
論文筆記 | SSD: Single Shot MultiBox Detector
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg

Wei Liu
Abstract
Our approach, named SSD, discretizes the output space of bounding boxes into a set of default boxes over different aspect ratios and scales per feature map location. At prediction time, the network generates scores for the presence of each object category in each default box and produces adjustments to the box to better match the object shape. Additionally, the network combines predictions from multiple feature maps with different resolutions to naturally handle objects of various sizes. And it completely eliminates proposal generation and subsequent pixel or feature resampleing stage and encapsulate all computation in a single network.
1 Introduction
This paper presents the first deep network based object detector that does not resample pixels or features for bounding box hypothese and is as accurate as approaches that do.
Our improvements include using a small convlutional filter to predict object categories and offsets in bounding box locations, using separate predictors(filters) for different aspect ratio detections, and applying these filters to multiple feature maps from the later stages of a network in order to perform detection using at multiple scales.
We summarize our contributions as follows:
1. Faster than YOLO, and more accurate. as accurates as slower techinques.
2. The core of the SSD approach is predicting category scores and box offsets for a fixed set of default bounding boxes using small convolutional filters applied to feature maps.
3. We produce predictions of different scales from feature maps of diffrent scales and explicitly separate predictions by aspect ratio.
2 SSD
2.1 Model
feed-forward convolutional network–>produces a fixed-size collection of bounding boxes and scores
NMS–>produce the final detections
SSD=base network+Auxiliary structure
auxilary detections with the following key features:
1. Multi-scale feature maps for detection. We add convolutional feature layers to the end of the truncated base network. These layers decrease in size progressively and allow predictions is different for each feature layer.
2. Convolutional predictors for detection
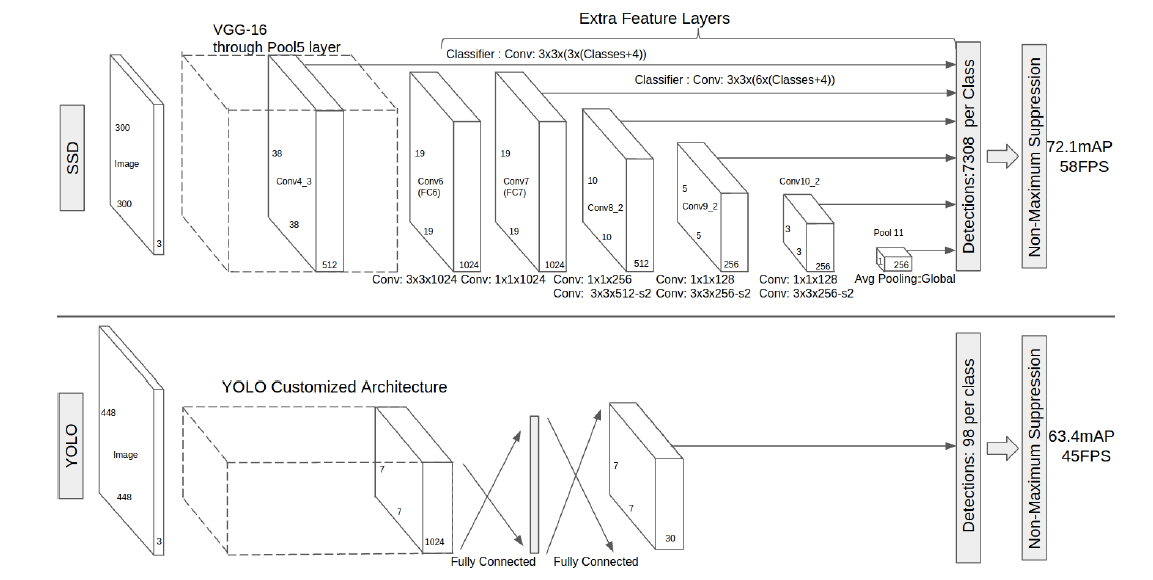
Each added feature layer can produce a fixed set of detection predictions using a set of convolutional filters.For a feature layers of size mxn with p channels, the basic element for prediting parameters of a potential detection is a 3x3xp small kernel that produces either a score for a category, or a shape offset relative to the default box coordinates.
3. Default boxes and aspect ratios.The default boxes similar to the achor boxes used in Faster R-CNN, Allowing different default box shapes in several feature maps lets us efficiently discretize the space of possible output box shapes.
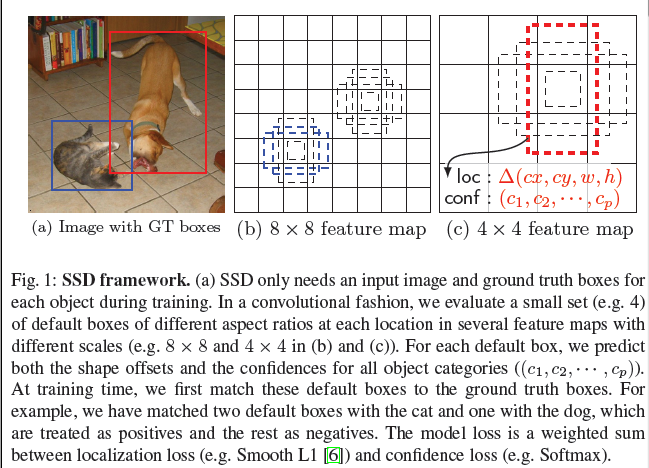
2.2 Training
The ground truth information needs to be assigned to specific outputs in the fixed set of detector outputs. Training also involves choosing the set of default boxes and scales for detection as well as hard negative mining and data augmentation strategies.
1. Matching strategy We begin by matching each ground truth box to the default box with the best jaccard overlap, then match default boxes to any ground truth with jaccard overlap higher than a threshold (0.5): it allows the network to predict high confidence for multiple overlapping default boxes rather than requiring it to pick only the one with maximum overlap. More tha one default box can match to the j ground truth box.
2. Training objective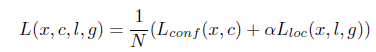
3. Choosing scales and aspect ratios for default boxes
redcue the size of the feature map–>reduce computation and memory cost but it also provide some degree of translation and scale invariance
utilizing feature maps from esveral different layers in a single netwaork for prediction –>different object scales, sharing parameters across all object scales, lower layers: details, top feature map:smooth details.
The scales of the default boxes for each feature map is computed as :
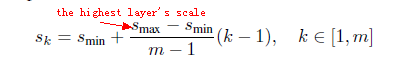
We compute the width
4. Hard negative mining
?
After the matching step ,most of the default boxes are negatives. We sort negative examples using the highest confidence for each default box and pick the top noes so the the ratio between the negatives and positives is at most 3:1(?????why is not 6:1).
5. Data augmeentation
- entire original input
- sample a patch so that the minimum jaccard overlap with the objects is 0.1 0.3 0.5 0.7 0.9
- Randomly sample a patch
3 Experimental Results
SSD is very sensitive to the bounding box size: worse performance on smaller objects

4 Related Work
- SSD is very similar to the region proposal network in Faster RCNN in that we also use a fixed set of boxes for prediction, similar to the achor boxes in the RPN, But instead of useing these to pool features and evaluate another classifier , we simultaneously produce a score for each object category in each box. Thus, our approach avids the complication of merging RPN with Fast RCNN and is easier to train,faster,and straightforward to intergrate in other tasks.
- If we only use one default box per location from the topmost feature map, our SSD would have similar architecture to OverFeat
- if we use the whole topmost feature map and add a fuul conneted layer for predictions instead of our convolutional predictiors, and donot explicitly consider multiple aspect ratios, we can approximately reproduce YOLO
Conclusions
相關推薦
論文筆記 | SSD: Single Shot MultiBox Detector
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg Wei Liu Abstract
論文筆記 SSD: Single Shot MultiBox Detector
話不多說開始總結,作為新一個快速高效的目標檢測演算法,SSD結合了Faster RCNN和YOLO 演算法。 本文主要提出的貢獻有以下幾點: (1)提出SSD演算法,比YOLO演算法更加迅速,同時和速度較慢的執行region proposal與pooli
[論文閱讀]SSD Single Shot Multibox Detector
SSD Single Shot Multibox Detector Code: https://github.com/balancap/SSD-Tensorflow SSD 是ECCV 2016的文章,文章主要提出了一種新的framework來完成object detec
[論文理解]SSD:Single Shot MultiBox Detector
導致 目標檢測 alt sam 實驗 detection 置疑 增強 不同 SSD:Single Shot MultiBox Detector Intro SSD是一套one-stage算法實現目標檢測的框架,速度很快,在當時速度超過了yolo,精度也可以達到two-sta
《SSD: Single Shot MultiBox Detector》論文筆記
1. 論文思想 SSD從網路中直接預測目標的類別與不同長寬比例的邊界框。在這篇論文中提出的方法(SSD)並沒有為邊界框假設重取樣畫素或是特徵,但是卻達到了使用這種方案檢測模型的精度。在VOC 2007的測試集上跑到了mAP74.3% 59 FPS(在後來改進資料增廣的方法,在VOC
SSD:Single Shot MultiBox Detector 論文筆記
資料增廣(Data augmentation)對於結果的提升非常明顯 Fast R-CNN 與 Faster R-CNN 使用原始影象,以及 0.5 的概率對原始影象進行水平翻轉(horizontal flip),進行訓練。如上面寫的,本文還使用了額外的 sampling 策略,YOLO 中還使用了 亮度
論文閱讀筆記:SSD: Single Shot MultiBox Detector
1 介紹當前目標檢測系統都是下列方法的變體:假定邊界框(hypothesizebounding boxes),對每個方框進行重取樣畫素或者特徵,應用一個高質量的分類器。這種流程在檢測基準(detectionbenchmarks)上盛行,因為選擇性搜尋在PASCAL VOC,COCO和ILSVRC檢測上的效果最
深度學習【50】物體檢測:SSD: Single Shot MultiBox Detector論文翻譯
SSD在眾多的物體檢測方法中算是比較重要的。之前學習過,但是沒過多久就忘了,因此決定將該論文翻譯一下,以加深印象。 Abstract 我們提出了用單個深度神經網路進行物體檢測的方法,稱為SSD。在每個特徵圖中的每個位置,SSD將bbox(bounding
SSD: Single Shot MultiBox Detector 深度學習筆記之SSD物體檢測模型
演算法概述 本文提出的SSD演算法是一種直接預測目標類別和bounding box的多目標檢測演算法。 與faster rcnn相比,該演算法沒有生成 proposal 的過程,這就極大提高了檢
【深度學習:目標檢測】RCNN學習筆記(10):SSD:Single Shot MultiBox Detector
之前一直想總結下SSD,奈何時間緣故一直沒有整理,在我的認知當中,SSD是對Faster RCNN RPN這一獨特步驟的延伸與整合。總而言之,在思考於RPN進行2-class分類的時候,能否借鑑YOLO並簡化faster rcnn在21分類同時整合faster rcnn中anchor boxes實現m
論文閱讀:SSD: Single Shot MultiBox Detector
Preface 有幾點更新: 1. 看到一篇 blog 對檢測做了一個總結、收集,強烈推薦: Object Detection 2. 還有,今天在微博上看到 VOC2012 的榜單又被重新整理了,微博原地址為:這裡,如下圖: 3. 目前 voc
SSD(Single Shot MultiBox Detector):create_list.sh io.cpp:187 Could not open or find file
今天在為SSD訓練自己的資料時執行caff/data/VOC0712/create_list.sh時報了好多這個錯誤: E0412 16:28:31.653440 5008 io.cpp:187] Could not open or find file
SSD(Single Shot MultiBox Detector)的solver引數 test_initialization的說明塈解決訓練時一直停在Iteration 0的問題
前陣子訓練過一次SSD模型,訓練後發現數據集有問題,修改了資料集後,今天準備再做一次SSD訓練時,如下執行訓練程式碼: python ./examples/ssd/ssd_pascal.py 到了開始迭代時,一直停在Iteration 0,進行不下去。
SSD: Single Shot MultiBox Detector翻譯(包括正式版和預印版)(對原文作部分理解性修改)
預印版表7 表7:Pascal VOC2007 test上的結果。SSD300是唯一的可以實現超過70%mAP的實時檢測方法。通過使用大輸入影象,在保持接近實時速度的同時,SSD512在精度上優於所有方法。 4、相關工作 目前有兩種已建立的用於影象中物件檢測的方法,一種基於
SSD( Single Shot MultiBox Detector)關鍵原始碼解析
SSD(SSD: Single Shot MultiBox Detector)是採用單個深度神經網路模型實現目標檢測和識別的方法。如圖0-1所示,該方法是綜合了Faster R-CNN的anchor box和YOLO單個神經網路檢測思路(YOLOv2也採用了類似的思路,詳見YOLO升級版:YOLOv2和YO
SSD:(Single Shot MultiBox Detector)
這兩天把SSD論文讀了一下,SSD也是一個端到端的目標檢測模型,SSD在檢測的準確率和速度上相對於YOLO有了很大的提高,並且在檢測小目標上也有不俗的效果。 特點 1. 使用多尺度特徵圖進行預測 大多數目標檢測演算法都是使用最後一層特徵圖進行目標位置和類
深度學習系列之SSD(Single Shot MultiBox Detector) 個人總結
Introduction SSD模型在保證精度的前提下,速度還特別快,可以做到real time。其中原因在於ssd消除了object proposal這個環節。Faster R-CNN是先利用RPN產生object proposal,然後對proposa
SSD: Single Shot MultiBox Detector in TensorFlow(翻譯)
一、環境配置 基本環境:Windows 10 + GTX950M 1、安裝Anaconda3() 注意:必須下載Anaconda3,因為Anaconda3對應Python3.x,而Windows下Tensorflow只支援Pyt
基於 SSD: Single Shot MultiBox Detector 的人體上下半身檢測
基於 SSD 的人體上下半身檢測 這裡主要是通過將訓練資料轉換成 Pascal VOC 資料集格式來實現 SSD 檢測人體上下半身. 由於沒有對人體上下半身進行標註的資料集, 這裡利用 MPII Human Pose Dataset 來將 Pose 資料轉
SSD: Single Shot MultiBox Detector 檢測單張圖片
前言 博主也算是剛開始研究SSD專案,之前寫了一篇SSD:Single Shot MultiBox Detector的安裝配置和執行,這次是簡單介紹下如何用SSD檢測單張圖片,其實過程也比較簡單,下面正式開始。 準備工作 當然,首先你要把SSD按照教程