
某招聘網資訊統計視覺化
0x00 前言
資料截至:2016.02.23
你應該猜到是哪個網站了,用python3寫了個多執行緒(非同步也不錯)+多代理爬蟲,大致實現是在執行中不斷往資料庫加入新代理,在獲取中把無效代理去掉及將任務ID添加回佇列,最後剩下穩定的代理迴圈使用,也要限制一下每個代理的訪問頻率,這樣可突破反爬蟲機制,資料庫用mysql(資料量小,感覺用什麼沒多大關係),抓取了招聘公司+招聘資訊(含崗位需求),其實也就想看看一些資訊彙總資料!
有效資訊比
- 公司資訊:71488/105958
- 招聘資訊:813023/1445026
0x01 資料處理
按首頁分類及工作年限分組統計最低平均、最高平均及兩者平均
抓取分類
使用urllib.reuquest抓取後用BeautifulSoup解析
html = rullib.request.urlopen(url).read().decode('utf-8')
soup = BeautifulSoup(html, 'lxml')然後解析為樹形結構資料,類似如下
技術
- 後端開發
- - Java
- - Python
- - PHP
- - .NET
- - C#
- - C++
······
- - Shell
- - 後端開發其它
- 移動開發
- - HTML5
- - Android
- - iOS
這裡取最後一層進行like匹配,匹配之前得處理以下順序,比如C在C++前,匹配時C++就會歸類到C裡(like ‘%C%’),所以需將長度短的放後邊,排序一下(上面有兩個HTML5(前端開發和移動開發)及大小寫區分沒有處理,也可以試試按長度)
for i in range(len(menu)):
for j in range(len(menu)):
if menu[j] in menu[i]:
menu[i], menu[j] = menu 分組統計
排完後用python迴圈拼接成SQL語句放資料庫查詢
CASE WHEN (`title` LIKE "%JavaScript%") THEN "JavaScript"
······
WHEN (`title` LIKE "%副總裁%") THEN "副總裁"
ELSE '其他'
END AS "title"工作經驗類似,也用CASE處理以下,有些記錄欄位不規範,比如會出現1-3年、1-3 年這種情況
CASE WHEN (`seniority` LIKE "%應屆畢業生%") THEN "應屆畢業生"
WHEN (`seniority` LIKE "%1年以下%") THEN "1年以下"
WHEN (`seniority` LIKE "%1-3%") THEN "1-3年"
WHEN (`seniority` LIKE "%3-5%") THEN "3-5年"
WHEN (`seniority` LIKE "%5-10%") THEN "5-10年"
WHEN (`seniority` LIKE "%10年以上%") THEN "10年以上"
ELSE "經驗不限"
END AS "seniority"然後按這兩個進行分組平均統計薪資(ct字典是記錄數量)
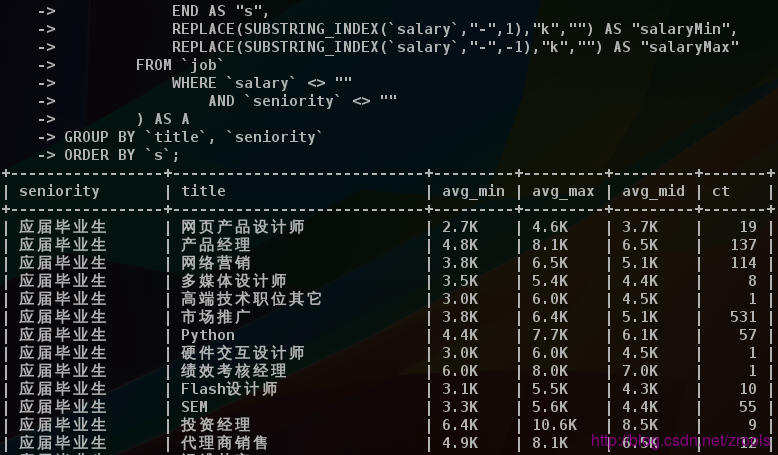
資料整合
最後把資料與前邊的分類連線到一起,形成的json資料如下
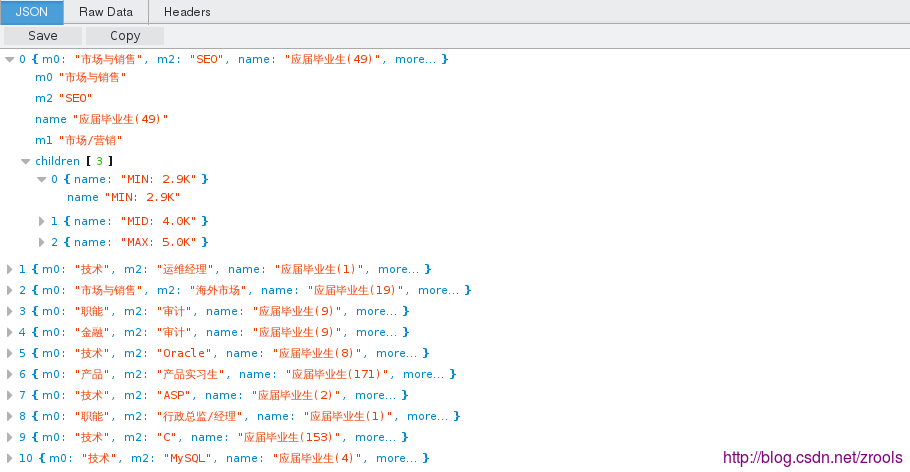
因為還不是樹形結構,還需要使用d3js.nest()來處理(因為我嫌麻煩,就按一條一條記錄封裝扔前端處理)
0x02 資料視覺化
d3js視覺化除了能放大縮小之外,還有個好處是可以使用CTRL+F快速搜尋定位
平均薪資
有了樹形json,可以d3官方demo直接傳入就可以了(資料有點量大,不然可以精確到城市整個大圖),經驗後的數量是統計的記錄數

生成影象1280x96000尺寸剛合適,還可以玩玩其他姿勢,比如打包圖、圓形圖等
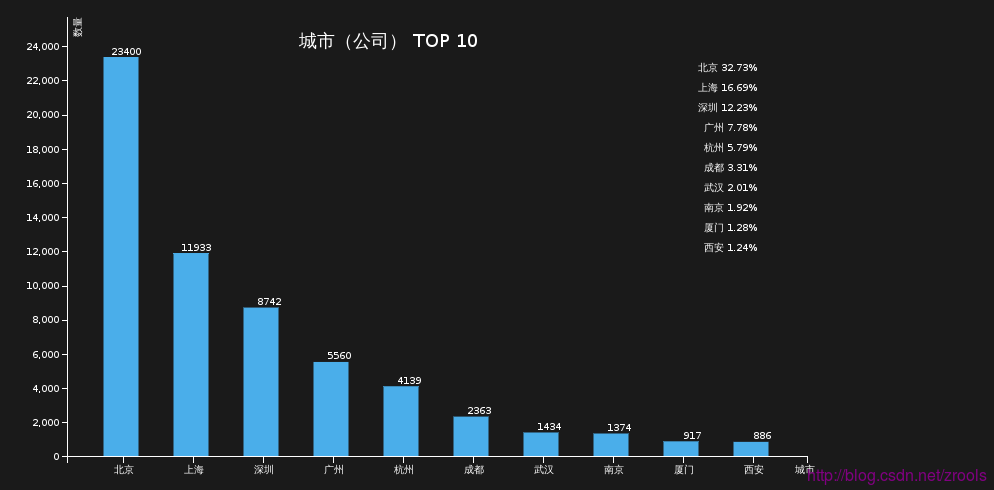
城市(公司)TOP 10
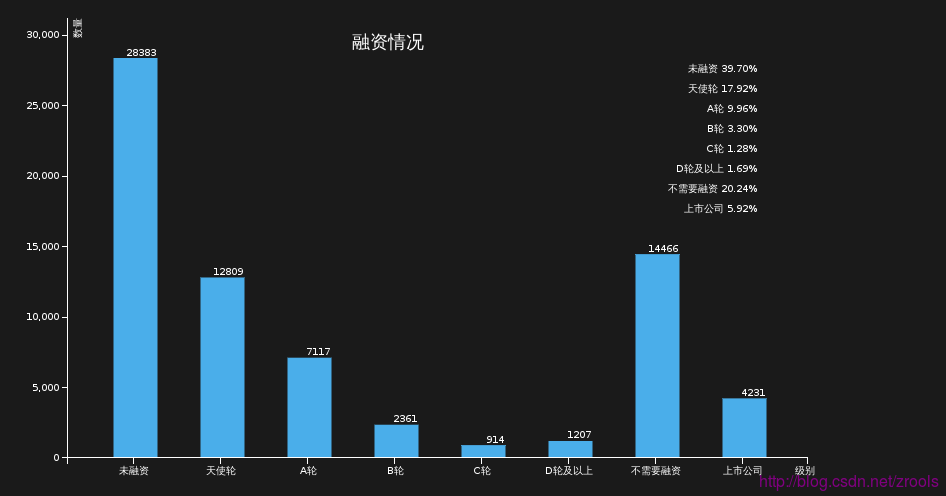
融資比例
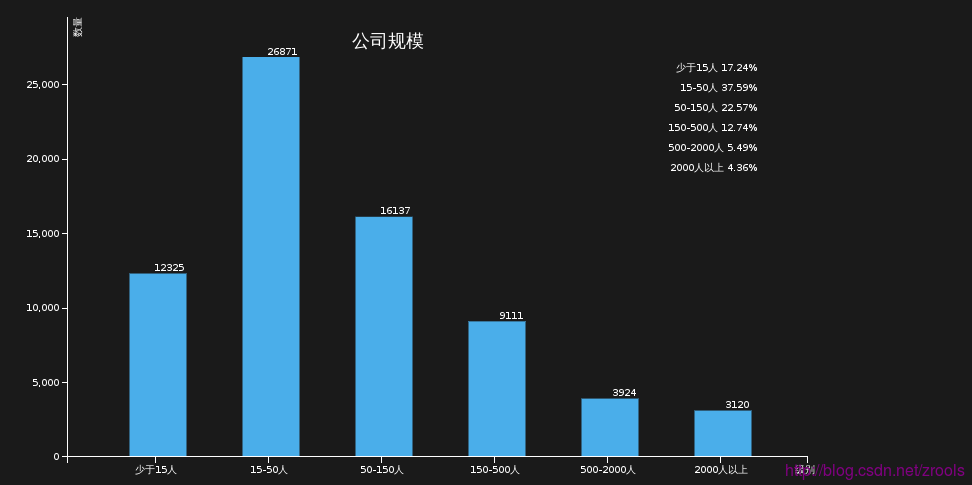
公司規模
其他
其他的還可以分析下走向、各職位關鍵字頻率等。。。