
每個人都能徒手寫遞迴神經網路–手把手教你寫一個RNN
總結: 我總是從迷你程式中學到很多。這個教程用python寫了一個很簡單迷你程式講解遞迴神經網路。
遞迴神經網路即RNN和一般神經網路有什麼不同?出門左轉我們一篇部落格已經講過了傳統的神經網路不能夠基於前面的已分類場景來推斷接下來的場景分類,但是RNN確有一定記憶功能。廢話少說,上圖:
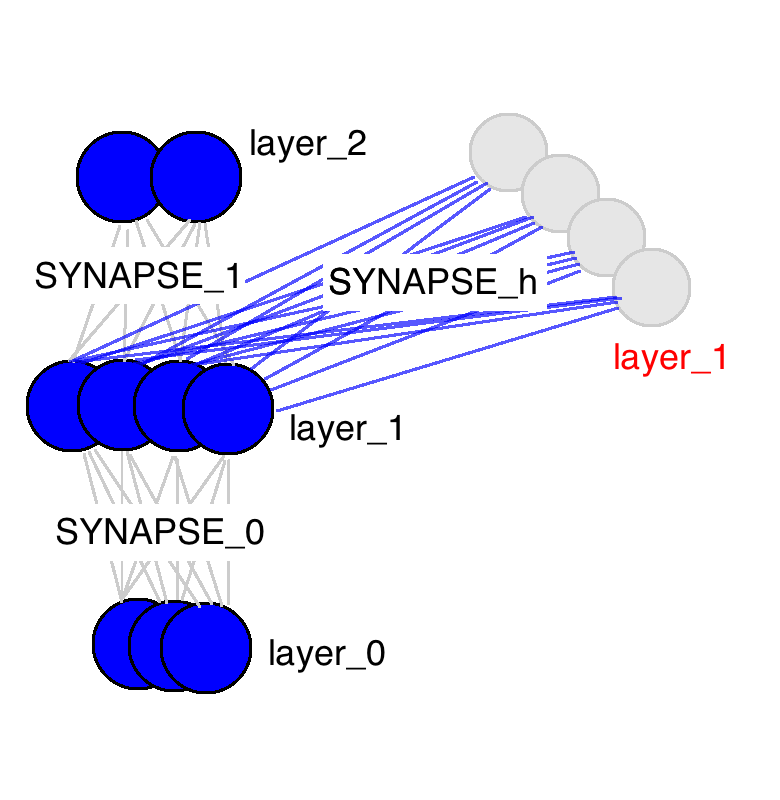
layer_0就是輸入層,layer_1就是隱層,layer_2就是輸出層。什麼叫隱層呢?顧名思義,隱層就是隱藏層,訓練時對外是透明的,畢竟主要關心的還是輸出層的判斷結果。這裡RNN和一般神經網路不一樣的是多了一個隱層,有沒有發現layer_1有兩個呢?是的,這一個紅色的多出來的類似快取的layer_1就是RNN的獨特之處。SYNAPSE_0, SYNAPSE_1, SYNAPSE_h分別是輸入層,輸出層和隱層的權重值矩陣,模型訓練的也主要是這些矩陣的權重值。
所以,RNN的關鍵就是:
每次的隱層值不再只是layer_0
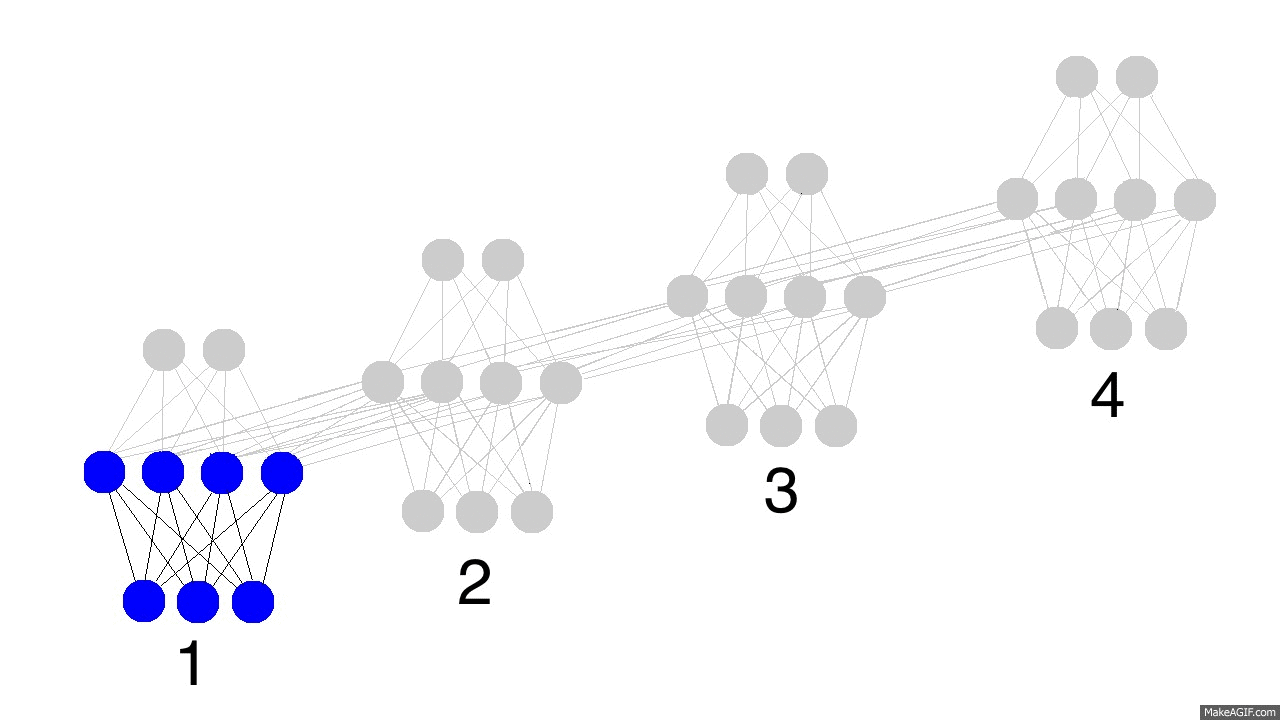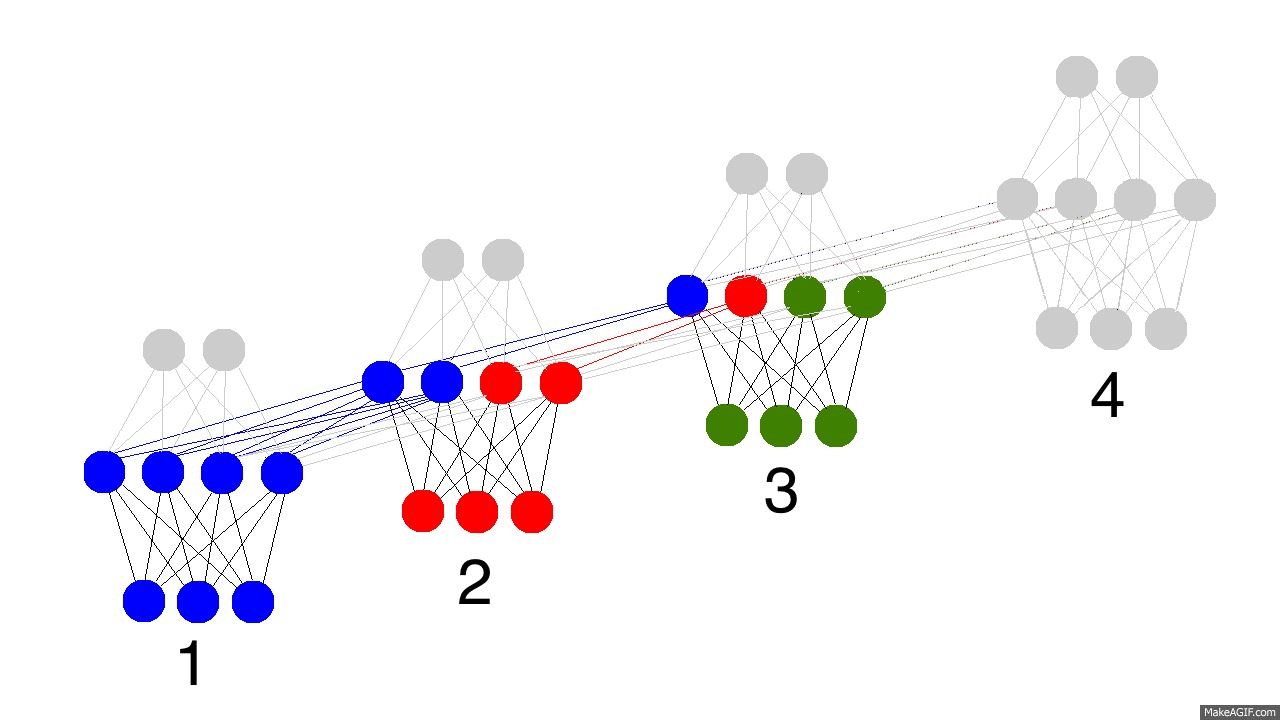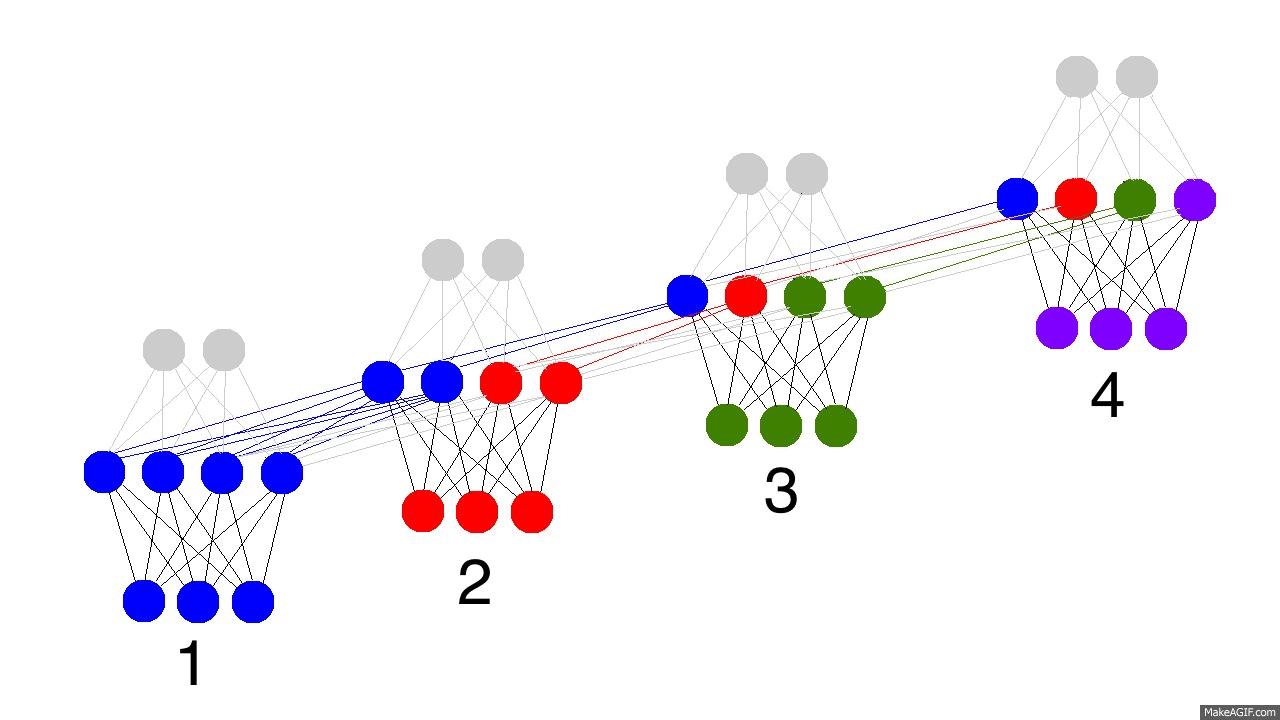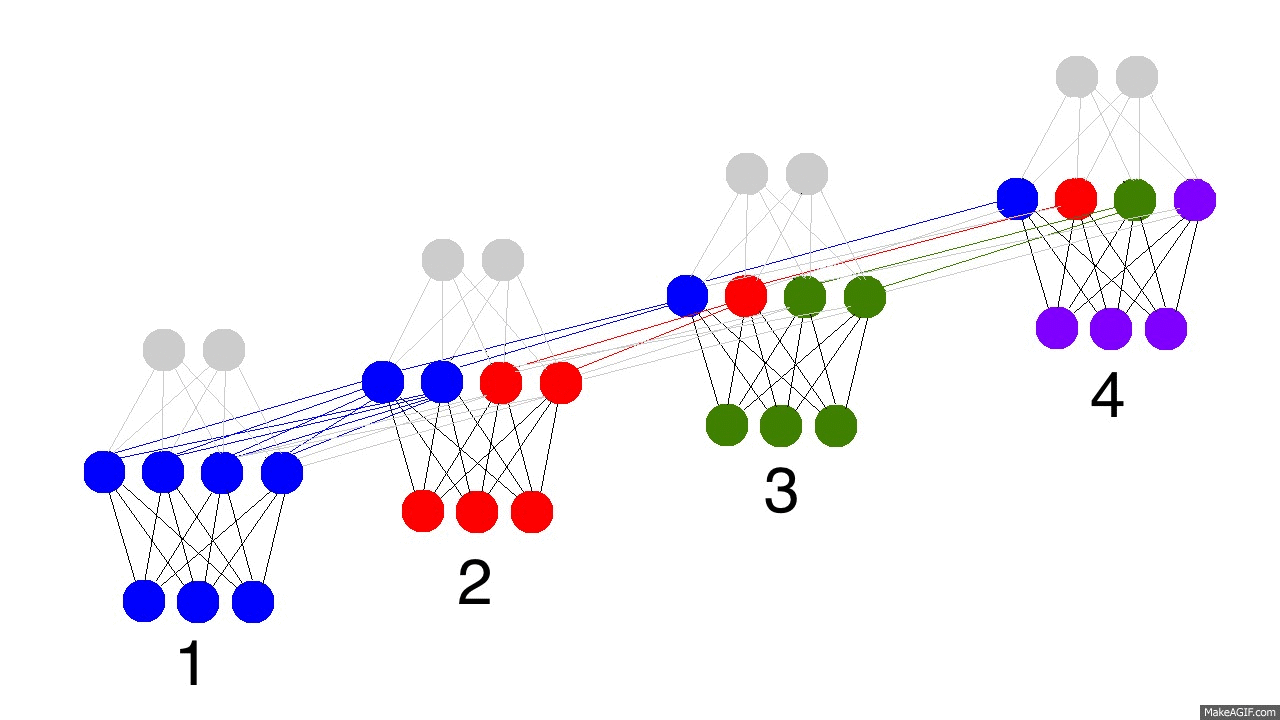
上圖展示了訓練隱層的四個時間戳過程,值得注意的是,每次隱層都會保留之前輸入資訊,並且和此次輸入層資訊疊加成新的資訊,再和下一次輸入疊加。這就導致最後隱層包含了各種顏色的資訊。而且,隱層會“遺忘”那些不重要的資訊,如時間戳3把紅色和紫色資訊較多地“遺忘”。
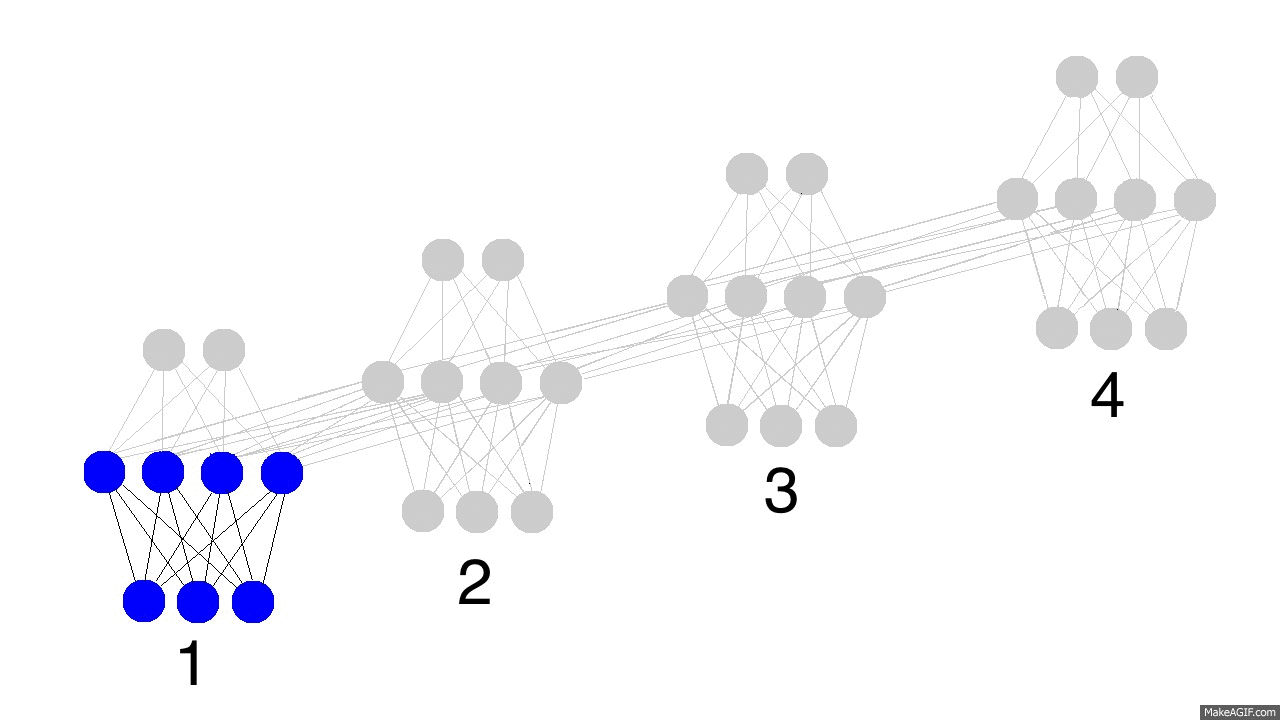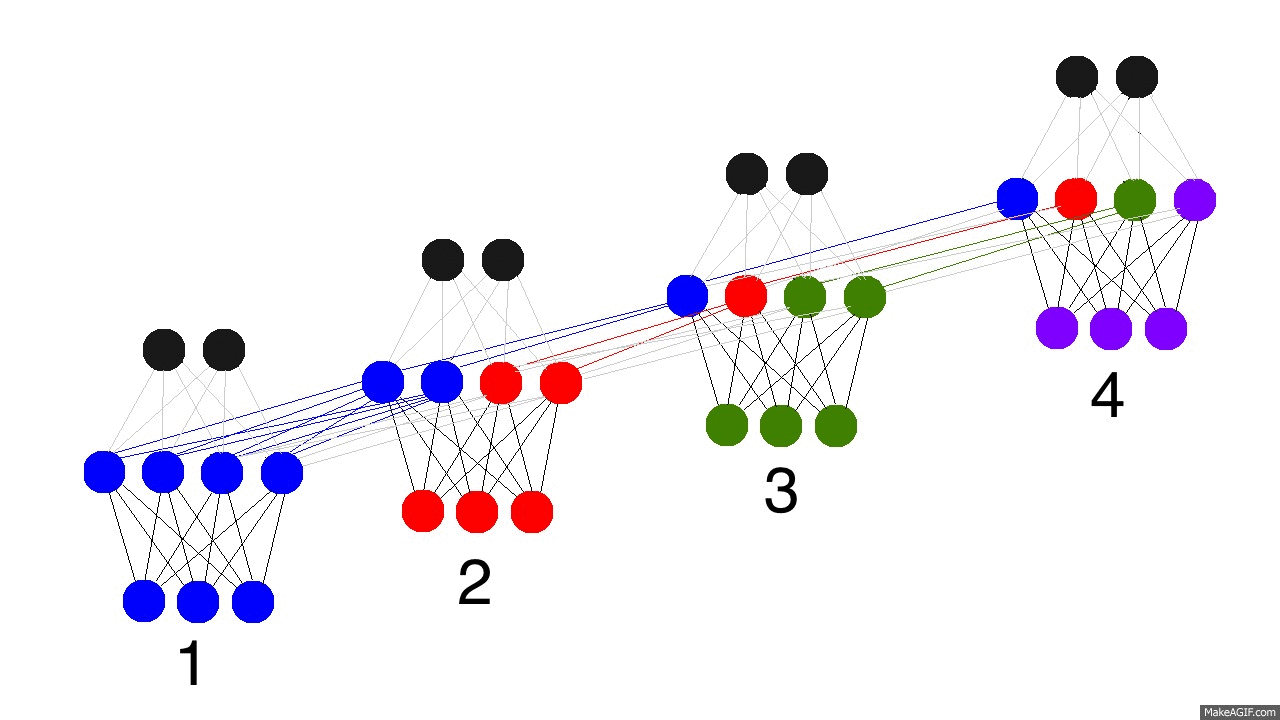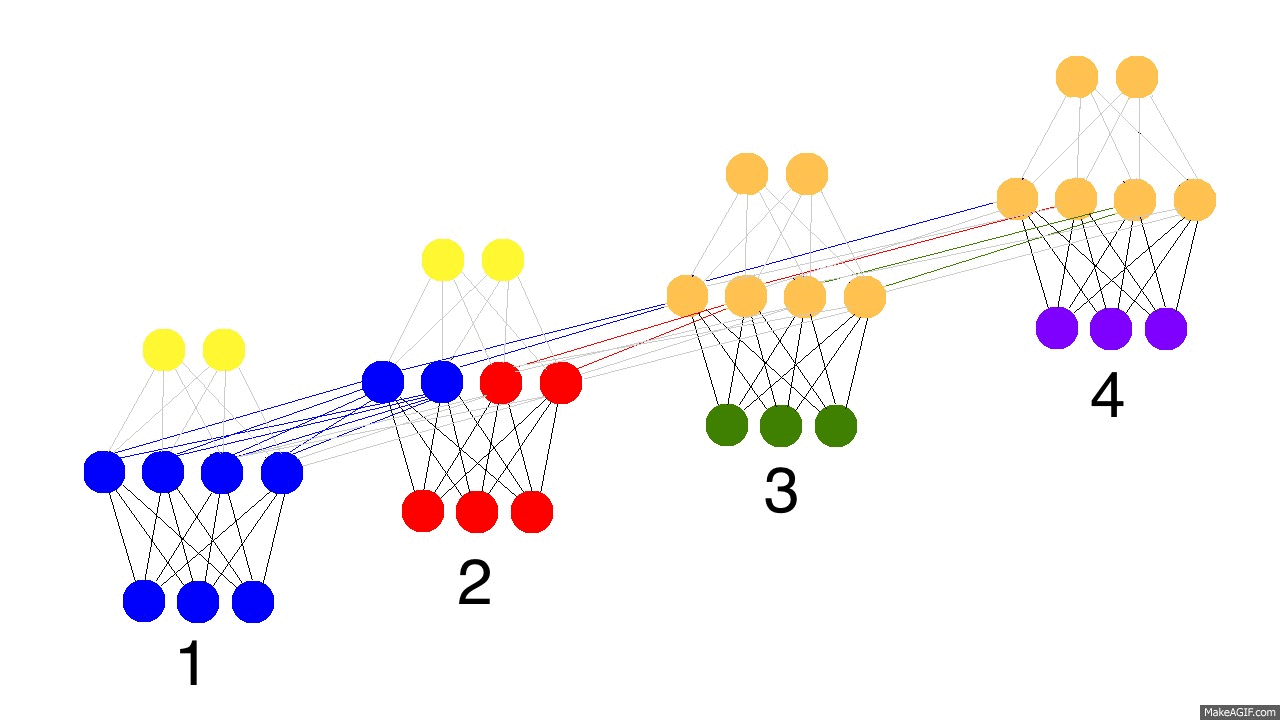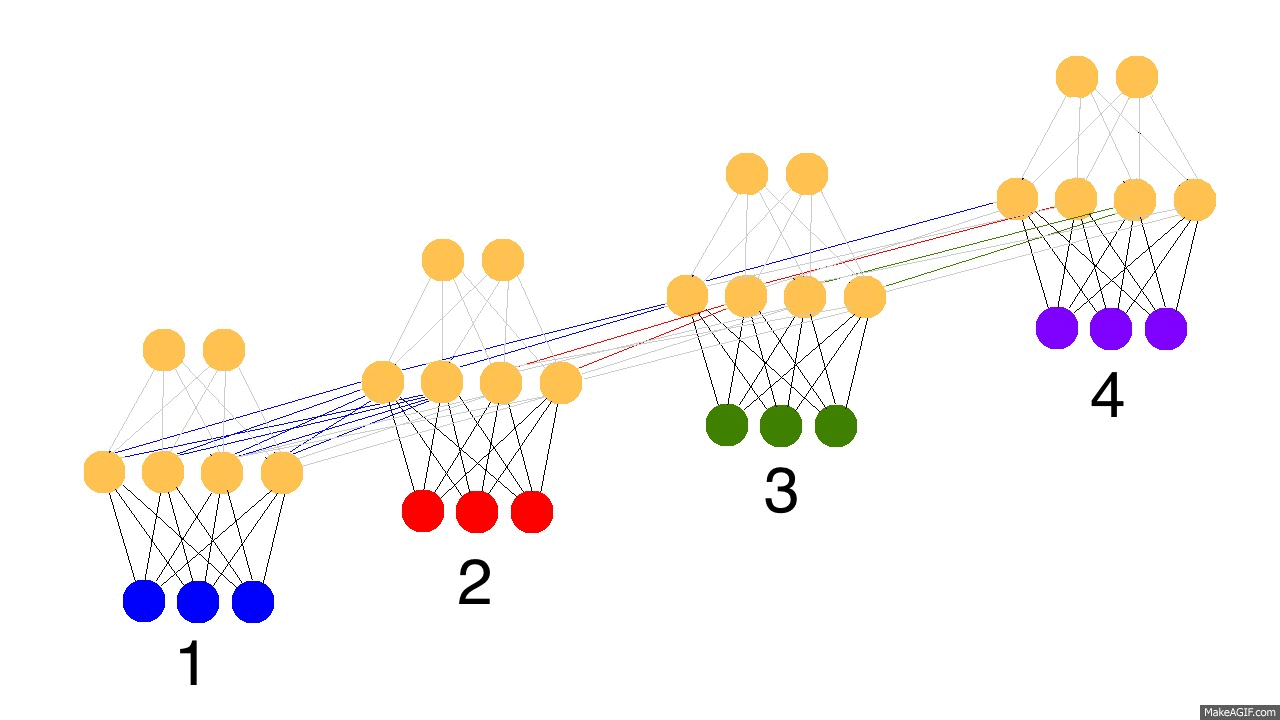
上圖是反向傳播的修正過程,黑色是預測值,亮黃色是錯誤,橘黃色是求導值,通過求導值對各個時間戳上的權衡矩陣做修正。
具體怎麼實現呢?廢話少說, 上程式碼:
- import copy, numpy as np
- np.random.seed(0)
- # compute sigmoid nonlinearity
- def sigmoid(x):
- output = 1/(1+np.exp(-x))
- return output
- # convert output of sigmoid function to its derivative
- def sigmoid_output_to_derivative(output):
-
return
output*(1-output)
- # training dataset generation
- int2binary = {}
- binary_dim = 8
- largest_number = pow(2,binary_dim)
- binary = np.unpackbits(
- np.array([range(largest_number)],dtype=np.uint8).T,axis=1)
- for i inrange(largest_number):
- int2binary[i] = binary[i]
- # input variables
- alpha = 0.1
- input_dim = 2
- hidden_dim = 16
- output_dim = 1
- # initialize neural network weights
- synapse_0 = 2*np.random.random((input_dim,hidden_dim)) - 1
- synapse_1 = 2*np.random.random((hidden_dim,output_dim)) - 1
- synapse_h = 2*np.random.random((hidden_dim,hidden_dim)) - 1
- synapse_0_update = np.zeros_like(synapse_0)
- synapse_1_update = np.zeros_like(synapse_1)
- synapse_h_update = np.zeros_like(synapse_h)
- # training logic
- for j inrange(10000):
- # generate a simple addition problem (a + b = c)
-
a_int = np.random.randint(largest_number/
相關推薦
每個人都能徒手寫遞迴神經網路–手把手教你寫一個RNN
總結: 我總是從迷你程式中學到很多。這個教程用python寫了一個很簡單迷你程式講解遞迴神經網路。 遞迴神經網路即RNN和一般神經網路有什麼不同?出門左轉我們一篇部落格已經講過了傳統的神經網路不能夠基於前面的已分類場景來推斷接下來的場景分類,但是RNN確有一定記
Facebook開源TorchCraft,讓每個人都能編寫星際爭霸AI玩家
專案地址:https://github.com/TorchCraft/TorchCraft 此次開源的 TorchCraft 基於 Synnaeve 等人的論文TorchCraft: a Library for Machine Learning Research on
這是一篇每個人都能讀懂的最小生成樹文章(Kruskal)
本文始發於個人公眾號:**TechFlow**,原創不易,求個關注 今天是演算法和資料結構專題的第19篇文章,我們一起來看看最小生成樹。 我們先不講演算法的原理,也不講一些七七八八的概念,因為對於初學者來說,看到這些術語和概念往往會很頭疼。頭疼也是正常的,因為無端突然出現這麼多資訊,都不知道它們是怎麼來
要理解遞迴就要先理解遞迴:手把手教你寫遞迴
問:何為遞迴函式? 說人話:**自己呼叫自己的函式就叫遞迴函式**。 ## 遞迴函式寫法 實現一個遞迴函式,我將其概括為是一個“推卸責任”的過程,分為3個步驟: 1. **列出方法簽名**:明確該函式/方法的輸入輸出,由此寫出它的方法簽名(method’s signature),方法簽名包
PyTorch--雙向遞迴神經網路(B-RNN)概念,原始碼分析
關於概念: BRNN連線兩個相反的隱藏層到同一個輸出.基於生成性深度學習,輸出層能夠同時的從前向和後向接收資訊.該架構是1997年被Schuster和Paliwal提出的.引入BRNNS是為了增加網路所用的輸入資訊量.例如,多層感知機(MLPS)和延時神經網路(TDNNS)在輸入資料的靈活性方面是非
手把手教你寫DI_2_小白徒手擼建構函式注入
小白徒手擼建構函式注入 在上一節:手把手教你寫DI_1_DI框架有什麼? 我們已經知道我們要擼哪些東西了 那麼我們開始動工吧,這裡呢,我們找小白同學來表演下 小白同學 :我們先定義一下我們的廣告招聘紙有什麼: public abstract class ServiceDefintion // 小白
遞迴神經網路(RNN)隨記
基本概念 想法:在之後的輸入要把之前的資訊利用起來。W3就相當於對中間資訊進行一個保留。 X和U組合成一個特徵圖,A表示一個記憶單元。 V矩陣相當於對St進行一個全連線的操作。最終的輸出需要通過softmax將向量轉化成概率的形式。RNN最適合做自然語言處理
Tensorflow學習筆記(第四天)—遞迴神經網路
一、首先下載來源於 Tomas Mikolov 網站上的 PTB 資料集 http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz 二、需要的程式碼: 這裡只簡單的放了一些程式碼
(轉載)深度學習基礎(7)——遞迴神經網路
原文地址:https://zybuluo.com/hanbingtao/note/626300 轉載在此的目的是自己做個筆記,日後好複習,如侵權請聯絡我!! 在前面的文章中,我們介紹了迴圈神經網路,它可以用來處理包含序列結構的資訊。然而,除此之外,資訊往往還存在著諸如樹結構、圖結構等更復雜的結構。對於
[譯]使用遞迴神經網路(LSTMs)對時序資料進行預測
原文地址:A Guide For Time Series Prediction Using Recurrent Neural Networks (LSTMs) 原文作者:Neelabh Pant 譯文出自:掘金翻譯計劃 本文永久連結:github.com/xitu/gold-m
NeuralTalk:一種基於Python+numpy使用語句描述影象的多模態遞迴神經網路的例程
NeuralTalk工程的流程如下: The pipeline for the project looks as follows: 輸入資料使用Amazon Mechanical Turk收集的影象和5組語句描述的資料集。 The input is a dataset of im
長短期記憶(LSTM)系列_2.1~2.3、用遞迴神經網路簡要介紹序列預測模型
前置課程 https://machinelearningmastery.com/sequence-prediction/ https://machinelearningmastery.com/gentle-introduction-long-short-term-memory-network
遞迴神經網路RNN網路 LSTM
前言: 根據我本人學習 TensorFlow 實現 LSTM 的經歷,發現網上雖然也有不少教程,其中很多都是根據官方給出的例子,用多層 LSTM 來實現 PTBModel 語言模型,比如: tensorflow筆記:多層LSTM程式碼分析 但是感覺這些例子還是
遞迴神經網路
遞迴神經網路 序列。根據您的背景,您可能想知道:什麼使Recurrent Networks如此特別?Vanilla神經網路(以及卷積網路)的一個明顯侷限是它們的API太受約束:它們接受固定大小的向量作為輸入(例如影象)併產生固定大小的向量作為輸出(例如不同類別的概率) )。不僅如此:這些模型使用固定數量的計
手把手教你寫DI_3_小白徒手支援 `Singleton` 和 `Scoped` 生命週期
手把手教你寫DI_3_小白徒手支援 Singleton 和 Scoped 生命週期 渾身繃帶的小白同學:我們繼續開展我們的工作,大家都知道 Singleton是什麼,就是全域性只有一個唄,我們就先從它開始,這個多簡單,我們找個字典放這些物件就ok啦 public class ServiceProvider
使用遞迴神經網路識別垃圾簡訊
1.測試資料準備 首先匯入本地準備的spam檔案 import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from sklearn.model_selec
手把手教你做一個 C 語言編譯器(4):遞迴下降
本章我們將講解遞迴下降的方法,並用它完成一個基本的四則運算的語法分析器。 本系列: 什麼是遞迴下降 傳統上,編寫語法分析器有兩種方法,一種是自頂向下,一種是自底自上。自頂向下是從起始非終結符開始,不斷地對非終結符進行分解,直到匹配輸入的終結符;自底向上是不斷地將終
cs224d 作業 problem set3 (一) 實現Recursive Nerual Net Work 遞迴神經網路
''' Created on 2017年10月5日 @author: weizhen ''' # 一個簡單的遞迴神經網路的實現,有著一個ReLU層和一個softmax層 # TODO : 必須要更新前向和後向傳遞函式 # 你可以通過執行 python rnn.py 方法來執行一個梯度檢驗 # 插入pdb.
系統學習深度學習(五) --遞迴神經網路原理,實現及應用
但是大神們說,標準的RNN在實際使用中效果不是很好,真正起到作用的是LSTM,因此RNN只做簡單學習,不上原始碼(轉載了兩篇,第一個是簡單推導,第二個是應用介紹)。 下面是簡單推導,轉自:http://blog.csdn.net/aws3217150/article/details/5076
【深度學習】6:RNN遞迴神經網路原理、與MNIST資料集實現數字識別
前言:自己學習研究完CNN卷積神經網路後,很久的一段時間因為要完成自己的畢業設計就把更新部落格給耽擱了。瞎忙了這麼久,還是要把之前留的補上來。因為“種一棵樹最好的時間是在十年前,其次就是現在!” –—-—-—-—-—-—-—-—-—-—-—-—–—-—-—-—