
Data Driven Inner Source
Data Driven Inner Source


By Jakub Kadlubiec and Giovanni Perna
About a year ago at Skyscanner we started promoting the inner source model. At the time several teams within the company were already working in an internal open source way by contributing to codebases owned by different teams. The general feeling was pretty positive, but we were aware that the adoption of this model was adding additional workload on some teams or areas of the business. Our initial goal was to identify those areas.
We started by asking our colleagues how this worked for them, but we soon realised that it was still difficult to get the whole picture. Skyscanner is a data-driven company and we thought that, once again data could have helped us, not just in getting that early feedback but also in monitoring the adoption of the inner source model over time.
The obvious question at this point was: Where to get this data from? There was an obvious answer too: GitLab!
In the first brainstorming session we identified a number of views on the data that could have given us a better understanding of how teams were coping with the adoption of the inner source model:
- Count of open, external (to the team) Merge Requests (MRs) per project.
- Average duration that an external MR remains open per project.
- Average number of comments per external MR per project.
We also realised that in Skyscanner we already had a service that was gathering and analysing GitLab data for a different purpose, and we thought that it could have been extended to cover this other use case. Next section contains an overview of the service and how it was later adapted to monitor inner source activity.
Gathering the data
Due to the amount of development activity happening in the company we needed to gather the inner source metrics automatically. Before we explain how we implemented the data collection solution, it is necessary to understand how Skyscanner teams structure their codebases.
Background: repository-per-service model
We are promoting a repository-per-service model at Skyscanner. We chose this over mono-repo for two main reasons:
- it’s flexible — teams are not constrained by others
- no need for special infrastructure to handle partial clones, partial deployment, etc.
At the moment we have over 10k repositories in the company and it is difficult to know what all those repositories contain. We don’t know what are those projects, whether they are even used (hint: most of them aren’t), what technologies are they built in, whether they follow the company engineering standards, etc..
We built Surveyor to solve this problem for us. The service scans all GitLab repositories every night and collects data about projects. We are tracking almost 90 attributes for each project.


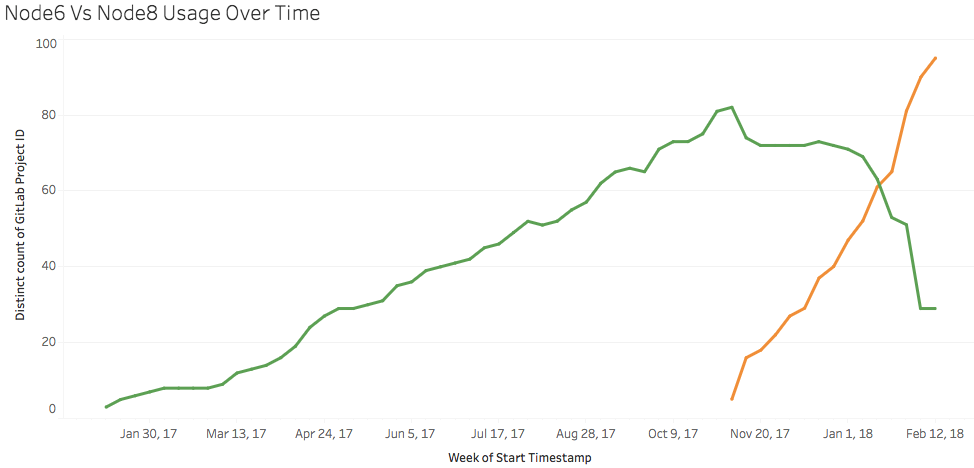
The architecture of Surveyor is simple: it is a Python service deployed to ECS on AWS. Each night it initiates a scan and uses GitLab API to get info about projects. It then retrieves some of the important files projects have (e.g. build.gradle, requirements.txt, package.json) again using the API. It doesn’t need to clone the repository locally. The files are then parsed and important information is stored in the PostgreSQL database running in RDS. The historical data is preserved allowing us to see how things changed in the past. For example the following graph shows our progress over time with moving projects to from Node 6 to Node 8:

Extending Surveyor to scan Merge Requests
We chose to extend Surveyor to get metrics on inner source activity in the company. Surveyor already contained all the infrastructure needed to gather, store and analyse data from GitLab. Now every scan not only gathers data about projects source code, but also about merge requests which were created or changed since last scan. Again, this is all retrieved using the GitLab API.
We store the basic information about each merge request: who created it, its state, who merged it, time it took to merge, etc. But more importantly, Surveyor is also trying to recognise automatically whether the MR was created by someone who owns the project (and thus it doesn’t represent inner source activity) or by someone from outside.
This is where the repository-per-service model comes in handy as we can use GitLab’s permission system to check who has ‘owner’ or ‘master’ access to individual projects and thus can be considered an owner.
GitLab permissions system sometimes doesn’t accurately reflect the true ownership of a project, but it’s close enough.
Again, Tableau is used to visualise the data:



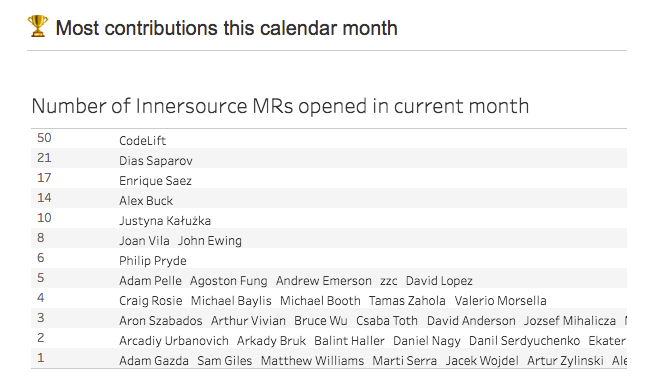
Let’s end by presenting some interesting statistics about Skyscanner engineering activity:
- in January 2018, our engineers opened 6033 merge requests in total
- out of it, 1609 merge requests represent inner source activity. This is a bit more than one in four
- our most active project received 60 inner source MRs in January. This is more than 3 MRs per work day created by someone outside of the owning team. A lot of additional workload for the owners!
- our most active engineer opened 88 merge requests in January 2018 and our most active reviewer approved 140 merge requests in the same time period
Are you interested in any other statistic? ask us in the comments section!
Internal Open Source
This is part 3 in a series of 3 posts
SEE the world with us
Many of our employees have had the opportunity to take advantage of our Skyscanner Employee Experience (SEE) — a self-funded, self-organized programme to work up to 30 days during a 24 month period, in some of our 10 global offices. There is also the opportunity to work for 15 days per year from their home country, if an employee is based in an office outside of the country they call home.
About the authors
My name is Giovanni Perna. I’m a full-stack software engineer working in the Quantum team in sunny Barcelona. We look after the Skyscanner configuration service. I love (free)diving, travelling and sport in general.
I am Jakub, engineering manager in the London office. I lead a team which helps engineers with automating their daily duties and rump up the productivity of every developer in the company. I have 6 years of professional history from global companies and as well as startups. I’m enthusiastic about Agile and Lean software development, Domain Driven Design, Continuous Delivery and Cloud.
Remember! Sign up for our Skyscanner Engineering newsletter to hear more about what we’re working on, interesting problems we’re trying to solve and our latest job vacancies.
相關推薦
Data Driven Inner Source
Data Driven Inner SourceBy Jakub Kadlubiec and Giovanni PernaAbout a year ago at Skyscanner we started promoting the inner source model. At the time severa
Spock - Document - 03 - Data Driven Testing
respond toupper random purpose annotate nth fin edi ply Data Driven Testing Peter Niederwieser, The Spock Framework TeamVersion 1.1
Swift 4 Developing a Data-Driven App
trac art agents speech pdf drive ring modified features 代做Swift 4作業、代寫HTML/CSS/web作業、代做Data-Driven App作業、代寫CSS/web語言作業Developing a Data-D
Data Driven Investor
Binomial TheoremIf you’re like me — haven’t touched math/statistics in years but trying to tackle concepts for Machine Learning— here’s a really easy way t
Data-Driven Introspection
1. I am 22% happier on average during days where I hang out with friendsThroughout my trip, I met up with friends who were around the same area. This insig
Build data driven apps with real time and offline capabilities based on GraphQL
AWS AppSync is a serverless back-end for mobile, web, and enterprise applications. AWS AppSync makes it easy to build data driven mobile a
Amazon Machine Learning – Make Data-Driven Decisions at Scale
Today, it is relatively straightforward and inexpensive to observe and collect vast amounts of operational data about a system, product, or proces
Introducing AWS AppSync – Build data-driven apps with real-time and off-line capabilities
In this day and age, it is almost impossible to do without our mobile devices and the applications that help make our lives easier. As our depende
SoapUI 測試Data Driven(資料驅動測試)
1.1. Prereqs In our example we have the following; A Microsoft SQL Server database (db_author) instance with one table, tb_au
論文: Data-Driven Evolutionary Optimization: An Overview and case studies(1) 資料驅動概念,文章結構,大數分類
宣告: 只作為自己閱讀論文的相關筆記記錄,理解有誤的地方還望指正 論文下載連結: 概念:資料驅動? Solving evolutionary optimization problems driven by data collected in simulation
論文: Data-Driven Evolutionary Optimization : An Overview and Case Studies(3) 總結部分以及自己的想法
感悟: 一篇論文看完了,就覺得行業資料的而獲取以及最初的一些對資料的操作,無論是預處理,資料探勘,還是人為的製造一些資料進行輔助模型的優化,都有很重要的作用,而且也讓我覺得這個EA其實再再應用的時候是一個跨度很大的,你需要綜合各種資訊,各行業各領域的
Ⅰ.18.2 如何實現Data-Driven Testing
Data-Driven Testing是一種將測試資料(輸入,和期望輸出)從只包含測試邏輯的測試指令碼程式碼中區別開的方法。對於測試資料正常的實踐是從一個檔案或資料庫中讀取一項或記錄,對於測試指令碼使
What is Data Driven Testing? Learn to create Framework
rally nal sse multiple navi str eat fun append What is Data Driven Testing? Data-driven is a test automation framework which stores test
Data-Driven Documents
D3 是一個Javascipt libray,用於在html頁面繪製互動式圖形/圖表來展示資料。 https://d3js.org Tutorial: https://github.com/d3/d3/wiki/Tutorials
CS602 - Data-Driven Development
宋體 creat displays knowledge sha sum ide should lec CS602 - Data-Driven Development with Python Spring 2019 Programming AssignmentProgramm
Data-driven Raster Layer with Mapbox GL
We at Ubilabs recently had the opportunity to inspect t
Data source rejected establishment of connection, message from server: "Too many connections"
重新 並發 登錄用戶 -c https 但是 ces 部署 ins 詳細錯誤信息: Caused by: com.MySQL.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Data source re
Data source rejected establishment of connection, message from server: "Too many connections"
logs ucc access register nds code mysq acc ora 1 com.mchange.v2.resourcepool.BasicResourcePool(line/:1841) - 2 [email protec
C# 連接SQL Server數據庫的幾種方式--server+data source等方式
如何使用 sel 特定 html 項目 true -- 計算機 技術分享 C# 連接SQL Server數據庫的幾種方式--server+data source等方式 如何使用Connection對象連接數據庫? 對於不同的.NET數據提供者,ADO.NET采用不同
039_External Data Source(轉載)
技術分享 1.2 存儲 detail 平臺 cnblogs 暴露 由於 external 場景描述:很多時候在實際開發中都會遇到很多數據集成問題,如Salesforce和SAP同步數據。為了讓類似問題能方便、快速地解決,Salesforce提供了"外部數據源"這樣的工具,只