
SSD: Single Shot MultiBox Detector翻譯(包括正式版和預印版)(對原文作部分理解性修改)
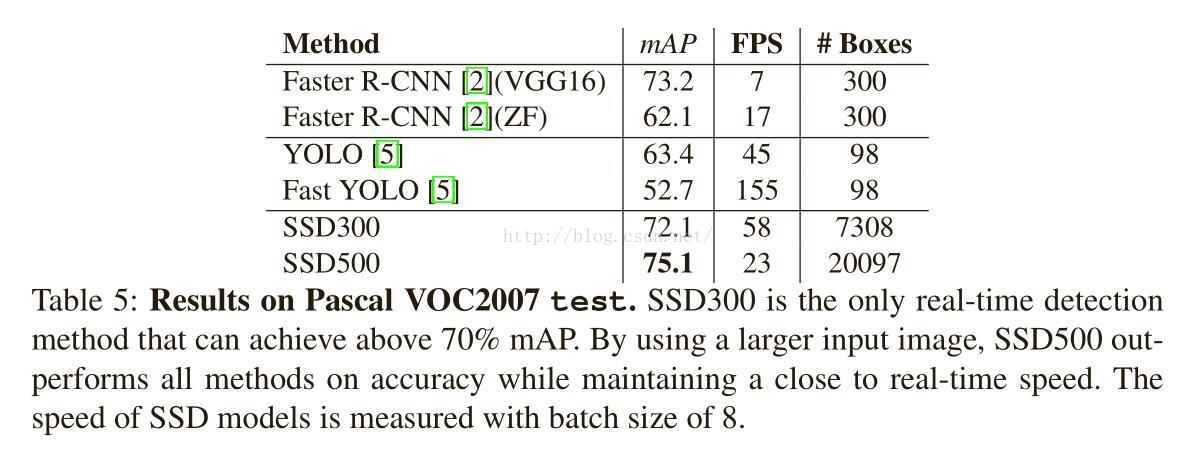
預印版表7

表7:Pascal VOC2007 test上的結果。SSD300是唯一的可以實現超過70%mAP的實時檢測方法。通過使用大輸入影象,在保持接近實時速度的同時,SSD512在精度上優於所有方法。
4、相關工作
目前有兩種已建立的用於影象中物件檢測的方法,一種基於滑動視窗,另一種基於region proposal(候選區域)分類。在卷積神經網路出現之前,用於檢測的兩種方法DeformablePart
Model(DPM)[22]和選擇性搜尋[1]效能接近(在卷積神經網路出現之前,檢測方面最先進的兩種方式——DeformablePart Model(DPM)[22]和選擇性搜尋[1]——有相似的效能
原始的R-CNN方法已經以各種方式進行了改進。第一組方法提高了後分類的質量和速度,因為它需要對成千上萬的影象作物進行分類,這是昂貴和耗時的。SPPnet[9]對原始的R-CNN方法大大提速。它引入了空間金字塔池化層,其對區域大小和比例尺度更加魯棒,並且允許分類層重新使用在若干影象解析度下生成的特徵圖特徵。Fast R-CNN[6]擴充套件了SPPnet,使得它可以通過最小化置信度和邊界框迴歸的損失來對所有層進行端到端微調,這在MultiBox[7]中首次引入用於學習物件。
第二組方法使用深層神經網路提高proposal(候選框)生成的質量。在最近的工作中,例如MultiBox[7,8],基於低水平影象特徵的選擇性搜尋region proposal被直接從單獨的深層神經網路生成的proposal所替代。這進一步提高了檢測精度,但是導致了一些複雜的設定,需要訓練兩個相互依賴的神經網路。Faster R-CNN[2]通過從region proposal網路(RPN)中學習的方案替換了選擇性搜尋proposal,並且引入了通過微調共享兩個網路的卷積層和預測層之間來交替整合RPN與Fast R-CNN的方法。用這種region proposa方法池化中等水平的特徵圖,最終分類步驟更簡便。我們的SSD與Faster R-CNN中的region proposal網路(RPN)非常相似,因為我們還
另一組方法與我們的方法直接相關,乾脆跳過proposal步驟,直接預測多個類別的邊界框和置信度。OverFeat[4]是滑動視窗方法的深度版本,在知道基礎物件類別的置信度之後直接從最頂層特徵圖的每個位置預測邊界框。YOLO [5]使用整個最高層特徵圖來預測多個類別和邊框(這些類別共享)的置信度。我們的SSD方法屬於此類別,因為我們沒有proposal步驟,但使用預設框。然而,我們的方法比現有方法更靈活,因為我們可以在不同尺度的多個特徵圖中的每個特徵位置上使用不同寬高比的預設框。如果頂層特徵圖每個位置只使用一個預設框,我們的SSD將具有與OverFeat[4]類似的架構;如果我們使用整個頂層特徵圖並且新增一個全連線層用於預測而不是我們的卷積預測器,並且沒有明確考慮多個寬高比,我們可以近似地再現YOLO[5]。
5、結論
本文介紹了SSD,一種用於多個類別的快速單次目標檢測器。我們的模型的一個關鍵特點是使用附屬於網路頂部的多特徵圖的多尺度卷積邊框輸出。這種表示允許我們有效地模擬可能的框形狀空間。我們實驗驗證,給定適當的訓練策略,更大量的仔細選擇的預設邊框得到了效能的提高。我們建立的SSD模型比現有的方法至少要多一個數量級的框預測取樣位置,比例和縱橫比[2,5,7][5,7]。我們證明,給定相同的VGG-16基礎架構,SSD在精度和速度方面勝過最先進的物件檢測器。我們的SSD500(SSD512)型號在PASCAL VOC和MS COCO的精度方面明顯優於最先進的Faster R-CNN [2],速度快了3倍。 我們的實時SSD300模型執行在58 FPS,這比當前的實時YOLO[5]更快,同時產生了明顯更優越的檢測精度。
除了它的獨立的效用,我們相信,我們的完整和相對簡單的SSD模型為使用目標檢測元件的大型系統提供了一個有用的組成塊。一個有希望的未來方向,是探索其作為使用迴圈神經網路的系統一部分,用以檢測和跟蹤視訊中物件。
6、致謝
這個專案是在谷歌開始的實習專案,並在UNC繼續。 我們要感謝亞歷克斯·託舍夫有用的討論,並感謝谷歌的Image Understanding和DistBelief團隊。 我們也感謝菲利普·阿米拉託和帕特里克·波爾森有益的意見。我們感謝NVIDIA提供K40 GPU並感謝NSF 1452851,1446631,1526367,133771的支援。
正式版參考文獻
1. Uijlings, J.R., van de Sande, K.E., Gevers, T.,Smeulders, A.W.: Selective search for object recognition. IJCV (2013)
2. Ren, S., He, K., Girshick, R., Sun, J.: FasterR-CNN: Towards real-time object detection with region proposal networks. In:NIPS. (2015)
3. He, K., Zhang, X., Ren, S., Sun, J.: Deepresidual learning for image recognition. In: CVPR.(2016)
4. Sermanet, P., Eigen, D., Zhang, X., Mathieu, M.,Fergus, R., LeCun, Y.: Overfeat: Integrated recognition, localization anddetection using convolutional networks. In: ICLR. (2014)
5. Redmon, J., Divvala, S., Girshick, R., Farhadi,A.: You only look once: Unified, real-time object detection. In: CVPR. (2016)
6. Girshick,R.: Fast R-CNN. In: ICCV. (2015)
7. Erhan, D.,Szegedy, C., Toshev, A., Anguelov, D.: Scalable object detection using deep neuralnetworks. In: CVPR. (2014)
8. Szegedy,C., Reed, S., Erhan, D., Anguelov, D.: Scalable, high-quality object detection.arXiv preprint arXiv:1412.1441 v3 (2015)
9. He, K.,Zhang, X., Ren, S., Sun, J.: Spatial pyramid pooling in deep convolutionalnetworks for visual recognition. In: ECCV. (2014)
10. Long, J., Shelhamer, E., Darrell, T.: Fullyconvolutional networks for semantic segmentation. In: CVPR. (2015)
11. Hariharan, B., Arbeláez, P., Girshick, R.,Malik, J.: Hypercolumns for object segmentation and fine-grained localization.In: CVPR. (2015)
12. Liu, W., Rabinovich, A., Berg, A.C.: ParseNet:Looking wider to see better. In: ILCR. (2016)
13. Zhou, B., Khosla, A., Lapedriza, A., Oliva, A.,Torralba, A.: Object detectors emerge in deep scene cnns. In: ICLR. (2015)
14. Simonyan,K.,Zisserman,A.:Verydeepconvolutionalnetworksforlarge-scaleimagerecog-nition. In: NIPS. (2015)
15. Russakovsky, O., Deng, J., Su, H., Krause, J.,Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg,A.C., Li, F.F.: Imagenet large scale visual recognition challenge. IJCV (2015)
16. Chen, L.C., Papandreou, G., Kokkinos, I.,Murphy, K., Yuille, A.L.: Semantic image segmentation with deep convolutionalnets and fully connected crfs. In: ICLR. (2015)
17. Jia, Y., Shelhamer, E., Donahue, J., Karayev,S., Long, J., Girshick, R., Guadarrama, S., Darrell, T.: Caffe: Convolutionalarchitecture for fast feature embedding. In: MM, ACM (2014)
18. Glorot, X., Bengio, Y.: Understanding thedifficulty of training deep feedforward neural networks. In: AISTATS. (2010)
19. Hoiem, D., Chodpathumwan, Y., Dai, Q.:Diagnosing error in object detectors. In: ECCV 2012. (2012)
20. Girshick, R., Donahue, J., Darrell, T., Malik,J.: Rich feature hierarchies for accurate object detection and semanticsegmentation. In: CVPR. (2014)
21. Bell, S., Zitnick, C.L., Bala, K., Girshick, R.:Inside-outside net: Detecting objects in context with skip pooling andrecurrent neural networks. In: CVPR. (2016)
22. Felzenszwalb, P., McAllester, D., Ramanan, D.: Adiscriminatively trained, multiscale, deformable part model. In: CVPR. (2008)
預印版參考文獻
1. Uijlings, J.R., van de Sande, K.E., Gevers, T., Smeulders, A.W.: Selective search for object recognition. IJCV (2013)
2. Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: Towards real-time object detection with region proposal networks. In: NIPS. (2015)
3. He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR. (2016)
4. Sermanet, P., Eigen, D., Zhang, X., Mathieu, M., Fergus, R., LeCun, Y.: Overfeat: Integrated recognition, localization and detection using convolutional networks. In: ICLR. (2014)
5. Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object detection. In: CVPR. (2016)
6. Girshick, R.: Fast R-CNN. In: ICCV. (2015)
7. Erhan, D., Szegedy, C., Toshev, A., Anguelov, D.: Scalable object detection using deep neural networks. In: CVPR. (2014)
8. Szegedy, C., Reed, S., Erhan, D., Anguelov, D.: Scalable, high-quality object detection. arXiv preprint arXiv:1412.1441 v3 (2015)
9. He, K., Zhang, X., Ren, S., Sun, J.: Spatial pyramid pooling in deep convolutional networks for visual recognition. In: ECCV. (2014)
10. Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: CVPR. (2015)
11. Hariharan, B., Arbel´aez, P., Girshick, R., Malik, J.: Hypercolumns for object segmentation and fine-grained localization. In: CVPR. (2015)
12. Liu,W., Rabinovich, A., Berg, A.C.: ParseNet: Looking wider to see better. In: ILCR. (2016)
13. Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., Torralba, A.: Object detectors emerge in deep scene cnns. In: ICLR. (2015)
14. Howard, A.G.: Some improvements on deep convolutional neural network based image classification. arXiv preprint arXiv:1312.5402 (2013)
15. Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: NIPS. (2015)
16. Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A.C., Fei-Fei, L.: Imagenet large scale visual recognition challenge. IJCV (2015)
17. Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Semantic image segmentation with deep convolutional nets and fully connected crfs. In: ICLR. (2015)
18. Holschneider, M., Kronland-Martinet, R., Morlet, J., Tchamitchian, P.: A real-time algorithm for signal analysis with the help of the wavelet transform. In: Wavelets. Springer (1990) 286–297
19. Jia, Y., Shelhamer, E., Donahue, J., Karayev, S., Long, J., Girshick, R., Guadarrama, S., Darrell, T.: Caffe: Convolutional architecture for fast feature embedding. In: MM. (2014)
20. Glorot, X., Bengio, Y.: Understanding the difficulty of training deep feedforward neural networks. In: AISTATS. (2010)
21. Hoiem, D., Chodpathumwan, Y., Dai, Q.: Diagnosing error in object detectors. In: ECCV 2012. (2012)
22. Girshick, R., Donahue, J., Darrell, T., Malik, J.: Rich feature hierarchies for accurate object detection and semantic segmentation. In: CVPR. (2014)
23. Zhang, L., Lin, L., Liang, X., He, K.: Is faster r-cnn doing well for pedestrian detection. In: ECCV. (2016)
24. Bell, S., Zitnick, C.L., Bala, K., Girshick, R.: Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In: CVPR. (2016)
25. COCO: Common Objects in Context. http://mscoco.org/dataset/#detections-leaderboard (2016) [Online; accessed 25-July-2016].
26. Dollar, P.: Coco api. https://github.com/pdollar/coco (2016)
27. Felzenszwalb, P., McAllester, D., Ramanan, D.: A discriminatively trained, multiscale, deformable part model. In: CVPR. (2008)