
2017年AI技術盤點:關鍵進展與趨勢
作者 | 張俊林,新浪微博AI實驗室資深演算法專家
責編 | 何永燦
人工智慧最近三年發展如火如荼,學術界、工業界、投資界各方一起發力,硬體、演算法與資料共同發展,不僅僅是大型網際網路公司,包括大量創業公司以及傳統行業的公司都開始涉足人工智慧。2017年人工智慧行業延續了2016年蓬勃發展的勢頭,那麼在過去的一年裡AI行業從技術發展角度有哪些重要進展?未來又有哪些發展趨勢?本文從大家比較關注的若干領域作為代表,來歸納AI領域一些方向的重要技術進展。
從AlphaGo Zero到Alpha Zero:邁向通用人工智慧的關鍵一步
DeepMind攜深度增強學習利器總是能夠給人帶來震撼性的技術創新,2016年橫空出世的AlphaGo徹底粉碎了普遍存在的“圍棋領域機器無法戰敗人類最強手”的執念,但是畢竟李世石還是贏了一局,不少人對於人類翻盤大逆轉還是抱有希望,緊接著Master通過60連勝諸多頂尖圍棋高手徹底澆滅了這種期待。2017年AlphaGo Zero作為AlphaGo二代做了進一步的技術升級,把AlphaGo一代虐得體無完膚,這時候人類已經沒有資格上場對局了。2017年底AlphaGo的棋類遊戲通用版本Alpha Zero問世,不僅僅圍棋,對於國際象棋、日本將棋等其他棋類遊戲,Alpha Zero也以壓倒性優勢戰勝包括AlphaGo Zero在內的目前最強的AI程式。
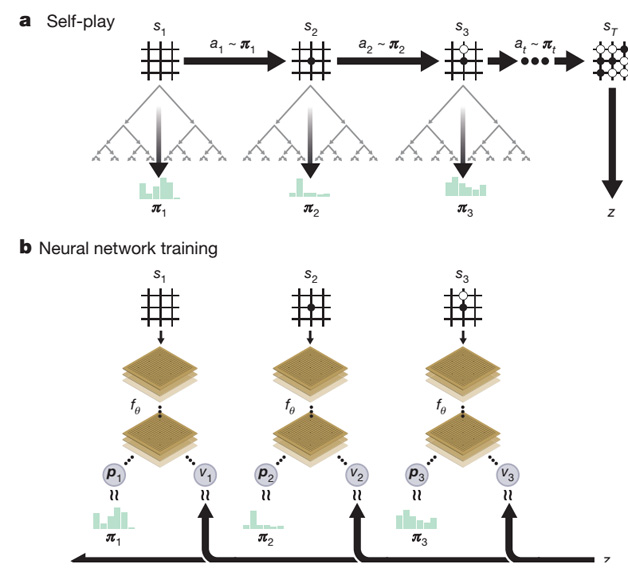
AlphaGo Zero從技術手段上和AlphaGo相比並未有本質上的改進,主體仍然是MCST蒙特卡洛搜尋樹加神經網路的結構以及深度增強學習訓練方法,但是技術實現上簡單優雅很多(參考圖1)。主要的改動包含兩處:一處是將AlphaGo的兩個預測網路(策略網路和價值網路)合併成一個網路,但是同時產生兩類所需的輸出;第二處是網路結構從CNN結構升級為ResNet。雖說如此,AlphaGo Zero給人帶來的觸動和啟發絲毫不比AlphaGo少,主要原因是AlphaGo Zero完全放棄了從人類棋局來進行下棋經驗的學習,直接從一張白紙開始通過自我對弈的方式進行學習,並僅僅通過三天的自我學習便獲得了遠超人類千年積累的圍棋經驗。
這引發了一個之前一般人很期待但是同時又認為很難完成的問題:機器能夠不依賴有監督方式的訓練資料或者極少的訓練資料自我進化與學習嗎?如果真的能夠做到這一點,那麼是否意味著機器會快速進化並淘汰人類?第二個問題甚至會引起部分人的恐慌。但是其實這個問題本身問的就有問題,因為它做了一個錯誤的假設:AlphaGo Zero是不需要訓練資料的。首先,AlphaGo Zero確實做到了通過自我對弈的方式進行學習,但是仍然需要大量訓練資料,無非這些訓練資料是通過自我對弈來產生的。而且更根本的一點是應該意識到:對於AlphaGo Zero來說,其本質其實還是MCST蒙特卡洛樹搜尋。圍棋之所以看著難度大難以克服,主要是搜尋空間實在太大,單純靠暴力搜尋完全不可行。如果我們假設現在有個機器無限強大,能夠快速遍歷所有搜尋空間,那麼其實單純使用MCST樹搜尋,不依靠機器學習,機器也能達到完美的博弈狀態。AlphaGo Zero通過自我對弈以及深度增強學習主要達到了能夠更好地評估棋盤狀態和落子質量,優先選擇走那些贏面大的博弈路徑,這樣能夠捨棄大量的劣質路徑,從而極大減少了需要搜尋的空間,自我進化主要體現在評估棋面狀態越來越準。而之所以能夠通過自我對弈產生大量訓練資料,是因為下棋是個規則定義很清晰的任務,到了一定狀態就能夠贏或者輸,無非這種最終的贏或者輸來得晚一些,不是每一步落子就能看到的,現實生活中的任務是很難達到這一點的,這是為何很多工仍然需要人類提供大量訓練資料的原因。如果從這個角度考慮,就不會錯誤地產生以上的疑慮。
Alpha Zero相對AlphaGo Zero則更進一步,將只能讓機器下圍棋拓展到能夠進行規則定義清晰的更多棋類問題,使得這種技術往通用人工智慧的路上邁出了重要一步。其技術手段和AlphaGo Zero基本是相同的,只是去除掉所有跟圍棋有關的一些處理措施和技術手段,只告訴機器遊戲規則是什麼,然後使用MCST樹搜尋+深度神經網路並結合深度增強學習自我對弈的統一技術方案和訓練手段解決一切棋類問題。
從AlphaGo的一步步進化策略可以看出,DeepMind正在考慮這套擴充套件技術方案的通用性,使得它能夠使用一套技術解決更多問題,尤其是那些非遊戲類的真實生活中有現實價值的問題。同時,AlphaGo系列技術也向機器學習從業人員展示了深度增強學習的強大威力,並進一步推動了相關的技術進步,目前也可以看到深度增強學習在更多領域應用的例項。
GAN:前景廣闊,理論與應用極速發展中
GAN,全稱為Generative Adversarial Nets,直譯為“生成式對抗網路”。GAN作為生成模型的代表,自2014年被Ian Goodfellow提出後引起了業界的廣泛關注並不斷湧現出新的改進模型,深度學習泰斗之一的Yann LeCun高度評價GAN是機器學習界近十年來最有意思的想法。
Ian Goodfellow提出的最初的GAN儘管從理論上證明了生成器和判別器在多輪對抗學習後能夠達到均衡態,使得生成器可以產生理想的影象結果。但是實際上,GAN始終存在訓練難、穩定性差以及模型崩塌(Model Collapse)等問題。產生這種不匹配的根本原因其實還是對GAN背後產生作用的理論機制沒有探索清楚。
過去的一年在如何增加GAN訓練的穩定性及解決模型崩塌方面有了可喜的進展。GAN本質上是通過生成器和判別器進行對抗訓練,逼迫生成器在不知曉某個資料集合真實分佈Pdata的情形下,通過不斷調整生成資料的分佈Pθ去擬合逼近這個真實資料分佈Pdata,所以計算當前訓練過程中兩個分佈Pdata和Pθ的距離度量標準就很關鍵。Wasserstein GAN的作者敏銳地指出了:原始GAN在計算兩個分佈的距離時採用的是Jensen-Shannon Divergence(JSD),它本質上是KL Divergence(KLD)的一個變種。JSD或者KLD存在一個問題:當兩個分佈交集很少時或者在低維流形空間下,判別器很容易找到一個判別面將生成的資料和真實資料區分開,這樣判別器就不能提供有效的梯度資訊並反向傳導給生成器,生成器就很難訓練下去,因為缺乏來自判別器指導的優化目標。Wasserstein GAN提出了使用Earth-Mover距離來代替JSD標準,這很大程度上改進了GAN的訓練穩定性。後續的Fisher GAN等模型又對Wasserstein GAN進行了進一步的改進,這些技術陸續改善了GAN的訓練穩定性。模型崩塌也是嚴重製約GAN效果的問題,它指的是生成器在訓練好之後,只能產生固定幾個模式的圖片,而真實的資料分佈空間其實是很大的,但是模型崩塌到這個空間的若干個點上。最近一年針對這個問題也提出了比如標籤平滑、Mini-Batch判別器等啟發式方法來解決生成器模型崩塌的問題並取得了一定效果。
儘管在理論層面,針對GAN存在的問題,業界在2017年提出了不少改進方法,對於GAN的內在工作機制也有了更深入的瞭解,但是很明顯目前仍然沒有理解其本質工作機制,這塊還需要未來更有洞察力的工作來增進我們對GAN的理解。

GAN具備非常廣泛的應用場景,比如影象風格轉換、超解析度影象構建、自動黑白圖片上色、圖片實體屬性編輯(例如自動給人像增加鬍子、切換頭髮顏色等屬性變換),不同領域圖片之間的轉換(例如同一個場景春天的圖片自動轉換為秋天的圖片,或者白天景色自動轉換為夜間的景色),甚至是影象實體的動態替換,比如把一幅圖片或者視訊中出現的貓換成狗(參考圖2)。
在推動GAN應用方面,2017年有兩項技術是非常值得關注的。其中一個是CycleGAN,其本質是利用對偶學習並結合GAN機制來優化生成圖片的效果的,採取類似思想的包括DualGAN以及DiscoGAN等,包括後續的很多改進模型例如StarGAN等。CycleGAN的重要性主要在於使得GAN系列的模型不再侷限於監督學習,它引入了無監督學習的方式,只要準備兩個不同領域的圖片集合即可,不需要訓練模型所需的兩個領域的圖片一一對應,這樣極大擴充套件了它的使用範圍並降低了應用的普及難度。另外一項值得關注的技術是英偉達採取“漸進式生成”技術路線的GAN方案,這項方案的引人之處在於使得計算機可以生成1024*1024大小的高清圖片,它是目前無論影象清晰度還是圖片生成質量都達到最好效果的技術,其生成的明星圖片幾乎可以達到以假亂真的效果(參考圖3)。英偉達這項由粗到細,首先生成影象的模糊輪廓,再逐步新增細節的思想其實並非特別新穎的思路,在之前的StackGAN等很多方案都採用了類似思想,它的獨特之處在於這種由粗到細的網路結構是動態生成的而非事先固定的靜態網路,更關鍵的是產生的圖片效果特別好。

總而言之,以GAN為代表的生成模型在2017年無論是理論基礎還是應用實踐都產生了很大的技術進展,可以預計的是它會以越來越快的速度獲得研發人員的推動,並在不遠的將來在各個需要創造性的領域獲得廣泛應用。
Capsule:有望取代CNN的新結構
Capsule今年才以論文的形式被人稱“深度學習教父”的Hinton老先生髮表出來,而且論文一出來就成為研究人員關注的焦點,但是其實這個思想Hinton已經深入思考了很久並且之前在各種場合宣傳過這種思路。Hinton一直對CNN中的Pooling操作意見很大,他曾經吐槽說:“CNN中使用的Pooling操作是個大錯誤,事實上它在實際使用中效果還不錯,但這其實更是一場災難”。那麼,MaxPooling有什麼問題值得Hinton對此深惡痛絕呢?參照圖4所示的例子可以看出其原因。
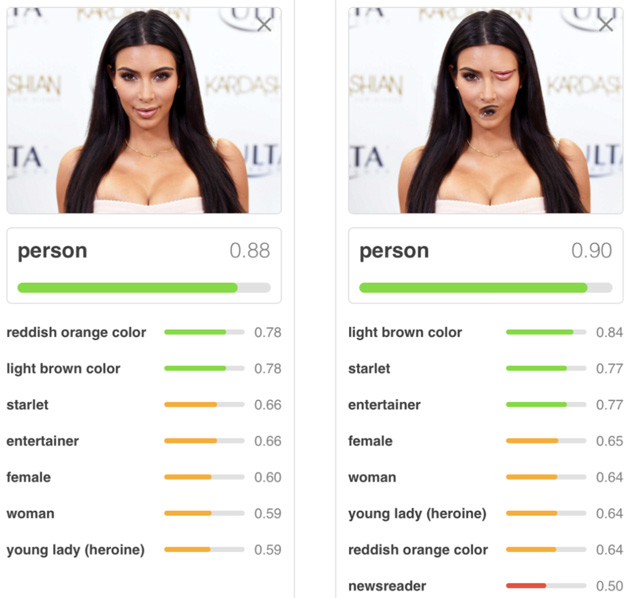
在上面這張圖中,給出兩張人像照片,通過CNN給出照片所屬類別及其對應的概率。第一張照片是一張正常的人臉照片,CNN能夠正確識別出是“人類”的類別並給出歸屬概率值0.88。第二張圖片把人臉中的嘴巴和眼睛對調了下位置,對於人來說不會認為這是一張正常人的臉,但是CNN仍然識別為人類而且置信度不降反增為0.90。為什麼會發生這種和人的直覺不符的現象?這個鍋還得MaxPooling來背,因為MaxPooling只對某個最強特徵做出反應,至於這個特徵出現在哪裡以及特徵之間應該維持什麼樣的合理組合關係它並不關心,總而言之,它給CNN的“位置不變性”太大自由度,所以造成了以上不符合人類認知的判斷結果。
在Capsule的方案中,CNN的卷積層保留,MaxPooling層被拿掉。這裡需要強調的是,Capsule本身是一種技術框架,並不單單是具體的某項技術,Hinton論文給出的是最簡單的一種實現方法,完全可以在遵循其技術思路情況下創造全新的具體實現方法。
要理解Capsule的思路或者對其做一個新的技術實現其實也不困難,只要理解其中的幾個關鍵環節就能實現此目的。如果用一句話來說明其中的關鍵點的話,可以用“一箇中心,兩個基本點”來概括。
這裡的一箇中心,指的是Capsule的核心目的是希望將“視角不變性”能力引入影象處理系統中。所謂“視角不變性”,指的是當我們給3D物體拍照片的時候,鏡頭所對的一定是物體的某個角度看上去的樣子,也就是2D照片反映3D物體一定是體現出了鏡頭和3D物體的某個視角角度,而不是360度的物體全貌。那麼,要達到視角不變性,就是希望給定某個物體某個角度的2D照片,當看到另外一張同一物體不同視角的2D照片時,希望CNN也能識別出其實這仍然是那個物體。這就是所謂的“視角不變性”(參照圖5,上下對應的圖片代表同一物體的不同視角),這是傳統的CNN模型很難做好的事情。

至於說兩個基本點,首先第一個基本點是:用一維向量或者二維陣列來表徵一個物體或者物體的某個部件。傳統的CNN儘管也能用特徵來表徵物體或者物體的構成部件,但是往往是通過不同層級的卷積層或者Pooling層的某個神經元是否被啟用來體現影象中是否具備某個特徵。Capsule則考慮用更多維的資訊來記載並表徵特徵級別的物體,類似於自然語言處理中使用Word Embedding表徵一個單詞的語義。這樣做的好處是描述物體的屬性可以更加細緻,比如可以將物體的紋理、速度、方向等作為描述某個物體的具體屬性。第二個基本點是:Capsule不同層間神經元之間的動態路由機制,具體而言是低層神經元向高層神經元傳遞資訊時的動態路由機制。低層特徵向高層神經元進行動態路由本質上是要體現如下思想:構成一個物體的組成部件之間會通過協同地相互加強的方式來體現這種“整體-組成部分”的關係,比如儘管圖片的視角發生了變換,但是對一個人臉來說,嘴和鼻子等構成人臉的構件會協同地發生類似的視角變換,它們仍然組合在一起構成了從另外一個視角看過去的人臉。如果從本質上來說,動態路由機制其實是組成一個物體的構件之間的特徵聚類,通過聚類的方式把屬於某個物體的組成部分動態地自動找出來,並建立特徵的“整體-部分”的層級構成關係(比如人臉是由鼻子、嘴、眼睛等部件構成)。
以上所述的三個方面是深入理解Capsule的關鍵。Capsule的論文發出來後引發了大量的關注和討論,目前關於Capsule計算框架,大部分人持讚賞的態度,當然也有一些研究人員提出了質疑,比如論文中採用的MINST資料集規模小不夠複雜、Capsule的效能優勢不明顯、消耗較多記憶體計算速度慢等。但是無論這項新計算框架能否在未來取代CNN標準模型,抑或它很快會被人拋棄並遺忘,Hinton老先生這種老而彌堅的求真治學態度,以及勇於推翻自己構建的技術體系的勇氣,這些是值得所有人敬佩和學習的。
CTR預估:向深度學習進行技術升級
CTR預估作為一個偏應用的技術方向,對於網際網路公司而言應該是最重要也最關注的方向之一。道理很簡單,目前大型網際網路公司絕大多數利潤都來源於此,因為這是計算廣告方向最主要的技術手段。從計算廣告的角度講,所謂CTR預估就是對於給定的使用者User,在特定的上下文Context下,如果展示給這個使用者某個廣告或者產品Product,估算使用者是否會點選這個廣告或者是否會購買某個產品,即求點選概率P(Click|User,Product,Context)。可以看到,這是個適用範圍很廣的技術,很多推薦場景以及包括目前比較火的資訊流排序等場景都可以轉換為CTR預估問題。
CTR預估常用的技術手段包括演進路線一般是按照:“LR→GBDT等樹模型→FM因子分解機模型→深度學習”這個路徑來發展的。深度學習在影象視訊、語音、自然語言處理等領域最近幾年獲得了飛速的進展,但是最近一兩年學術界才開始比較頻繁地陸續出現深度學習如何和CTR預估相結合的文章。Google最早在幾年前就開始研究這方面的內容,之後國內的大型網際網路公司也開始跟進。
CTR預估場景有自己獨特的應用特點,而想要用深度學習解決CTR預估問題,必須考慮如何融入和體現這些特點。我們知道,DNN模型便於處理連續數值型特徵,而影象語音等天然滿足這一條件,但是CTR預估場景會包含大量的離散特徵,比如一個人的性別、畢業學校等都屬於離散特徵。所以用深度學習做CTR預估首先要解決的問題是如何表徵離散特徵,一種常見的方法是把離散特徵轉換為Onehot表示,但是在大型網際網路公司應用場景下,特徵維度都是百億以上級別的,如果採用Onehot表徵方式,意味著網路模型會包含太多引數需要學習。所以目前主流的深度學習解決方案都採用將Onehot特徵表示轉換為低維度實數向量(Dense Vector,類似於NLP中的Word Embedding)的思路,這樣可以大量降低引數規模。另外一個CTR關注的重心是如何進行自動特徵組合的問題,因為好的特徵組合對於效能影響非常關鍵,而深度學習天然具有端對端的優勢,所以這是神經網路模型能夠自然發揮作用的地方,能夠無需人工介入自動找到好的特徵組合,這一般體現在深度CTR模型的Deep網路部分。
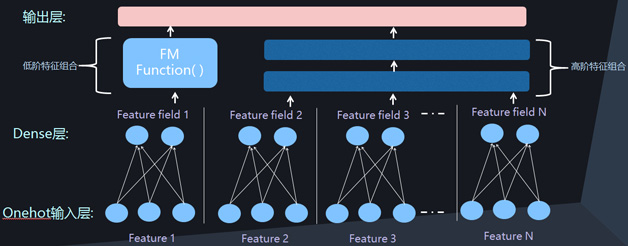
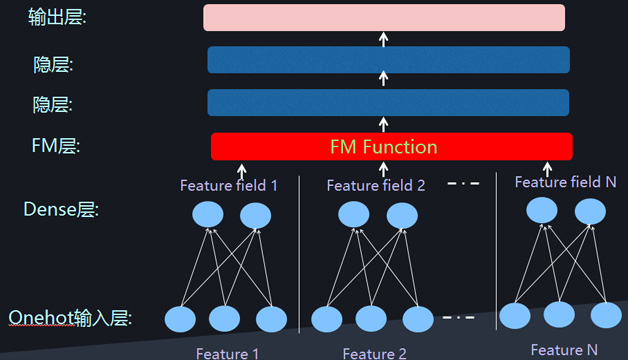
除了更早一些的流傳甚廣的Wide&Deep模型,最近一年出現了一些新的深度CTR模型,比如DeepFM、DeepCross、NFM模型等。這些模型其實如果仔細進行分析,會發現它們在網路結構上存在極大的相似性。除了在網路結構上體現上述的兩個特點:一個是Dense Vector表示離散特徵,另外一個是利用Deep網路對特徵組合進行自動建模外。另外一個主流的特點是將低維特徵組合和高維特徵組合在網路結構上進行分離,Deep網路體現高維度特徵組合,而引入神經網路版本的FM模型來對兩兩特徵組合進行建模。這三個網路結構特點基本囊括了目前所有深度CTR模型。圖6和圖7是兩種常見的深度CTR網路結構,目前所有模型基本都採用了其中之一種結構。
計算機視覺:平穩發展的一年
計算機視覺是AI領域最重要的研究方向之一,它本身又包含了諸多的研究子領域,包括物體分類與識別、目標檢測與追蹤、語義分割、3D重建等一些基礎方向,也有超解析度、圖片視訊描述、圖片著色、風格遷移等偏應用的方向。目前計算機視覺處理的主流技術中,深度學習已經佔據了絕對優勢地位。
對於物體識別、目標檢測與語義分割等基礎研究領域來說,Faster R-CNN、SSD、YOLO等技術仍然是業界最先進最主流的技術手段。在2017年新出現的重要技術中,Facebook的何愷明等提出的Mask R-CNN獲得ICCV2017的最佳論文,它通過對Faster R-CNN增加分支網路的改進方式,同時完成了物體識別、目標檢測與語義分割等基礎任務,這展示了使用同一套技術同時解決多個基礎領域問題的可能性,並會促進後續相關研究的繼續深入探索;而YOLO9000以及同樣是何愷明團隊在論文“Learning to Segment Every Thing”提出的MaskX R-CNN則體現了基礎領域的另外一個重要發展趨勢:嘗試通過技術手段自動識別出更多種類的物品,終極目標是能夠識別任何物體。目前MaskX R-CNN能夠識別超過3000種類別物體,而YOLO9000則能夠識別超過9000種物體類別。很明顯,目標檢測要在各種現實領域大規模獲得使用,除了速度快、識別精準外,能夠大量識別各種現實生活中各種各樣的物體類別也是至關重要的,而最近一年的研究在這方面產生了重要的進展。
從網路模型結構來說,2017年並未產生類似之前ResNet這種產生巨大影響的新模型,ResNet因為其明顯的效能優勢已經廣泛使用在視覺處理的各個子領域中。雖說DenseNet獲得了CVPR2017最佳論文,但它本質上是對ResNet的改進模型,並非全新思路的新模型。
除了上述所說的視覺處理的基礎研究領域,如果對2017年的新技術進行歸納的話,在很多其他應用領域也可以看到如下的一些明顯發展趨勢:
首先,增強學習與GAN等新技術開始被嘗試用來解決很多其它的影象處理領域的問題並取得了一定進展,比如Image-Caption、超解析度、3D重建等領域,開始嘗試引入這些新技術。另外,深度學習與傳統方法如何整合各自的優點並深度融合也是最近一年來視覺處理的方向,深度學習技術具有效能優異等優點,但也存在黑箱不可解釋以及理論基礎薄弱等缺點,而傳統方法具備理論完備等優勢,結合兩者來充分發揮各自優勢克服自身缺點是很重要的。再次,弱監督、自監督或者無監督的方法在各個領域也越來越重要,這是有現實需求的,深度學習雖然效果好,但是對於大量標註訓練資料是有要求的,而這又需要大量的標註成本,在現實中往往不可行。而探索弱監督、自監督甚至無監督的方法有助於更快促進各個領域研究的快速發展。
自然語言處理:進展相對緩慢,急需技術突破
自然語言處理也是人工智慧的重要方向之一,最近兩年深度學習也已經基本滲透到了自然語言處理的各個子領域並取得了一定進展,但是與深度學習在影象、視訊、音訊、語音識別等領域取得的強勢進展相比,深度學習帶給自然語言處理的技術紅利相對有限,相比傳統方法而言,其效果並未取得壓倒性的優勢。至於產生這種現象的原因其實是個值得深入探討的問題,關於其原因目前眾說紛紜,但並未有特別有說服力的解釋能夠被大多數人所接受。
與一年甚至兩年前相比,目前在自然語言處理領域應用的最主流深度學習基本技術工具並未發生巨大變化,最主流的技術手段仍然是以下技術組合大禮包:Word Embedding、LSTM(包括GRU、雙向LSTM等)、Sequence to Sequence框架以及Attention注意力機制。可以在大量自然語言處理子領域看到這些技術構件的組合及其改進的變體模型。CNN在影象領域佔據壓倒性優勢,但是自然語言處理領域仍然是RNN主導的局面,儘管Facebook一直大力倡導基於CNN模型來處理自然語言處理,除了在大規模分散式快速計算方面CNN確實相對RNN具備天然優勢外,目前看不出其具備取代RNN主導地位的其它獨特優勢。
最近一年深度學習在自然語言處理領域應用有以下幾個值得關注的發展趨勢。首先,無監督模型與Sequence to Sequence任務的融合是個很重要的進展和發展方向,比如ICLR 2018提交的論文“Unsupervised Machine Translation Using Monolingual Corpora Only”作為代表的技術思路,它使用非對齊的雙語訓練語料集合訓練機器翻譯系統並達到了較好的效果。這種技術思路本質上是和CycleGAN非常類似的,相信這種無監督模型的思路在2018年會有大量的跟進研究。其次,增強學習以及GAN等最近兩年比較熱門的技術如何和NLP進行結合並真正發揮作用是個比較有前景的方向,最近一年開始出現這方面的探索並取得了一定進展,但是很明顯這條路還沒有走通,這塊值得繼續進行深入探索。再次,Attention注意力機制進一步廣泛使用並引入更多變體,比如Self Attention以及層級Attention等,從Google做機器翻譯的新論文“Attention is all you need”的技術思路可以明顯體會這個趨勢。另外,如何將一些先驗知識或者語言學相關的領域知識和神經網路進行融合是個比較流行的研究趨勢,比如將句子的句法結構等資訊明確引入Sequence to Sequence框架中等。除此外,神經網路的可解釋性也是一個研究熱點,不過這一點不僅僅侷限在NLP領域,在整個深度學習領域範圍也是非常關注的研究趨勢。
本文選擇了若干具有較高關注度的AI技術領域來闡述最近一年來該領域的重要技術進展,受作者能力以及平常主要關注領域的限制,難免掛一漏萬,很多方面的重要技術進展並未列在文中,比如Google在力推的TPU為代表的AI晶片技術的快速發展,讓機器自動學習設計神經網路結構為代表的“學習一切”以及解決神經網路黑箱問題的可解釋性等很多重要領域的進展都未能在文中提及或展開,這些都是非常值得關注的AI技術發展方向。過去的一年AI很多領域發生了重大的技術進展,也有不少領域前進步伐緩慢,但是不論如何,本文作者相信AI在未來的若干年內會在很多領域產生顛覆目前人類想象力的技術進步,讓我們期待這一天早日到來!
作者簡介:
張俊林,中科院軟體所博士,曾擔任阿里巴巴、百度、用友等公司資深技術專家及技術總監職位,目前在新浪微博AI實驗室擔任資深演算法專家,關注深度學習在自然語言處理方面的應用。
本文為《程式設計師》原創文章,未經允許不得轉載,更多精彩文章請訂閱《程式設計師》

相關推薦
2017年AI技術盤點:關鍵進展與趨勢
作者 | 張俊林,新浪微博AI實驗室資深演算法專家 責編 | 何永燦 人工智慧最近三年發展如火如荼,學術界、工業界、投資界各方一起發力,硬體、演算法與資料共同發展,不僅僅是大型網際網路公司,包括大量創業公司以及傳統行業的公司都開始涉足人工智慧。2017年人工
致開發者:2018年AI技術趨勢展望
來源|公眾號“AI 前線”,(ID:ai-front)譯者|核子可樂編輯|Emily概要:在 2
盤點2017年中國資訊無障礙十大進展
2017年,中國的資訊無障礙領域取得了多個重大突破,國家在政策層面給予越來越多的重視,行業實踐層面呈現出全行業共同參與的發展趨勢。中國資訊無障礙產品聯盟(CAPA)祕書處資訊無障礙研究會通過多方徵集,邀請政府相關指導單位和騰訊、阿里巴巴、百度、微軟(中國)、中國
2017年深度學習優化演算法最新進展:改進SGD和Adam方法
2017年深度學習優化演算法最新進展:如何改進SGD和Adam方法 轉載的文章,把個人覺得比較好的摘錄了一下 AMSGrad 這個前期比sgd快,不能收斂到最優。 sgdr 餘弦退火的方案比較好 最近的一些研究(Dozat and Manning, 2017[13]、
3星|《財經》2017年第25期:發生客戶資料泄露,只懲罰個人不懲罰企業是不合理的
它的 變化 2016年 兩個 頁碼 有客 領域 2017年 不改變 本期的“AI犯罪”那篇寫的不錯,比較有深度,另外也沒見其他媒體報道。另一篇提到的“客戶數據遺忘權”是一個比較新鮮的概念,國內的互聯網企業好像是都不支持。
IDC:2017年中國網絡安全市場分析與2018年預測
idc 網絡安全市場 預測 在2017年11月14日,IDC中國在北京召開了2017 CXO數字化轉型年度盛典。會上IDC發表了一些跟中國網絡空間安全市場的一些預測、分析和觀點。在上午的主會場,發布了IDC對2018年中國ICT市場的10大預測,其中包括安全:在對安全的預測中,IDC提出了新一代安
2006年IT技術盤點及IT黑鏡頭
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
乾貨丨2017年AI與深度學習要點大全
2017已經正式離我們遠去~ ~ ~ 部落格WILDML的作者、曾在Google Brain做了一年Resident的Denny Britz,就把他眼中的2017年AI和深度學習的大事,進行了一番梳理彙總。 強化學習稱霸人類遊戲 如果說2016年A
AI技術說:人工智慧相關概念與發展簡史
作為近幾年的一大熱詞,人工智慧一直是科技圈不可忽視的一大風口。隨著智慧硬體的迭代,智慧家居產品逐步走進千家萬戶,語音識別、影象識別等AI相關技術也經歷了階梯式發展。如何看待人工智慧的本質?人工智慧的飛速發展又經歷了哪些歷程?本文就從技術角度為大家介紹人工智慧領域經常提到的幾大
近幾年前端技術盤點以及 2016 年技術發展方向
Web 發展了幾十個春秋,風起雲湧,千變萬化。我很慶幸自己沒有完整地經歷過這些年頭,而是站在前人的肩膀上行走。Web 技術發展的速度讓人感覺那幾乎不是繼承式的迭代,而是一次又一次的變革,一次又一次的創造。這幾年的前端,更為之甚! 我從 12 年底開始接觸前端,12 年之前的前端發展情況只能從上一輩的筆觸中領
大資料回顧2017年網路購物APP:滲透率從63.5%增長至69.9%
【資料猿導讀】 極光大資料推出的《2017年度網路購物app市場研究報告》,將網路購物分為綜合電
一文概述2017年深度學習NLP重大進展與趨勢
作者通過本文概述了 2017 年深度學習技術在 NLP 領域帶來的進步,以及未來的發展趨勢,並與大家分享了這一年中作者最喜歡的研究。2017 年是 NLP 領域的重要一年,深度學習獲得廣泛應用,並且這一趨勢還會持續下去。 近年來,深度學習(DL)架構和演算法在影象識別、語音處理等領域實現了很大的進展。而
《大型網站技術架構:核心原理與案例分析》-- 讀書筆記 (5) :網購秒殺系統
案例 並發 刷新 隨機 url 對策 -- 技術 動態生成 1. 秒殺活動的技術挑戰及應對策略 1.1 對現有網站業務造成沖擊 秒殺活動具有時間短,並發訪問量大的特點,必然會對現有業務造成沖擊。對策:秒殺系統獨立部署 1.2 高並發下的應用、
老男孩教育每日一題-2017年5月18日-說說|(管道)與|xargs(管道xargs)的區別
管道 每日一題 管道xargs 1.題目老男孩教育每日一題-2017年5月18日-說說|(管道)與|xargs(管道xargs)的區別2.參考答案find |xargs ls -ld##把前一個命令的結果,通過管道傳遞給後面的命令(ls -ld),傳遞的是文件名find | 命令 ##把
《大型網站技術架構:核心原理與案例分析》【PDF】下載
優化 均衡 1.7 3.3 架設 框架 應用服務器 博客 分布式服務框架 《大型網站技術架構:核心原理與案例分析》【PDF】下載鏈接: https://u253469.pipipan.com/fs/253469-230062557 內容簡介 本書通過梳理大型網站技
閱讀《大型網站技術架構:核心原理與案例分析》第五、六、七章,結合《河北省重大技術需求征集系統》,列舉實例分析采用的可用性和可修改性戰術
定時 並不會 表現 做出 span class 硬件 進行 情況 網站的可用性描述網站可有效訪問的特性,網站的頁面能完整呈現在用戶面前,需要經過很多個環節,任何一個環節出了問題,都可能導致網站頁面不可訪問。可用性指標是網站架構設計的重要指標,對外是服務承諾,對內是考核指
《大型網站技術架構:核心原理與案例分析》結合需求征集系統分析
運行 模塊 正常 一致性hash 產品 進行 OS 很多 層次 閱讀《大型網站技術架構:核心原理與案例分析》第五、六、七章,結合《河北省重大技術需求征集系統》,列舉實例分析采用的可用性和可修改性戰術,將上述內容撰寫成一篇1500字左右的博客闡述你的觀點。 閱
《大型網站技術架構:核心原理與案例分析》讀後感
TP bubuko 一個 nbsp 分享 架構 優化 技術分享 src 李智慧的著作《大型網站技術架構:核心原理與案例分析》,寫得非常好, 本著學習的態度,對於書中的關於性能優化的講解做了一個思維導圖,供大家梳理思路和學習之用。拋磚引玉。 《大型網站技術架構
《大型網站技術架構:核心原理與案例分析》筆記
· 大型網站軟體系統的特點 · 大型網站架構演化發展歷程 · 初始階段的網站架構 · 需求/解決問題 · 架構 · 應用服務和資料