
Kafka實戰-Kafka Cluster
1.概述
在《Kafka實戰-入門》一篇中,為大家介紹了Kafka的相關背景、原理架構以及一些關鍵知識點,本篇部落格為大家來贅述一下Kafka Cluster的相關內容,下面是今天為大家分享的目錄:
- 基礎軟體的準備
- Kafka Cluster的部署
- Send Messages
- HA特性
下面開始今天的內容分享。
2.基礎軟體的準備
2.1 ZK
由於Kafka Cluster需要依賴ZooKeeper(後面簡稱ZK)叢集來協同管理,所以這裡我們需要事先搭建好ZK叢集,關於ZK的叢集搭建,大家可以參考我寫的《配置高可用的Hadoop平臺》,這篇文章中我介紹瞭如何去搭建ZK,這裡就不多贅述,本篇部落格為大家介紹如何去搭建Kafka Cluster。
2.2 Kafka
由於Kafka已經貢獻到Apache基金會了,我們可以到Apache的官方網站上去下載Kafka的基礎安裝包,下載地址如下所示:
Kafka安裝包 [下載地址]
Kafka原始碼 [下載地址]
這裡,我們直接使用官方編譯好的安裝包進行Kafka Cluster的安裝部署。下面我們來開始Kafka Cluster的搭建部署。
3.Kafka Cluster的部署
首先,我們將下載好的Kafka基礎安裝包解壓,命令如下所示:
- 解壓Kafka
[[email protected] ~]$ tar -zxvf kafka_2.9.1-0.8.2.1.tgz
- 進入到Kafka解壓目錄
[[email protected] ~]$ cd kafka_2.9.1-0.8.2.1
- 配置環境變數
[[email protected] ~]$ vi /etc/profile
export KAFKA_HOME=/home/hadoop/kafka_2.11-0.8.2.1 export PATH=$PATH:$KAFKA_HOME/bin
- 配置Kafka的zookeeper.properties
# the directory where the snapshot is stored. dataDir=/home/hadoop/data/zk # the port at which the clients will connect clientPort=2181 # disable the per-ip limit on the number of connections since this is a non-production config maxClientCnxns=0
- 配置server.properties
# The id of the broker. This must be set to a unique integer for each broker. broker.id=0
注:這裡配置broker的時候,每臺機器上的broker保證唯一,從0開始。如:在另外2臺機器上分別配置broker.id=1,broker.id=2
- 配置producer.properties
# list of brokers used for bootstrapping knowledge about the rest of the cluster # format: host1:port1,host2:port2 ... metadata.broker.list=dn1:9092,dn2:9092,dn3:9092
- 配置consumer.properties
# Zookeeper connection string # comma separated host:port pairs, each corresponding to a zk # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002" zookeeper.connect=dn1:2181,dn2:2181,dn3:2181
至此,Kafka Cluster部署完成。
4.Send Messages
4.1啟動
首先,在啟動Kafka叢集服務之前,確保我們的ZK叢集已啟動,下面我們啟動Kafka叢集服務。啟動命令如下所示:
[[email protected] kafka_2.11-0.8.2.1]$ kafka-server-start.sh config/server.properties &
注:其他2個節點參照上述方式啟動。
另外,啟動其他節點的時候,在最先開始啟動的節點會顯示其它節點加入的資訊記錄,如下圖所示:

4.2驗證啟動程序
[[email protected] kafka_2.11-0.8.2.1]$ jps 2049 QuorumPeerMain 2184 Kafka 2233 Jps
4.3建立Topic
在服務啟動後,我們開始建立一個Topic,命令如下所示:
[[email protected] ]$ kafka-topics.sh --zookeeper dn1:2181,dn2:2181,dn3:2181 --topic test1 --replication-factor 3 --partitions 1 --create
然後,我們檢視該Topic的相關資訊,命令如下所示:
[[email protected] ]$ kafka-topics.sh --zookeeper dn1:2181,dn2:2181,dn3:2181 --topic test1 --describe
預覽資訊如下圖所示:

下面解釋一下這些輸出。第一行是對所有分割槽的一個描述,然後每個分割槽都會對應一行,因為我們只有一個分割槽所以下面就只加了一行。
- Leader:負責處理訊息的讀和寫,Leader是從所有節點中隨機選擇的。
- Replicas:列出了所有的副本節點,不管節點是否在服務中。
- Isr:是正在服務中的節點
4.4生產訊息
下面我們使用kafka的Producer生產一些訊息,然後讓Kafka的Consumer去消費,命令如下所示:
[[email protected] ]$ kafka-console-producer.sh --broker-list dn1:9092,dn2:9092,dn3:9092 --topic test1

4.4消費訊息
接著,我們在另外一個節點啟動消費程序,來消費這些訊息,命令如下所示:
[[email protected] ]$ kafka-console-consumer.sh --zookeeper dn1:2181,dn2:2181,dn3:2181 --from-beginning --topic test1
消費記錄如下圖所示:

5.HA特性
這裡,從上面的截圖資訊可以看出,在DN1節點上Kafka服務上Lead,我們先將DN1節點的Kafka服務kill掉,命令如下:
[[email protected] config]$ jps 2049 QuorumPeerMain 2375 Jps 2184 Kafka [[email protected] config]$ kill -9 2184
然後,其他節點立馬選舉出了新的Leader,如下圖所示:

下面,我們來測試訊息的生產和消費,如下圖所示:
- 生產訊息

- 消費訊息
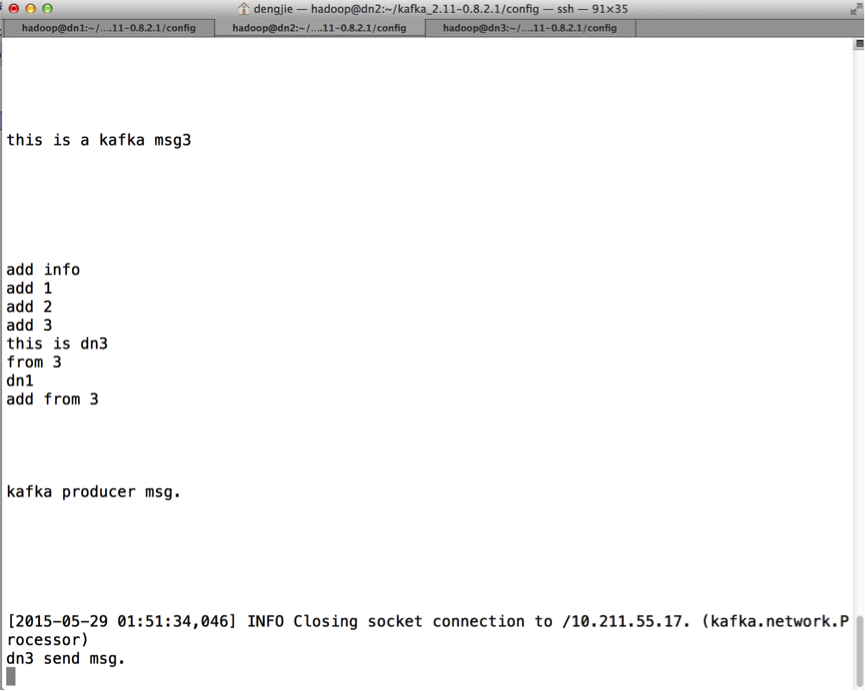
通過測試,可以發現,Kafka的HA特性還是不錯的,擁有不錯的容錯機制。
6.總結
這裡,在部署Kafka Cluster的時候,有些地方需要我們注意,比如:在我們啟動Kafka叢集的時候,確保ZK叢集啟動,另外,在配置Kafka配置檔案資訊時,確保ZK的叢集資訊配置到相應的配置檔案中,總體來說,配置還算較為簡單,需要在部署的時候,仔細配置各個檔案即可。
7.結束語
這篇部落格就和大家分享到這裡,如果大家在研究學習的過程當中有什麼問題,可以加群進行討論或傳送郵件給我,我會盡我所能為您解答,與君共勉!
相關推薦
Kafka實戰-Kafka Cluster
1.概述 在《Kafka實戰-入門》一篇中,為大家介紹了Kafka的相關背景、原理架構以及一些關鍵知識點,本篇部落格為大家來贅述一下Kafka Cluster的相關內容,下面是今天為大家分享的目錄: 基礎軟體的準備 Kafka Cluster的部署 Send Messages HA特性
KafkaOffsetMonitor Kafka實戰-KafkaOffsetMonitor
1.概述 前面給大家介紹了Kafka的背景以及一些應用場景,並附帶上演示了Kafka的簡單示例。然後,在開發的過程當中,我們會發現一些問題,那就是訊息的監控情況。雖然,在啟動Kafka的相關服務後,我們生產訊息和消費訊息會在終端控制檯顯示這些記錄資訊,但是,這樣始終
Kafka實戰-簡單示例
1.概述 上一篇部落格《Kafka實戰-Kafka Cluster》中,為大家介紹了Kafka叢集的安裝部署,以及對Kafka叢集Producer/Consumer、HA等做了相關測試,今天我們來開發一個Kafka示例,練習如何在Kafka中進行程式設計,下面是今天的分享的目錄結構: 開發環境
Kafka實戰-入門
1.概述 經過一個多月的時間觀察,業務上在整合Kafka後,各方面還算穩定,這裡打算抽時間給大家分享一下Kafka在實際場景中的一些使用心得。本篇部落格打算先給大家入個門,讓大家對Kafka有個初步的瞭解,知道Kafka是做什麼的,下面是本篇部落格的目錄內容: Kafka背景 Kafka應用場景
Kafka實戰-KafkaOffsetMonitor
1.概述 前面給大家介紹了Kafka的背景以及一些應用場景,並附帶上演示了Kafka的簡單示例。然後,在開發的過程當中,我們會發現一些問題,那就是訊息的監控情況。雖然,在啟動Kafka的相關服務後,我們生產訊息和消費訊息會在終端控制檯顯示這些記錄資訊,但是,這樣始終不夠友好,而且,在實際開發中,我們不
Kafka專案實戰-使用者日誌上報實時統計之編碼實踐
1.概述 該課程我以使用者實時上報日誌案例為基礎,帶著大家去完成各個KPI的編碼工作,實現生產模組、消費模組,資料持久化,以及應用排程等工作, 通過對這一系列流程的演示,讓大家能夠去掌握Kafka專案的相關編碼以及排程流程。下面,我們首先來預覽本課程所包含的課時,他們分別
kafka----kafka API(java版本)
spring mvc+my batis dubbo+zookeerper kafka restful redis分布式緩存 Apache Kafka包含新的Java客戶端,這些新的的客戶端將取代現存的Scala客戶端,但是為了兼容性,它們仍將存在一段時間。可以通過一些單獨的jar包調用這些客
kafka實戰
www ase htm 需要 sum pro fig line from 一、下載地址:https://www.apache.org/dyn/closer.cgi?path=/kafka/0.10.2.0/kafka_2.11-0.10.2.0.tgz Java: http
Kafka實戰:如何把Kafka消息時延秒降10倍
Kafka 消息服務 時延 背景 中軟獨家中標稅務核心征管系統,全國34個省國/地稅。電子稅務局15省格局。大數據×××局點,中國軟件電子稅務局技術路徑:核心征管 + 納稅服務 業務應用分布式上雲改造。 業務難題 如上圖所示是模擬客戶的業務網頁構建的一個並發訪問模型。用戶在頁面點擊從而產生一個HT
(轉)kafka實戰
ucc 終端 4.2 tail comm 原因 fault con 目錄 轉自https://www.cnblogs.com/hei12138/p/7805475.html 1. kafka介紹 1.1. 主要功能 根據官網的介紹,
DataPipeline |Apache Kafka實戰作者胡夕:Apache Kafka監控與調優
推出 充足 不足 交互 進入 時間片 第一條 小時 send 胡夕,《Apache Kafka實戰》作者,北航計算機碩士畢業,現任某互金公司計算平臺總監,曾就職於IBM、搜狗、微博等公司。國內活躍的Kafka代碼貢獻者。 前言雖然目前Apache Kafka已經全面進化成
ActiveMQ RabbitMQ RokcetMQ Kafka實戰 消息隊列中間件視頻教程
基於 存儲 中間 商品數據 ssa lan 如何 spa ring ActiveMQ第01節:ActiveMQ入門和消息中間件第02節:JMS基本概念和模型第03節:JMS的可靠性機制第04節:JMS的API結構和開發步驟_rec_rec第05節:Broker的啟動方式吖第
《Apache Kafka 實戰》讀書筆記-認識Apache Kafka
《Apache Kafka 實戰》讀書筆記-認識Apache Kafka 作者:尹正傑 版權宣告:原創作品,謝絕轉載!否則將追究法律責任。
kafka實戰 - 刪除topic
默認值 的區別 正常 方法 物理文件 bin 版本 感覺 ger 概述 在平時對kafka的運維工作中,我們經常會由於某些原因去刪除一個topic,比如這個topic是測試用的,生產環境中需要刪除。或者我想擴容topic的同時,這個topic中的數據我不想要了,這時候刪
kafka實戰 - 處理大檔案需要注意的配置引數
概述 kafka配置引數有很多,可以做到高度自定義。但是很多使用者拿到kafka的配置檔案後,基本就是配置一些host,port,id之類的資訊,其他的配置項採用預設配置,就開始使用了。這些預設配置是經過kafka官方團隊經過嚴謹寬泛的測試之後,求到的最優值。在單條資訊很小,大部分場景下都能得到優異的效
kafka實戰 - 處理大文件需要註意的配置參數
了解 自定義 等於 副本 lead lar 做到 0.10 新的 概述 kafka配置參數有很多,可以做到高度自定義。但是很多用戶拿到kafka的配置文件後,基本就是配置一些host,port,id之類的信息,其他的配置項采用默認配置,就開始使用了。這些默認配置是經過k
[Spark]Spark-streaming通過Receiver方式實時消費Kafka流程(Yarn-cluster)
1.啟動zookeeper 2.啟動kafka服務(broker) [[email protected] kafka_2.11-0.10.2.1]# ./bin/kafka-server-start.sh config/server.properties 3.啟動kafka的producer(
kafka實戰 - 資料可靠性
概述 常見的儲存高可用方案的根本原理就是把資料複製到多個儲存裝置,通過資料冗餘的方式來實現資料的可靠性。比如同一份資料,一份在城市A,一份在城市B。如果城市A發生自然災害導致機房癱瘓,那麼業務就可以直接切到城市B進行服務,從而保障業務的高可用。但是這是理想情況,一旦資料被複制並且分開儲存,就涉及到了網路
spark筆記之Spark Streaming整合kafka實戰
kafka作為一個實時的分散式訊息佇列,實時的生產和消費訊息,這裡我們可以利用SparkStreaming實時地讀取kafka中的資料,然後進行相關計算。 在Spark1.3版本後,KafkaUtils裡面提供了兩個建立dstream的方法,一種為KafkaUtils.cr
大數據日誌傳輸之Kafka實戰教程
大數 以及 rod 批量commit 控制器 核心 pan Once 異步 大數據日誌傳輸之Kafka實戰 本套課程圍繞Kafka架構詳細講解kafka的核心 架構組件,broker,consumer,producer,以及日誌的分段存儲,稀疏索引,副本平衡,重分區, 數據