
Single Shot MultiBox Detector論文翻譯【修改】
這幾天讀了SSD論文的原理部分,看了別人的翻譯,發現很多應該都是google直接翻譯過來的,有些地方讀的不是很通順,自己就在自己的理解和搜尋的基礎上對我看的那篇翻譯做了一些修改。【原文地址:http://noahsnail.com/2017/12/11/2017-12-11-Single%20Shot%20MultiBox%20Detector%E8%AE%BA%E6%96%87%E7%BF%BB%E8%AF%91%E2%80%94%E2%80%94%E4%B8%AD%E8%8B%B1%E6%96%87%E5%AF%B9%E7%85%A7/】
SSD: Single Shot MultiBox Detector
摘要
我們提出了一種使用單個深度神經網路來檢測影象中的目標的方法。我們的方法命名為SSD,將邊界框的輸出空間離散化為不同長寬比的一組預設框該預設框在每個特徵圖位置有不同的寬高比和尺寸。在預測時,網路會在每個預設框中為每個出現的目標類別生成分數,並對框進行調整以更好地匹配目標形狀。此外,網路還結合了不同解析度的多個特徵對映的預測,自然地處理各種尺寸的目標。相對於需要目標提出【object proposals】的方法,SSD非常簡單,因為它完全消除了提出生成和隨後的畫素或特徵重新取樣階段,並將所有計算封裝到單個網路中。這使得SSD易於訓練和直接整合到需要檢測元件的系統中。PASCAL VOC,COCO和ILSVRC資料集上的實驗結果證實,SSD對於利用額外的目標提出步驟的方法具有競爭性的準確性,並且速度更快,同時為訓練和推斷提供了統一的框架。對於300×300的輸入,SSD在VOC2007測試中以59FPS的速度在Nvidia Titan X上達到74.3%74.3%的mAP,對於512×512的輸入,SSD達到了76.9%76.9%的mAP,優於參照的最先進的Faster R-CNN模型。與其他單階段方法相比,即使輸入影象尺寸較小,SSD也具有更高的精度。程式碼獲取:
評價指標不知道是什麼的看這篇文章:https://blog.csdn.net/qq_36396104/article/details/85230012
1. 引言
目前最先進的目標檢測系統是以下方法的變種:假設邊界框,對每個框重新取樣畫素或特徵,再應用一個高質量的分類器。自從選擇性搜尋[1]通過在PASCAL VOC,COCO和ILSVRC上所有基於Faster R-CNN[2]的檢測都取得了當前領先的結果(儘管具有更深的特徵如[3]),這種流程在檢測基準資料上流行開來。儘管這些方法準確,但對於嵌入式系統而言,這些方法的計算量過大,即使是高階硬體,對於實時應用而言也太慢。通常,這些方法的檢測速度是以每幀秒(SPF)度量,甚至最快的高精度檢測器,Faster R-CNN,僅以每秒7幀(FPS)的速度執行。已經有很多嘗試通過處理檢測流程中的每個階段來構建更快的檢測器(參見第4節中的相關工作),但是到目前為止,顯著提高的速度僅以顯著降低的檢測精度為代價。
本文提出了第一個基於深度網路的目標檢測器,它不對邊界框假設的畫素或特徵進行重取樣,並且與其它方法有一樣精確度。這對高精度檢測在速度上有顯著提高(在VOC2007測試中,59FPS和74.3%74.3%的mAP,與Faster R-CNN 7FPS和73.2%73.2%的mAP或者YOLO 45 FPS和63.4%63.4%的mAP相比)。速度的根本改進來自消除邊界框提出和隨後的畫素或特徵重取樣階段。我們並不是第一個這樣做的人(查閱[4,5]),但是通過增加一系列改進,我們設法了之前嘗試的方法的準確性。我們的改進包括使用小型卷積濾波器來預測邊界框位置中的目標類別和偏移量,使用不同長寬比檢測的單獨預測器(濾波器),並將這些濾波器應用於網路後期的多個特徵對映中,以執行多尺度檢測。通過這些修改——特別是使用多層進行不同尺度的預測——我們可以使用相對較低的解析度輸入實現高精度,進一步提高檢測速度。雖然這些貢獻可能單獨看起來很小,但是我們注意到由此產生的系統將PASCAL VOC實時檢測的準確度從YOLO的63.4%63.4%的mAP提高到我們的SSD的74.3%74.3%的mAP。相比於最近備受矚目的殘差網路方面的工作[3],在檢測精度上這是相對更大的提高。而且,顯著提高的高質量檢測速度可以擴大計算機視覺使用的設定範圍。
我們總結我們的貢獻如下:
-
我們引入了SSD,這是一種針對多個類別的單次檢測器,比先前的先進的單次檢測器(YOLO)更快,並且準確得多,事實上,與執行顯式區域提出和池化的更慢的技術具有相同的精度(包括Faster R-CNN)。
-
SSD的核心是使用小卷積濾波器來預測特徵圖上固定的一組預設邊界框的類別和位置偏移。
-
為了實現高檢測精度,我們根據不同尺度的特徵對映生成不同尺度的預測,並通過縱橫比明確分開預測。
-
這些設計功能使得即使在低解析度輸入影象上也能實現簡單的端到端訓練和高精度,從而進一步提高速度與精度之間的權衡。
-
實驗包括在PASCAL VOC,COCO和ILSVRC上評估具有不同輸入大小的模型的時間和精度分析,並與最近的一系列最新方法進行比較。
2. 單次檢測器(SSD)
本節描述我們提出的SSD檢測框架(2.1節)和相關的訓練方法(2.2節)。之後,2.3節介紹了資料集特有的模型細節和實驗結果。
2.1 模型
SSD方法基於前饋卷積網路,該網路產生固定大小的邊界框集合,並對這些邊界框中存在的目標類別例項進行評分,然後進行非極大值抑制步驟來產生最終的檢測結果。早期的網路層基於用於高質量影象分類的標準架構(在任何分類層之前被截斷),我們將其稱為基礎網路。然後,我們將輔助結構新增到網路中以產生具有以下關鍵特徵的檢測:
用於檢測的多尺度特徵對映。我們將卷積特徵層新增到擷取的基礎網路的末端。這些層在尺寸上逐漸減小,並得到多個尺度檢測的預測值。用於預測檢測的卷積模型對於每個特徵層都是不同的(查閱Overfeat[4]和YOLO[5]在單尺度特徵對映上的操作)。
用於檢測的卷積預測器。每個新增的特徵層(或者任選的來自基礎網路的現有特徵層)可以使用一組卷積濾波器產生固定的檢測預測集合。這些在圖2中的SSD網路架構的上部指出。對於具有p個通道的大小為m×n的特徵層,使用3x3xp卷積核卷積操作,產生類別的分數或生成相對於預設框的座標偏移。在應用卷積核運算的m×n大小位置處,它會產生一個輸出值。邊界框偏移輸出值是相對於預設框測量,預設框位置則相對於特徵圖(查閱YOLO[5]的架構,該步驟使用中間全連線層而不是卷積濾波器)。
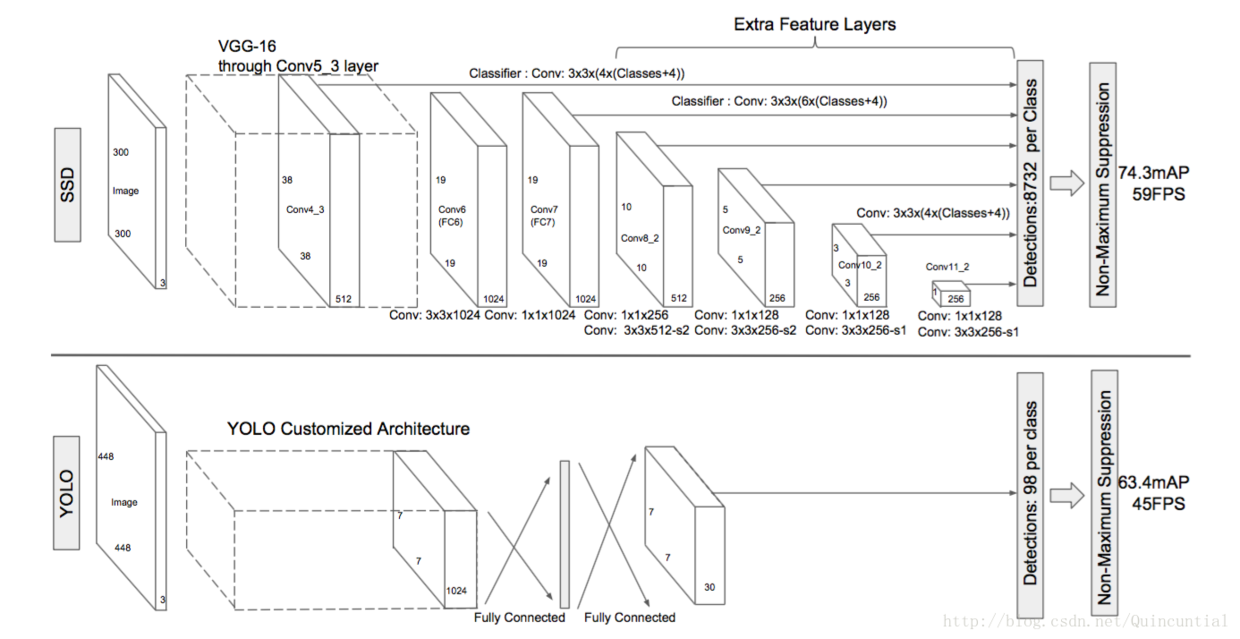
圖2:兩個單次檢測模型的比較:SSD和YOLO[5]。我們的SSD模型在基礎網路的末端添加了幾個特徵層,它預測了不同尺度和長寬比的預設邊界框的偏移量及其相關的置信度。300×300輸入尺寸的SSD在VOC2007 test上的準確度上明顯優於448×448的YOLO的準確度,同時也提高了速度。
預設邊界框和長寬比。對於網路頂部的多個特徵對映,我們將一組預設邊界框與頂層網路每個特徵圖單元關聯。預設邊界框以卷積的方式平鋪特徵對映,以便每個邊界框相對於其對應單元的位置是固定的。在每個特徵對映單元中,我們預測單元中相對於預設邊界框形狀的偏移量,以及指出每個邊界框中存在的每個類別例項的類別的分數。具體而言,對於給定位置處的k個邊界框中的每一個,我們計算cc個類別分數和相對於原始預設邊界框形狀的44個偏移量。這導致在特徵對映中的每個位置周圍應用總共(c+4)k個濾波器,對於m×n的特徵對映取得(c+4)kmn個輸出。有關預設邊界框的說明,請參見圖1。我們的預設邊界框與Faster R-CNN[2]中使用的錨邊界框相似,但是我們將它們應用到不同解析度的幾個特徵對映上。在多個特徵圖中使用不同的預設框形狀,可以有效地離散可能的輸出框形狀空間。
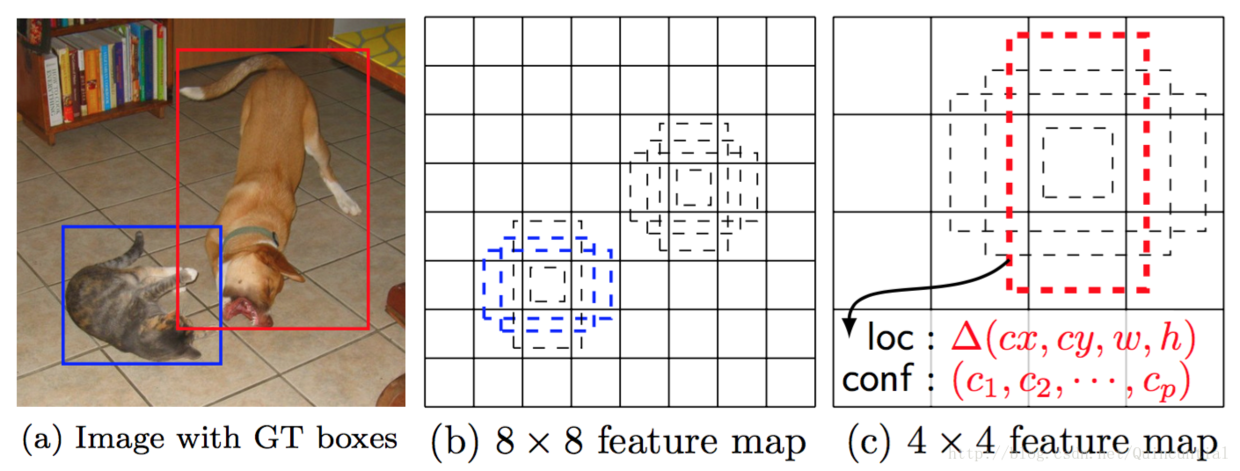
圖1:SSD框架。(a)在訓練期間,SSD僅需要每個目標的輸入影象和真實邊界框。以卷積方式,我們在具有不同尺度的若干特徵圖中的每個位置處評估不同橫款比的預設框小集合(例如4個)。對於每個預設邊界框,我們預測所有目標類別((c1,c2,…,cp)(c1,c2,…,cp))的形狀偏移量和置信度。在訓練時,我們首先將這些預設邊界框與實際的邊界框進行匹配。例如,我們已經與貓匹配兩個預設邊界框,與狗匹配了一個,這些框視為正樣本,其餘的視為負樣本。模型損失是定位損失(例如,Smooth L1[6])和置信度損失(例如Softmax)之間的加權和。
2.2 訓練
訓練SSD和訓練使用區域提出【region proposals】的典型檢測器之間的關鍵區別在於,需要將真實標籤資訊分配給固定的檢測器輸出集合中的特定輸出。在YOLO[5]的訓練中、Faster R-CNN[2]和MultiBox[7]的區域提出【region proposals】階段,一些版本也需要這樣的操作。一旦確定了這個分配,就可以端到端地應用損失函式和反向傳播。訓練也涉及選擇用於檢測的預設框和尺度集合,以及難例挖掘【hard negative mining】和資料增強策略。
匹配策略。在訓練過程中,我們需要建立真實標籤和預設框之間的對應關係,並相應地訓練網路。對於每個實際邊界框,我們從預設邊界框中選擇,這些框會在位置,長寬比和尺度上變化。我們首先將每個實際邊界框與具有最好的Jaccard重疊(如MultiBox[7])的預設框相匹配。與MultiBox不同的是,我們匹配預設邊界框與實際邊界框的Jaccard重疊高於閾值(0.5)的預設邊界框。這簡化了學習問題,允許網路在有多個重疊的預設邊界框時獲得高置信度,而不是要求它只挑選具有最大重疊的一個邊界框。
訓練目標函式。SSD訓練目標函式來自於MultiBox[7,8],但我們將其擴充套件到可以處理多個物件目標類別。以![]()
![]() 表示第i個預設邊界框與類別p的第j個實際標籤框相匹配。在上面的匹配策略中,我們可以得出
表示第i個預設邊界框與類別p的第j個實際標籤框相匹配。在上面的匹配策略中,我們可以得出![]()
![]() 意味著可以有多於一個的與第j個真實標籤框相匹配的預設框。總體目標損失函式是定位損失(loc)和置信度損失(conf)的加權和:
意味著可以有多於一個的與第j個真實標籤框相匹配的預設框。總體目標損失函式是定位損失(loc)和置信度損失(conf)的加權和:
![]()
其中N是匹配的預設邊界框的數量。如果N=0,則將損失設為0。位置損失是預測框(l)與真實標籤框(g)引數之間的Smooth L1損失[6]。類似於Faster R-CNN[2],我們迴歸預設邊界框(d)的中心偏移量(cx,cy)和其寬度(w)、高度(h)的偏移量。
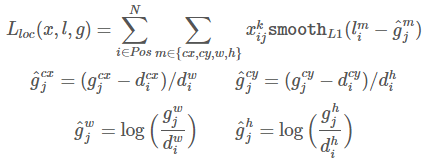
置信度損失是在多類別置信度(c)上的softmax損失。

通過交叉驗證權重項α設為1。
選擇預設框的尺度和橫寬比。為了處理不同尺度的目標,一些方法[4,9]建議在不同的尺寸下處理這些影象,然後將結果合併。然而,通過利用單個網路中幾個不同層的feature map進行預測,我們可以得到類似的效果,同時還可以在所有尺度的目標下共享引數。以前的工作[10,11]已經表明,使用來自較低層的特徵圖可以提高語義分割的質量,因為低層可以捕獲到輸入目標的更多細節。同樣,[12]表明,新增從高層特徵圖下采樣的全域性文字可以有助於平滑分割結果。受這些方法的啟發,我們使用較低層和較高層的特徵圖進行檢測預測。圖1顯示了框架中使用的兩個示例性特徵對映(8×8和4×4)。在實踐中,我們可以使用更多的具有很少計算開支的特徵對映。
已知網路中不同層的特徵圖具有不同的(經驗的)感受野大小[13]。幸運的是,在SSD框架內,預設邊界框不需要對應於每層的實際感受野。我們設計平鋪預設邊界框,以便特定位置的特徵圖可以學習響應於影象的特定區域和物件的特定尺度。假設我們要使用mm個特徵圖進行預測。每個特徵圖預設邊界框的尺度計算如下:
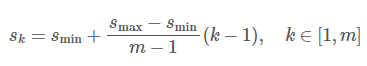
其中smin為0.2,smax為0.9,意味著最低層具有0.2的尺度,最高層具有0.9的尺度,並且在它們之間的所有層是規則間隔的。我們為預設邊界框新增不同的長寬比,並將它們表示為ar∈1,2,3,1/2,1/3。我們可以計算每個邊界框的寬度(![]()
![]() )和高度(
)和高度(![]()
![]() )。對於長寬比為1,我們還添加了一個預設邊界框,其尺度為
)。對於長寬比為1,我們還添加了一個預設邊界框,其尺度為![]()
![]() ,從而在每個特徵圖位置得到6個預設邊界框。我們將每個預設邊界框的中心設定為(
,從而在每個特徵圖位置得到6個預設邊界框。我們將每個預設邊界框的中心設定為(![]()
![]() ),其中|fk|是第k個平方特徵對映的大小,
),其中|fk|是第k個平方特徵對映的大小,![]()
![]() 。在實踐中,也可以設計預設邊界框的分佈以最適合特定的資料集。平鋪預設邊界框也是一個開放性的設計。
。在實踐中,也可以設計預設邊界框的分佈以最適合特定的資料集。平鋪預設邊界框也是一個開放性的設計。
通過組合許多特徵圖在所有位置上的具有不同尺寸和寬高比的預設框的預測,我們具有不同多樣化的預測集合,涵蓋各種輸入物件尺寸和形狀。例如,在圖1中,狗被匹配到4×4特徵圖中的預設邊界框,而不是8×8特徵圖中的任何預設框。這是因為那些邊界框有不同的尺度,但不匹配狗的邊界框,因此在訓練期間被認為是負樣本。
難例挖掘【hard negative mining】。在匹配步驟之後,大多數預設邊界框為負樣本,尤其是當可能的預設邊界框數量較多時。這導致了訓練期間正負樣本的嚴重不均衡。我們不使用所有的負樣本,而是使用每個預設邊界框的最高置信度loss來對它們排序,並挑選前面的置信度,以便負樣本和正樣本之間的比例至多為3:1。我們發現這會帶來更快的優化和更穩定的訓練。
資料增強。為了使模型對各種輸入目標大小和形狀更魯棒,每張訓練影象都是通過以下選項之一進行隨機取樣的:
- 使用整個原始輸入影象。
- 取樣一個影象塊,使得與目標之間的最小Jaccard重疊為0.1,0.3,0.5,0.7或0.9。
- 隨機取樣一個影象塊。
每個取樣影象塊的大小是原始影象大小的[0.1,1],長寬比在1212和2之間。如果實際邊界框的中心在採用的影象塊中,我們保留實際邊界框與取樣影象塊的重疊部分。在上述取樣步驟之後,除了應用類似於文獻[14]中描述的一些光度變形之外,將每個取樣影象塊調整到固定尺寸並以0.5的概率進行水平翻轉。