
ACL 2017自然語言處理精選論文
作者簡介:洪亮劼,Etsy資料科學主管,前雅虎研究院高階經理。長期從事推薦系統、機器學習和人工智慧的研究工作,在國際頂級會議上發表論文20餘篇,長期擔任多個國際著名會議及期刊的評審委員會成員和審稿人。
責編:何永燦([email protected])
本文為《程式設計師》原創文章,未經允許不得轉載,更多精彩文章請訂閱《程式設計師》
涉及自然語言處理、人工智慧、機器學習等諸多理論以及技術的頂級會議——第55屆計算語言學年會(The 55th Annual Meeting of the Association for Computational Linguistics,簡稱ACL會議)於今年7月31日-8月4日在加拿大溫哥華舉行。從近期谷歌學術(Google Scholar)公佈的學術雜誌和會議排名來看,ACL依然是最重要的自然語言處理相關的人工智慧會議。
摘要:本文的核心思想為如何用Gaussian Mixture Model來對Word Embedding進行建模,從而可以學習文字的多重表達。這篇文章值得對Text Mining有興趣的讀者泛讀。
文章作者Ben Athiwaratkun是康奈爾大學統計科學系的博士生。Andrew Gordon Wilson是新加入康奈爾大學Operation Research以及Information Engineering的助理教授,之前在卡內基梅隆大學擔任研究員,師從Eric Xing和Alex Smola教授,在之前,其在University of Cambridge的Zoubin Ghahramani手下攻讀博士學位。
這篇文章主要研究Word Embedding,其核心思想是想用Gaussian Mixture Model表示每一個Word的Embedding。最早的自然語言處理(NLP)是採用了One-Hot-Encoding的Bag of Word的形式來處理每個字。這樣的形式自然是無法抓住文字之間的語義和更多有價值的資訊。那麼,之前Word2Vec的想法則是學習一個每個Word的Embedding,也就是一個實數的向量,用於表示這個Word的語義。當然,如何構造這麼一個向量又如何學習這個向量成為了諸多研究的核心課題。
在ICLR 2015會議上,來自UMass的Luke Vilnis和Andrew McCallum在“Word Representations via Gaussian Embedding”文章中提出了用分佈的思想來看待這個實數向量的思想。具體說來,就是認為這個向量是某個高斯分佈的期望,然後通過學習高斯分佈的引數(也就是期望和方差)來最終學習到Word的Embedding Distribution。這一步可以說是擴充套件了Word Embedding這一思想。然而,用一個分佈來表達每一個字的最直接的缺陷則是無法表達很多字的多重意思,這也就帶來了這篇文章的想法。文章希望通過Gaussian Mixture Model的形式來學習每個Word的Embedding。也就是說,每個字的Embedding不是一個高斯分佈的期望了,而是多個高斯分佈的綜合。這樣,就給了很多Word多重意義的自由度。在有了這麼一個模型的基礎上,文章採用了類似Skip-Gram的來學習模型的引數。具體說來,文章沿用了Luke和Andrew的那篇文章所定義的一個叫Max-margin Ranking Objective的目標函式,並且採用了Expected Likelihood Kernel來作為衡量兩個分佈之間相似度的工具。這裡就不詳細展開了,有興趣的讀者可以精讀這部分細節。
文章通過UKWAC和Wackypedia資料集學習了所有的Word Embedding。所有試驗中,文章採用了K=2的Gaussian Mixture Model(文章也有K=3的結果)。比較當然有之前Luke的工作以及其他各種Embedding的方法,比較的內容有Word Similarity以及對於Polysemous的字的比較。總之,文章提出的方法非常有效果。這篇文章因為也有原始碼(基於Tensorflow),推薦有興趣的讀者精讀。
摘要:文章的核心思想,也是之前有不少人嘗試的,就是把話題模型(Topic Model)和語言模型(Language Model)相結合起來。這裡,兩種模型的處理都非常純粹,是用“地道”的深度學習語言構架完成。用到了不少流行的概念(比如GRU、Attention等),適合文字挖掘的研究人員泛讀。
文章的作者是來自於澳大利亞的研究人員。第一作者Jey Han Lau目前在澳大利亞的IBM進行Topic Model以及NLP方面的研究,之前也在第二作者Timothy Baldwin的實驗室做過研究。第二作者Timothy Baldwin和第三作者Trevor Cohn都在墨爾本大學長期從事NLP研究的教授。
這篇文章的核心思想是想徹底用Neural的思想來結合Topic Model和Language Model。當然,既然這兩種模型都是文書處理方面的核心模型,自然之前就有人曾經想過要這麼做。不過之前的不少嘗試都是要麼還想保留LDA的一些部件或者往傳統的LDA模型上去靠,要麼是並沒有和Language Model結合起來。
文章的主要賣點是完全用深度學習的“語言”來構建整個模型,並且模型中的Topic Model模型部分的結果會成為驅動Language Model部分的成分。概括說來,文章提出了一個有兩個組成部分的模型的集合(文章管這個模型叫tdlm)。
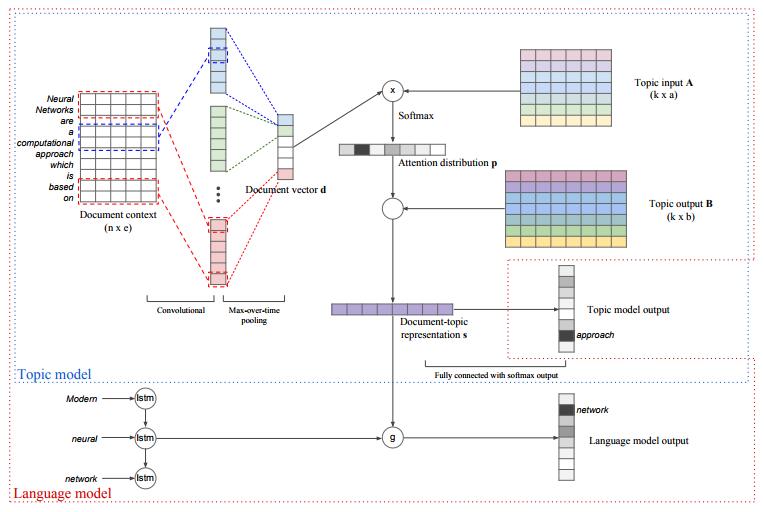
第一個部分是Topic Model的部分。我們已經提過,這裡的Topic Model和LDA已相去甚遠。思路是這樣的,首先,從一個文字表達的矩陣中(有可能就直接是傳統的Word Embedding),通過Convolutional Filters轉換成為一些文字的特徵表達(Feature Vector)。文章裡選用的是線性的轉換方式。這些Convolutional Filters都是作用在文字的一個Window上面,所以從概念上講,這一個步驟很類似Word Embedding。得到這些Feature Vector以後,作者們又使用了一個Max-Over-Time的Pooling動作(也就是每一組文字的Feature Vector中最大值),從而產生了文件的表達。注意,這裡學到的依然是比較直接的Embedding。然後,作者們定義了一組Topic的產生形式。首先,是有一個“輸入Topic矩陣”。這個矩陣和已經得到的文件特徵一起,產生一個Attention的向量。這個Attention向量再和“輸出Topic矩陣”一起作用,產生最終的文件Topic向量。這也就是這部分模型的主要部分。
最終,這個文件Topic向量通過用於預測文件中的每一個字來被學習到。有了這個文件Topic向量以後,作者們把這個資訊用在了一個基於LSTM的Language Model上面。這一部分,其實就是用了一個類似於GRU的功能,把Topic的資訊附加在Language Model上。文章在訓練的時候,採用了Joint訓練的方式,並且使用了Google釋出的Word2Vec已經Pre-trained的Word Embedding。所採用的種種引數也都在文章中有介紹。
文章在一些資料集上做了實驗。對於Topic部分來說,文章主要和LDA做比較,用了Perplexity這個傳統的測量,還比較了Topic Coherence等。總體說來,提出的模型和LDA不相上下。從Language Model的部分來說,提出的模型也在APNews、IMDB和BNC上都有不錯的Perplexity值。總體說來,這篇文章值得文字挖掘的研究者和NLP的研究者泛讀。
摘要:文章介紹如何進行端到端(End-to-End)的對話系統訓練,特別是有資料庫或者知識庫查詢步驟的時候,往往這一步“硬操作”阻止了端到端的訓練流程。這篇文章介紹了一個“軟查詢”的步驟,使得整個流程可以能夠融入訓練流程。不過從文章的結果來看,效果依然很難說能夠在實際系統中應用。可以說這篇文章有很強的學術參考價值。
文章作者群來自於微軟研究院、卡內基梅隆大學和臺灣國立大學。文章中還有Lihong Li和Li Deng(鄧力)這樣的著名學者的影子。第一作者Bhuwan Dhingra是在卡內基梅隆大學William W. Cohen和Ruslan Salakhutdinov的博士學生,兩位導師都十分有名氣。而這個學生這幾年在NLP領域可以說是收穫頗豐:在今年的ACL上已經發表2篇文章,在今年ICLR和AAAI上都有論文發表。
文章的核心思想是如何訓練一個多輪(Multi-turn)的基於知識庫(Knowledge Base)的對話系統。這個對話系統的目的主要是幫助使用者從這個知識庫中獲取一些資訊。那麼,傳統的基於知識庫的對話系統的主要弊病在於中間有一個步驟是對於“知識庫的查詢”。也就是說,系統必須根據使用者提交的查詢(Query),進行分析並且產生結果。這一步,作者們稱為“硬查詢”(Hard-Lookup)。雖然這一步非常自然,但是阻斷了(Block)了整個流程,使得整個系統沒法“端到端”(End-to-End)進行訓練。並且,這一步由於是“硬查詢”,並沒有攜帶更多的不確定資訊,不利於系統的整體優化。
這篇文章其實就是想提出一種“軟查詢”,從而讓整個系統得以“端到端”(End-to-End)進行訓練。這個新提出的“軟查詢”步驟,和強化學習(Reinforcement Learning)相結合,共同完成整個迴路,從而在這個對話系統上達到真正的“端到端”。這就是整個文章的核心思想。那麼,這個所謂的“軟查詢”是怎麼回事?其實就是整個系統保持一個對知識庫中的所有本體(Entities)所可能產生的值的一個後驗分佈(Posterior Distribution)。也就是說,作者們構建了這麼一組後驗分佈,然後可以通過對這些分佈的更新(這個過程是一個自然獲取新資料,並且更新後驗分佈的過程),來對現在所有本體的確信度有一個重新的估計。這一步的轉換,讓對話系統從和跟知識庫直接打交道,變成了如何針對後驗分佈打交道。
顯然,從機器學習的角度來說,和分佈打交道往往容易簡單很多。具體說來,系統的後驗分佈是一個關於使用者在第T輪,針對某個值是否有興趣的概率分佈。整個對話系統是這樣執行的。首先,使用者通過輸入的對話(Utterance)來觸發系統進行不同的動作(Action)。動作空間(Action Space)包含向用戶詢問某個Slot的值,或者通知使用者目前的結果。
整個系統包含三個大模組: Belief Trackers、Soft-KB Lookup,以及Policy Network。Belief Trackers的作用是對整個系統現在的狀態有一個全域性的掌握。這裡,每一個Slot都有一個Tracker,一個是根據使用者當前的輸入需要保持一個對於所有值的Multinomial分佈,另外的則是需要保持一個對於使用者是否知道這個Slot的值的置信值。文章中介紹了Hand-Crafted Tracker和Neural Belief Tracker(基於GRU)的細節,這裡就不復述了。有了Tracker以後,Soft-KB Lookup的作用是保持一個整個對於本體的所有值得後驗分佈。最後,這些後驗概率統統被總結到了一個總結向量(Summary Vector)裡。這個向量可以認為是把所有的後驗資訊給壓縮到了這個向量裡。而Policy Network則根據這個總結向量,來選擇整個對話系統的下一個動作。這裡文章也是介紹了Hand-Crafted的Policy和Neural Policy兩種情況。整個模型的訓練過程還是有困難的。
雖然作者用了REINFORCE的演算法,但是,作者們發現根據隨機初始化的演算法沒法得到想要的效果。於是作者們採用了所謂的Imitation Learning方法,也就是說,最開始的時候去模擬Hand-Crafted Agents的效果。
在這篇文章裡,作者們採用了模擬器(Simulator)的衡量方式。具體說來,就是通過與一個模擬器進行對話從而訓練基於強化學習的對話系統。作者們用了MovieKB來做資料集。總體說來整個實驗部分都顯得比較“弱”。沒有充足的真正的實驗結果。整個文章真正值得借鑑主要是“軟查詢”的思想,整個流程也值得參考。但是訓練的困難可能使得這個系統作為一個可以更加擴充套件的系統的價值不高。本文值得對對話系統有研究的人泛讀。
摘要:這篇文章主要介紹如何在LSTM的基礎上加入跳轉機制,使得模型能夠去略過不重要的部分,而重視重要的部分。模型的訓練利用了強化學習。這篇文章建議對文書處理有興趣的讀者精讀。
作者群來自Google。第一作者來自卡內基梅隆大學的Adams Wei Yu在Google實習的時候做的工作。第三作者Quoc V. Le曾是Alex Smola和Andrew Ng的高徒,在Google工作期間有很多著名的工作,比如Sequence to Sequence Model來做機器翻譯(Machine Translation)等。
文章想要解決的問題為“Skim Text”。簡單說來,就是在文書處理的時候,略過不重要的部分,對重要的部分進行記憶和閱讀。要教會模型知道在哪裡需要略過不讀,哪裡需要重新開始閱讀的能力。略過閱讀的另外一個好處則是對文字整體的處理速度明顯提高,而且很有可能還會帶來質量上的提升(因為處理的噪聲資訊少了、垃圾資訊少了)。
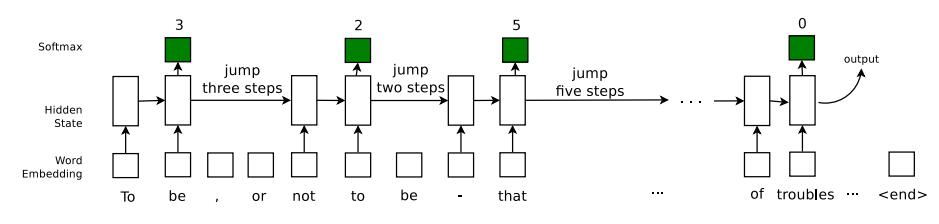
具體說來,文章是希望在LSTM的基礎上加入“跳轉”功能,從而使得這個時序模型能夠有能力判讀是否要略過一部分文字資訊。簡單說來,作者們是這麼對LSTM進行改進的。首先,有一個引數R來確定要讀多少文字。然後模型從一個0到K的基於Multinomial分佈的這一個跳轉機制中決定當前需要往後跳多少文字(可以是0,也就是說不跳轉)。這個是否跳轉的這一個步驟所需要的Multinomial分佈,則也要基於當期LSTM的隱引數資訊(Hidden State)。跳轉決定以後,根據這個跳轉資訊,模型會看一下是否已經達到最大的跳轉限制N。如果沒有則往後跳轉。當所有的這些步驟都走完,達到一個序列(往往是一個句子)結尾的時候,最後的隱引數資訊會用來對最終需要的目標(比如分類標籤)進行預測。
文章的另一個創新點,就是引入了強化學習(Reinforcement Learning)到模型的訓練中。最終從隱引數到目標標籤(Label)的這一步往往採用的是Cross Entropy的優化目標函式。這一個選擇很直觀,也是一個標準的步驟。然而,如何訓練跳轉的Multinomial分佈,因為其離散(Discrete)特質,則成為文章的難點。原因是Cross Entropy無法直接應用到離散資料上。那麼,這篇文章採取的思路是把這個問題構造成為強化學習的例子,從而使用最近的一些強化學習思路來把這個離散資訊轉化為連續資訊。具體說來,就是採用了Policy Gradient的辦法,在每次跳轉正確的時候,得到一個為+1的反饋,反之則是-1。這樣就把問題轉換成為了學習跳轉策略的強化學習模式。文章採用了REINFORCE的演算法來對這裡的離散資訊做處理。從而把Policy Gradient的計算轉換為了一個近似逼近。這樣,最終的目標函式來自於三個部分:第一部分是Cross Entropy,第二部分是Policy Gradient的逼近,第三部分則是一個Variance Reduction的控制項(為了優化更加有效)。整個目標函式就可以完整得被優化了。
文章在好多種實驗型別上做了實驗,主要比較的就是沒有跳轉資訊的標準的LSTM。其實總體上來說,很多工(Task)依然比較機械和人工。比如最後的用一堆句子,來預測中間可能會出現的某個詞的情況,這樣的任務其實並不是很現實。但是,文章中提到了一個人工(Synthetic)的任務還蠻有意思,那就是從一個數組中,根據下標為0的數作為提示來跳轉取得相應的數作為輸出這麼一個任務。這個任務充分地展示了LSTM這類模型,以及文章提出的模型的魅力:第一,可以非常好的處理這樣的非線性時序資訊,第二,文章提出的模型比普通的LSTM快不少,並且準確度也提升很多。
總體說來,這篇文章非常值得對時序模型有興趣的讀者精讀。文章的“Related Work”部分也很精彩,對相關研究有興趣的朋友可以參考這部分看看最近都有哪些工作很類似。
摘要:這篇文章要解決的問題是如何從一段文字翻譯成為“程式”的問題,文章適合對Neural Programming有興趣的讀者泛讀。
作者群來自斯坦福大學。主要作者來自Percy Liang的實驗室。最近幾年Percy Liang的實驗室可以說收穫頗豐,特別是在自然語言處理和深度學習的結合上都有不錯的顯著成果。
這篇文章裡有好一些值得關注的內容。首先從總體上來說,這篇文章要解決的問題是如何從一段文字翻譯成為“程式”的問題,可以說是一個很有價值的問題。如果這個問題能夠可以容易解決,那麼我們就可以教會計算機編寫很多程式,而不一定需要知道程式語言的細微的很多東西。從細節上說,這個問題就是給定一個輸入的語句,一個模型需要把目前的狀態轉移到下一個目標狀態上。難點在於,對於同一個輸入語句,從當前的狀態到可能會到達多種目標狀態。這些目標狀態都有可能是對當前輸入語句的一種描述。但是正確的描述其實是非常有限的,甚至是唯一的。那麼,如何從所有的描述中,剝離開不正確的,找到唯一的或者少量的正確描述,就成為了這麼一個問題的核心。
文章中採用了一種Neural Encoder-Decoder模型架構。這種模型主要是對序列資訊能夠有比較好的效果。具體說來,是對於現在的輸入語句,首先把輸入語句變換成為一個語句向量,然後根據之前已經產生的程式狀態,以及當前的語句向量,產生現在的程式狀態。在這個整個的過程中,對於Encoder作者們採用了LSTM的架構,而對於Decoder作者們採用了普通的Feed-forward Network(原因文章中是為了簡化)。
另外一個比較有創新的地方就是作者們把過於已經產生程式狀態重新Embedding化(作者們說是叫Stack)。這有一點模仿普通資料結構的意思。那麼,這個模型架構應該是比較經典的。文章這時候引出了另外一個本文的主要貢獻,那就是對模型學習的流程進行了改進。為了引出模型學習的改進,作者們首先討論了兩種學習訓練模式的形式,那就是強化學習(Reinforcement Learning)以及MML(Maximum Marginal Likelihood)的目標函式的異同。文章中提出兩者非常類似,不過比較小的區別造成了MML可以更加容易避開錯誤程式這一結果。文章又比較了基於REINFORCE演算法的強化學習以及基於Numerical Integration以及Beam Search的MML學習的優劣。總體說來,REINFORCE演算法對於這個應用來說非常容易陷入初始狀態就不太優並且也很難Explore出來的情況。MML稍微好一些,但依然有類似問題。文章這裡提出了Randomized Beam Search來解決。也就是說在做Beam Search的時候加入一些Exploration的成分。另外一個情況則是在做Gradient Updates的時候,當前的狀態會對Gradient有影響,也就是說,如果當前狀態差強人意,Gradient也許就無法調整到應該的情況。這裡,作者們提出了一種叫Beta-Meritocratic的Gradient更新法則,來解決當前狀態過於影響Gradient的情況。
實驗的部分還是比較有說服力的,詳細的模型引數也一應俱全。對於提出的模型來說,在三個資料集上都有不錯的表現。當然,從準確度上來說,這種從文字翻譯到程式狀態的任務離真正的實際應用還有一段距離。這篇文章適合對於最近所謂的Neural Programming有興趣的讀者泛讀。對怎麼改進強化學習或者MML有興趣的讀者精讀。文章的“Related Work”部分也是非常詳盡,有很多工作值得參考。
相關推薦
ACL 2017自然語言處理精選論文
作者簡介:洪亮劼,Etsy資料科學主管,前雅虎研究院高階經理。長期從事推薦系統、機器學習和人工智慧的研究工作,在國際頂級會議上發表論文20餘篇,長期擔任多個國際著名會議及期刊的評審委員會成員和審稿人。 責編:何永燦([email protected]) 本文為《
論文 | 自然語言處理頂會ACL 2018該關注什麼?螞蟻金服專家告訴你!
from:https://www.sohu.com/a/244543352_99940985 一年一度的ACL大會今年7月15日至20日在澳大利亞墨爾本召開。作為自然語言處理的頂級會議,雖然遠在澳洲召開,也吸引了1500位從全球各地趕來的專業人員參會。螞蟻金服派出了數位技術專家代表公司前去參會,
自然語言處理組2017論文研讀1:ME-MD:一個有效的神經系統框架
ME-MD:一個有效的神經系統框架具有多個編碼器和解碼器的機器翻譯Jinchao Zhang1 Qun Liu3,1 Jie Zhou2 1Key Laboratory of IntelligentInformation Processing, Institute of Co
自然語言處理領域重要論文&資源全索引
自然語言處理(NLP)是人工智慧研究中極具挑戰的一個分支。隨著深度學習等技術的引入,NLP 領域正在以前所未有的速度向前發展。但對於初學者來說,這一領域目前有哪些研究和資源是必讀的?最近,Kyubyong Park 為我們整理了一份完整列表。 GitHub 專案連結:https:/
2018年自然語言處理最值得關注的研究、論文和程式碼
2018年對於自然語言處理(NPL)是很有意義的一年,見證了許多新的研究方向和尖端成果。Elvis Saravia 是計算語言學專家,也是2019 計算語言學會年度大會北美分部的專案委員之一。他總結了2018年 NLP 的重要進展,包括增強學習、情感分析和深度學習等領域。點選文章中的連結,可獲得每一項研究的詳
自然語言處理頂會 ACL 2018 參會見聞
關於作者:鄭在翔,現為南京大學自然語言處理實驗室二年級碩士生,將準備繼續攻讀自然語言處理方向的博士。當前主要研究方向為神經網路機器翻譯。 作者在本文記錄了自己在自然語言處理頂會 ACL 2018 的參會經歷,從個人的角度出發,介紹了會議內外的內容、感興趣的工作
自然語言處理中的Attention Model:是什麽及為什麽
機器 逆序 mar 回來 是什麽 all 意義 及其 creation /* 版權聲明:可以任意轉載,轉載時請標明文章原始出處和作者信息 .*/ author: 張俊
gensim自然語言處理
encode content for 服務 讀取 htm all mat 自然語言 最近在做詞語的相似度做比較,就選用了gensim 首先要安裝gensim庫,此處省略,參看官網http://radimrehurek.com/gensim/install.html 在網上下
NLP系列(1)_從破譯外星人文字淺談自然語言處理的基礎
應用 展現 發現 func 文本 詞幹 pos 中文分詞 漢語 作者:龍心塵 &&寒小陽 時間:2016年1月。 出處: http://blog.csdn.net/longxinchen_ml/article/details/505
文本情感分析的基礎在於自然語言處理、情感詞典、機器學習方法等內容。以下是我總結的一些資源。
建議 中心 這場 分詞 自然語言處理 目前 能力開放 計算 推薦算法 文本情感分析的基礎在於自然語言處理、情感詞典、機器學習方法等內容。以下是我總結的一些資源。 詞典資源:SentiWordNet《知網》中文版中文情感極性詞典 NTUSD情感詞匯本體下載 自然語言處理
自然語言處理哪家強?
的語音 科學 點對點 亞馬遜 消息 合作 夢幻 項目 找到 自然語言處理哪家強? 摘要:語音交互事關未來,這點從大公司收購、投資、合作不斷,就可見一斑。如蘋果收購Siri、Novauris、Google收購多項語音識別技術專利、Facebook收購Wit.ai等、Ama
2017MySQL中文索引解決辦法 自然語言處理(N-gram parser)
ray spa 全文索引 rom alt lte int 中文索引 ble 問題:長期以來MYSQL搜索對於中文來說不太理想,InnoDB引擎對FULLTEXT索引的支持是MySQL5.6新引入的特性,但是用“初級”一詞在“我是一名初
(zhuan) 自然語言處理中的Attention Model:是什麽及為什麽
機器 pri 概念 max page acf 集中 use tps 自然語言處理中的Attention Model:是什麽及為什麽 2017-07-13 張俊林 待字閨中 要是關註深度學習在自然語言處理方面的研究進展,我相信你一定聽說過Attention Model(
95、自然語言處理svd詞向量
atp ear logs plt images svd分解 range src for import numpy as np import matplotlib.pyplot as plt la = np.linalg words = ["I","like","enjoy
NLP-python 自然語言處理01
count ems odin 頻率分布 str sep mon location don 1 # -*- coding: utf-8 -*- 2 """ 3 Created on Wed Sep 6 22:21:09 2017 4 5 @author: A
cs224d 自然語言處理作業 problem set3 (一) 實現Recursive Nerual Net Work 遞歸神經網絡
函數 rec 合並 聯系 cs224 作業 itl clas 自然語言處理 1、Recursive Nerual Networks能夠更好地體現每個詞與詞之間語法上的聯系這裏我們選取的損失函數仍然是交叉熵函數 2、整個網絡的結構如下圖所示: 每個參數的更新時的梯隊值如何計算
自然語言處理怎麽最快入門?
改進 一個 問答系統 好的 必須 開源 都在 程序 得出 自然語言處理(簡稱NLP),是研究計算機處理人類語言的一門技術,包括: 1.句法語義分析:對於給定的句子,進行分詞、詞性標記、命名實體識別和鏈接、句法分析、語義角色識別和多義詞消歧。 2.信息抽取:從給定文本中抽
Python自然語言處理1
cmd 輸入 函數調用 down load src 選擇 分享 cnblogs 首先,進入cmd 輸入pip install的路徑 隨後開始下載nltk的包 一、準備工作 1、下載nltk 我的之前因為是已經下載好了 ,我現在用的參考書是Python自然語言處理這本書,最
數學之美讀書筆記——自然語言處理教父和他的弟子們
自然語言處理 jpg alt 自然 .cn 讀書筆記 bsp blog 處理 數學之美讀書筆記——自然語言處理教父和他的弟子們
自然語言處理隨筆(一)
索引 中國 大學 import pip for earch 清華 北京 安裝jieba中文分詞命令:pip install jieba 簡單的例子: import jiebaseg_list = jieba.cut("我來到北京清華大學", cut_all=True)pri