
Faster RCNN程式碼詳解(四):關於anchor的前世今生
在上一篇部落格中介紹了資料處理的整體結構:Faster RCNN程式碼詳解(三):資料處理的整體結構。這一篇部落格介紹資料處理的細節——關於anchor的前世今生,程式碼在指令碼的:~/mx-rcnn/rcnn/io/rpn.py的assign_anchor函式中。
這一部分也是你想要深入瞭解Faster RCNN演算法細節的重要部分,因為anchor是Faster RCNN演算法的核心之一。具體而言,在這篇部落格中我將為你介紹:anchor是什麼?怎麼生成的?anchor的標籤是怎麼定義的?bbox(bounding box)的迴歸目標是怎麼定義的?bbox和anchor是什麼區別?
def assign_anchor 介紹完了anchor的定義、生成、標籤分配,相信你對anchor的瞭解會更近一步。anchor是從初始化開始就固定了,所以anchor這個名字真的非常形象(翻譯過來是錨)。
在Faster RCNN演算法中你肯定還會經常聽到另一個名詞:region proposal(或者簡稱proposal,或者簡稱ROI),可以說RPN網路的目的就是為了得到proposal,這些proposal是對ground truth更好的刻畫(和anchor相比,座標更貼近ground truth,畢竟anchor的座標都是批量地按照scale和aspect ratio複製的)。如果你還記得在系列二中關於網路結構的介紹,那麼你就應該瞭解到RPN網路的迴歸支路輸出的值(offset)作為smooth l1損失函式的輸入之一時,其含義就是使得proposal和anchor之間的offset(RPN網路的迴歸支路輸出)儘可能與ground truth和anchor之間的offset(RPN網路的迴歸支路的迴歸目標,也就是這篇部落格程式碼中的’bbox_target’)接近。
至此,關於RPN網路中anchor的內容就都介紹完了。我們知道在Faster RCNN演算法中,RPN網路只是其中的一部分,在RPN網路得到proposal後還會經過一系列的過濾操作才會得到送入檢測網路的proposal,這個在系列二中關於網路結構的構造中已經介紹得很清楚了。但是在系列二中有一個自定一個網路層用來將2000個proposal過濾成128個,且為這128個proposal分配標籤、迴歸目標、定義正負樣本的1:3比例等,這部分算是RPN網路和檢測網路(Fast RCNN)的銜接,因此下一篇部落格就來介紹該自定義層的內容:Faster RCNN程式碼詳解(五):關於檢測網路(Fast RCNN)的proposal。
附:
Faster RCNN論文中的公式。bbox_transform函式中的第一個輸入anchors相當於這裡的xa,第二個輸入gt_boxes[argmax_overlaps, :4]相當於這裡的x*(y,w,h同理),而bbox_transform函式實現的就是截圖中下面兩行的4個式子,得到的tx*,ty*,tw*,th*就對應bbox_transform函式的輸出bbox_targets。而前面兩行式子計算的是在你得到預測的bbox資訊(x,y,w,h)後與anchor box資訊計算得到的tx,ty,tw,th。模型的迴歸部分損失函式計算是基於tx,ty,tw,th和tx*,ty*,tw*,th*。
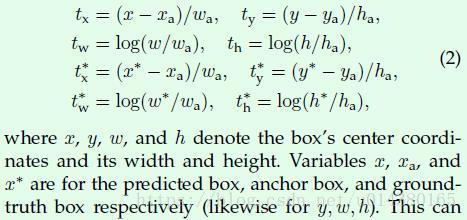
相關推薦
Faster RCNN程式碼詳解(四):關於anchor的前世今生
在上一篇部落格中介紹了資料處理的整體結構:Faster RCNN程式碼詳解(三):資料處理的整體結構。這一篇部落格介紹資料處理的細節——關於anchor的前世今生,程式碼在指令碼的:~/mx-rcnn/rcnn/io/rpn.py的assign_anchor函式
Faster RCNN程式碼詳解(三):資料處理的整體結構
在上一篇部落格中介紹了Faster RCNN網路結構的構建:Faster RCNN程式碼詳解(二):網路結構構建。網路結構是Faster RCNN演算法中最重要兩部分之一,這篇部落格將介紹非常重要的另一部分:資料處理。 資料處理是通過AnchorLoader類
elastic-job詳解(四):失效轉移
shard out utm monit 設置 borde 點滴 title 等於 elastic-job中最關鍵的特性之一就是失效轉移。配置了失效轉移之後,如果在任務執行過程中有一個執行實例掛了,那麽之前被分配到這個實例的任務(或者分片)會在下次任務執行之前被重新分配到其他
Zookeeper詳解(四):Zookeeper中的zkCli.sh客戶端使用
zkCli.sh zookeeper客戶端 最好配置上環境變量連接操作:zkCli.sh -timeout 1000 -r -server 127.0.0.1 # -timeout 設置客戶端和服務器之間的超時時長,單位毫秒 # -r 只讀模式,不加就是讀寫模式 # -server IP:PORT 要
安卓專案實戰之強大的網路請求框架okGo使用詳解(四):Cookie的管理
Cookie概念相關 具體來說cookie機制採用的是在客戶端保持狀態的方案,而session機制採用的是在伺服器端保持狀態的方案。同時我們也看到,由於採用伺服器端保持狀態的方案在客戶端也需要儲存一個標識,所以session機制是需要藉助於cookie機制來達到儲存標識的目的,所謂ses
Tkinter 元件詳解(四):Radiobutton
Tkinter 元件詳解之Radiobutton Radiobutton(單選按鈕)元件用於實現多選一的問題。Radiobutton 元件可以包含文字或影象,每一個按鈕都可以與一個 Python 的函式或方法與之相關聯,當按鈕被按下時,對應的函式或方法將被自動執行。 Radiobutto
HTTP詳解(四):JAVA實現HTTP請求
通過上幾篇的文章,我們對HTTP已經已經有了一個初步的認識,對於"為什麼要用HTTP","怎麼用HTTP","HTTP是什麼"相信大家都有了一個了一個屬於自己的看法,今天這篇文章主要是程式碼的角度上去實現HTTP的請求。
Pygame詳解(四):event 模組
pygame.event 用於處理事件與事件佇列的 Pygame 模組。 函式 pygame.event.pump() — 讓 Pygame 內部自動處理事件 pygame.event.get() —&nb
郵件實現詳解(四)------JavaMail 發送(帶圖片和附件)和接收郵件
發送 網絡圖 發送對象 true n) com 訪問權限 sub map 好了,進入這個系列教程最主要的步驟了,前面郵件的理論知識我們都了解了,那麽這篇博客我們將用代碼完成郵件的發送。這在實際項目中應用的非常廣泛,比如註冊需要發送郵件進行賬號激活,再比如OA項目中利用郵
Quartz學習——SSMM(Spring+SpringMVC+Mybatis+Mysql)和Quartz集成詳解(四)
webapp cron表達式 msi 接口 cli post 定時 報錯 gets Quartz學習——SSMM(Spring+SpringMVC+Mybatis+Mysql)和Quartz集成詳解(四) 當任何時候覺你得難受了,其實你的大腦是在進化,當任何時候你覺得
07-Linux中DNS詳解(四)
用戶 mail all 驗證 src 更改 條目 http nslookup 接“06-Linux中DNS詳解(三)” 九、配置主從DNS服務器實現域名解析容錯 1、實驗環境zhangyujia.com(192.168.80.100)為主區域,com(192.168.8
編碼原理詳解(四)---之字形掃描
便是 集中 img 詳解 工作 -- 漢字 如何 編碼原理 上一篇我們講到,經過量化後得到了諸多零值和整數值,本篇接下來講講編碼過程中過對這些值如何組織和處理,那就是ZigZag掃描嘍。 一、簡介 ZigZag掃描也稱作之字形掃描,何以得此稱謂,是因為其掃描的路徑特
Nginx詳解(四)模塊
nginx https fastcgi 一、Nginx之目錄瀏覽二、Nginx之log模塊三、Ning之gzip模塊四、Nginx之https服務五、Nginx之fastCGI模塊 一、配置Nginx提供目錄瀏覽功能 1.修改nginx配置文件 server { listen
Keepalived詳解(四)
mysql pan 節點 ios all -s 關閉 定義 interval 一.通過vrrp_script實現對集群資源的監控: Keepalived基礎HA功能時用到了vrrp_script這個模塊,此模塊專門用於對集群中服務資源進行監控。與此模塊一起使用
PE文件格式詳解(四)
ebs 位置 數位 地址 inf font pe文件 。。 地址轉換 PE文件格式詳解(四) 0x00 前言 上一篇介紹了區塊表的信息,以及如何在hexwrokshop找到區塊表。接下來,我們繼續深入了解區塊,並且學會文件偏移和虛擬地址轉換的知識。 0x01 區塊對齊值
PE檔案格式詳解(四)
PE檔案格式詳解(四) 0x00 前言 上一篇介紹了區塊表的資訊,以及如何在hexwrokshop找到區塊表。接下來,我們繼續深入瞭解區塊,並且學會檔案偏移和虛擬地址轉換的知識。 0x01 區塊對齊值 首先我們要知道啥事區塊對齊?為啥要區塊對齊?這個問題
【SpringBoot學習之路】08.Springboot配置檔案詳解(四)
轉載宣告:商業轉載請聯絡作者獲得授權,非商業轉載請註明出處.原文來自 © 呆萌鍾【SpringBoot學習之路】08.Springboot配置檔案詳解(四) 自動配置原理 配置檔案到底能寫什麼?怎麼寫?自動配置原理; 配置檔案能配置的屬性參照
Java 反射機制詳解(四)
Java 反射機制詳解(四) 4. 反射與泛型 定義一個泛型類: public class DAO<T> { //根據id獲取一個物件 T get(Integer id){ return null; }
Redis底層詳解(四) 整數集合
一、集合概述 對於集合,STL 的 set 相信大家都不陌生,它的底層實現是紅黑樹。無論插入、刪除、查詢都是 O(log n) 的時間複雜度。當然,如果用雜湊表來實現集合,插入、刪除、查詢都可以達到 O(1)。那麼為什麼集合要用紅黑樹