通方法訪問到的內容,這些普通的方法包括使用谷歌、百度等搜索引擎。深網的內容主要是一些需要某些條件如註冊、付費,才能訪問的內容,如數據庫和某些服務。 下面是訪問深網的