
scrapy利用scrapy-splash爬取JS動態生成的標籤
1 引言
scrapy處理爬取靜態頁面,可以說是很好的工具,但是隨著技術的發展,現在很多頁面都不再是靜態頁面了,都是通過AJAX非同步載入資料動態生成的,我們如何去解決問題呢?今天給大家介紹一種方法:scrapy-splash
2 準備工作
首先需要安裝一下幾個工具
(1)docker
(2)scrapy-splash
因為這裡我的作業系統是window,所以只給出window安裝docker過程(Linux自行百度,安裝很方便的)
1)下載docker toolbox並解壓安裝即可(下載地址:https://download.csdn.net/download/qq_38003892/10391403
在這個過程中需要注意一下幾個問題:
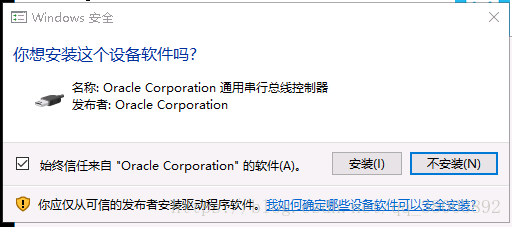
彈出這樣的對話方塊點選安裝即可
2)找到桌面上的Docker Quickstart Terminal開啟,它會自動安裝一些東西
3)修改pull源
注意:這裡預設的pull源不是國內的,所以下載速度特別慢,這裡可以通過國內的阿里雲映象庫去下載,具體做法如下:
1 開啟阿里雲官網:https://www.aliyun.com/
2 登入->進入管理控制檯
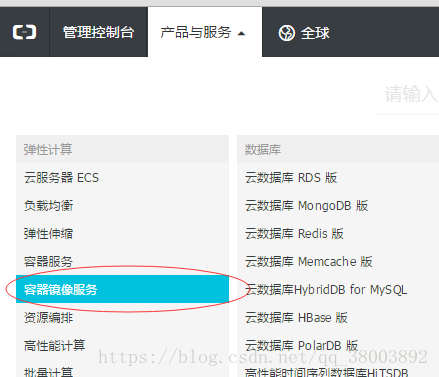
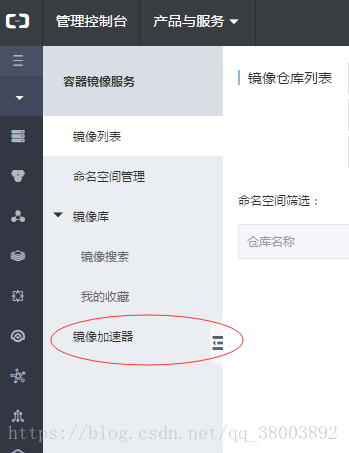
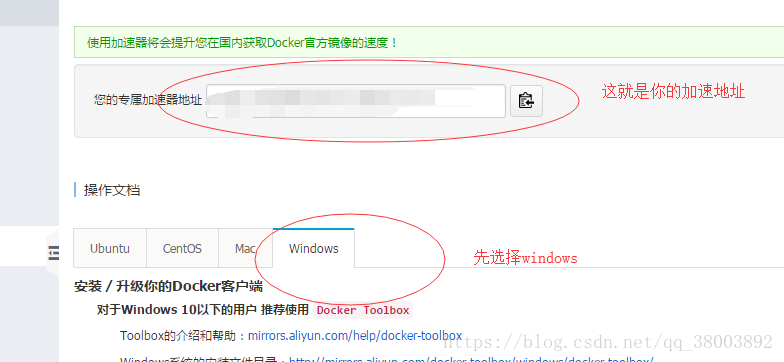
3 然後在docker 中輸入 docker pull xxxxxx.mirror.aliyuncs.com/scrapinghub/splash
4 下載好之後開啟splash 命令:docker run -p 8050:8050 scrapinghub/splash
5 然後在瀏覽器中輸入
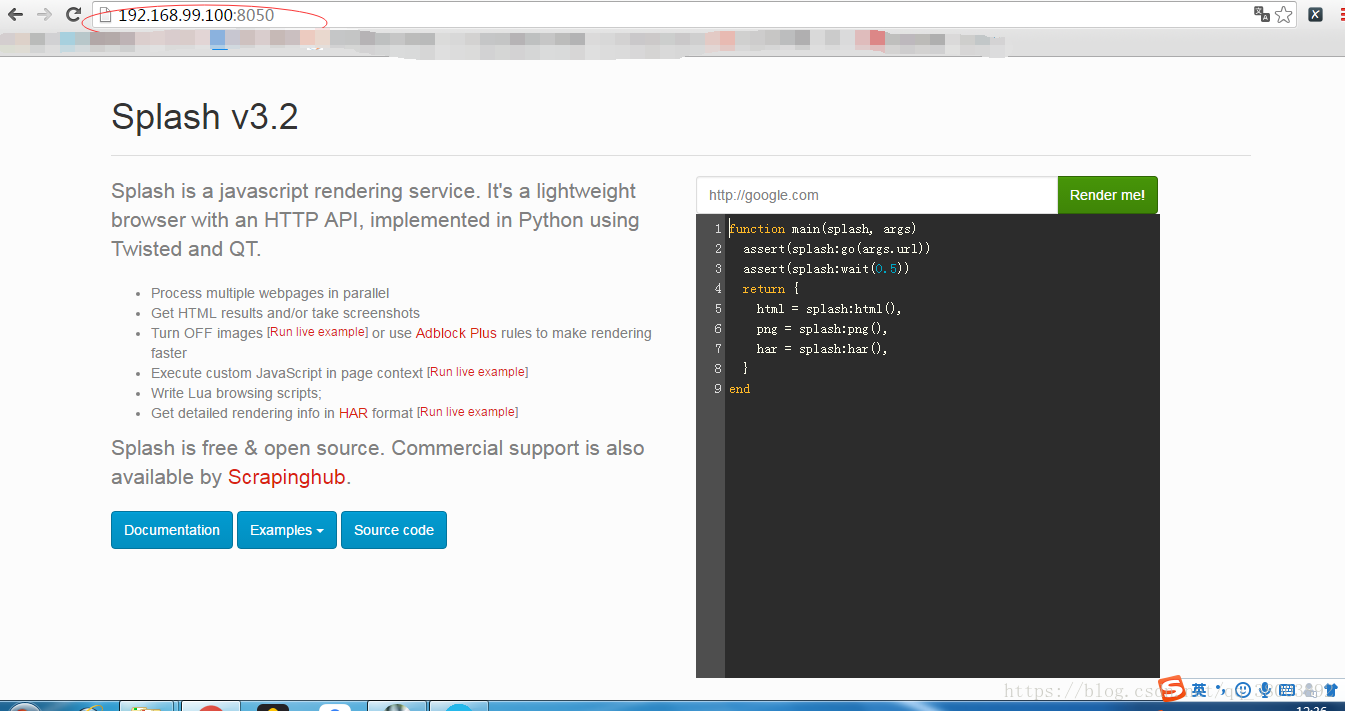
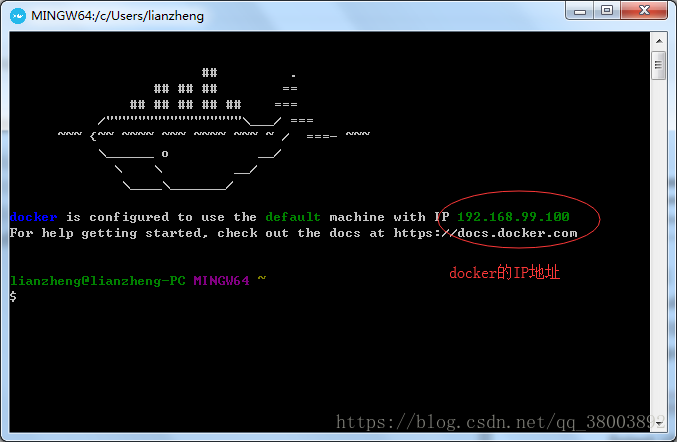
注意這裡的網址 是 由你的docker IP地址決定的 埠號就是你執行splash的埠號(8050)
4)安裝scrapy-splash
開啟cmd 輸入命令:pip install scrapy-splash
3 測試
1 建立爬蟲專案(這裡不多說了)
2 在settings.py中設定以下幾項(若沒有則新增):
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
# 渲染服務的url
SPLASH_URL = 'http://192.168.99.100:8050'
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware' 3 建立spider,並編寫
這裡用這樣一個例子,給大家說明
爬蟲目標網站:http://39.104.87.35/findex/
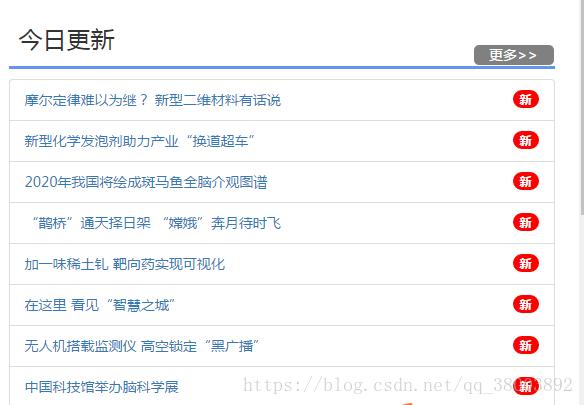
爬取網站今日更新截圖:
網頁原始碼:

爬蟲程式碼:
# -*- coding: utf-8 -*-
import scrapy
from scrapy_splash import SplashRequest
class TestSpider(scrapy.Spider):
name = 'test'
start_urls = ['http://39.104.87.35/findex/']
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url=url, callback=self.parse, args={'wait': 1})
def parse(self, response):
print(response.xpath('//ul[@id="updatelist"]/li//a/text()').extract())
爬取結果:

這樣我們就大功告成了!