
閱讀筆記——基於字典學習的影象分類方法總結
題目:A Brief Summary of Dictionary Learning Based Approach for Classification
作者:Shu Kong and Donghui Wang
College of Computer Science and Technology, Zhejiang University
時間:May 31, 2012
一、整體介紹
1、最初學習得到的字典進用於訊號重構,後來,研究者們採取措施通過研究標籤資訊以監督學習方式學習用於分類的字典。
2、已經存在的基於DL的分類方法大致分為兩類:一類是直接學習具有識別力的字典,另一類是稀疏化稀疏,是字典具有識別力。 第一類主要利用表示誤差進行分類判決,第二類主要利用稀疏稀疏作為新的特徵進行分類。
SRC基本模型:
1、對x進行編碼,對係數加l1範數約束,取最小值。
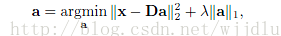
2、對x進行分類判決。
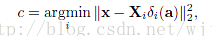
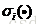
SRC對亮度和遮擋等噪聲具有很強的魯棒性。
傳統字典學習框架:
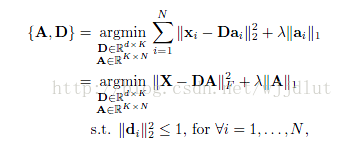
其中,共N個訊號。A=[a1,a2,...,aN]是編碼係數矩陣。矩陣A的1範數等價於A的各個列向量的1範數之和。
SRC的缺點:
(1)預定字典包含冗餘和瑣碎的不利於人臉識別的資訊;
(2)訓練資料增加,稀疏編碼的計算量增加。
二、直接學習具有識別力的字典
為解決以上問題:
直接學習具有識別力的字典:
1、Meta-Face Learning
Yang等人的該方法是針對每一個類別學習得到一個自適應的字典。
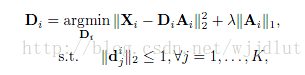
其中矩陣Xi包含第i個類別的所有樣本,Di是第i個類別對應的字典。
2、Dictionary Learning with Structured Incoherence(DLSI)
不同類別的子字典的原子具有連貫性,則重構查詢影象時的原子是可以互相代替的。這導致無法利用重構誤差進行分類判決。為了解決這一問題,Ramirez等人增加了一個不連貫項的約束,使不同類別的子字典之間儘可能互相獨立。
不連貫項:
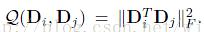
最終的字典學習演算法為:
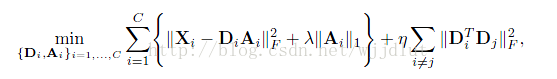
不連貫項的含義是:在重構誤差時,忽略與公共原子(在各個類別中表示共同特徵的原子)相關的係數的絕對值,一次提高系統的判決能力。
三、使係數具有識別力的方法
該類方法使稀疏係數具有識別力,間接使字典具有識別力。該類方法只需要學習一個整體的字典,不需要每個類別都學習一個相應的字典。
1、監督字典學習(SDL)
Mairal等人提出將邏輯迴歸與傳統字典學習框架相結合。
優化公式為:
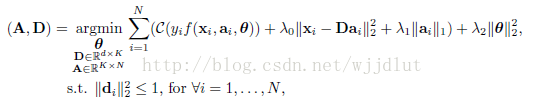
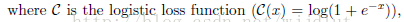
λ2 是防止過擬合的正則項引數。f是與係數a呈線性關係的函式:

或者與a和x成雙線性關係的函式:
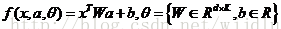
2、用於字典學習的有識別力的K-SVD方法(D-KSVD)
D-KSVD在傳統DL框架上加了一個簡單的線性迴歸作為懲罰項。
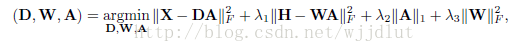
H=[h1,h2,...hN]是訓練影象的標籤。hn =[0,...0,1,0,...,0],非零元素的位置即為所屬的類別。W是分類器的引數。
由上式可知,前兩項可以混合為一項,最後一下根據KSVD可以去掉。最終優化得到D和W後,即可迅速對查詢影象進行分類。
3、標籤一致的KSVD(LC-KSVD)
Jiang等人提出LC-KSVD,提出了一個叫做“有識別力的稀疏編碼誤差”的標籤一致的約束,與重構誤差和分類誤差結合,如下所示:


具有識別力的稀疏編碼誤差使得稀疏碼A接近有識別力的稀疏編碼Q。
4、Fisher 判決字典學習方法
總的優化函式框架:

C(X,D,A):識別精確項。
f(A):強加於A的識別力約束項。
在識別力精確項:我們希望DiAi=Xi,DjAi=0(i不等於j)。
於是:
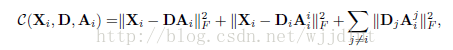
在係數的識別力約束項:使關於樣本X的字典D有識別力,可以使編碼A有識別力。即使A的類內散度SW小,類間散度SB大。
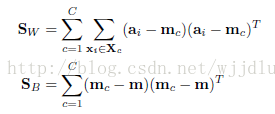
Fisher判決函式為:(tr(SW)-tr(SB)是非凸函式且不穩定,加上一項A的F範數項),如下所示:

所有內容融合之後,得到的FDDL為:

四、總結
字典學習的總體框架:
相關推薦
閱讀筆記——基於字典學習的影象分類方法總結
題目:A Brief Summary of Dictionary Learning Based Approach for Classification 作者:Shu Kong and Donghui Wang College of Computer Science and
基於圖的影象分割方法(Graph-Based Image Segmentation)原始碼閱讀筆記
這個方法被應用於深度學習目標檢測的經典之作selective search方法中(Selective Search for Object Recognition),用於初始化分割區域。。論文題目:《Efficient Graph-Based Image Segm
學習筆記之——基於深度學習的分類網路
之前博文介紹了基於深度學習的常用的檢測網路《學習筆記之——基於深度學習的目標檢測演算法》,本博文為常用的CNN分類卷積網路介紹,本博文的主要內容來自於R&C團隊的成員的調研報告以及本人的理解~如有不當之處,還請各位看客賜教哈~好,下面
機器學習實戰筆記——基於SVD的影象壓縮
原始影象大小為32 X 32=1024畫素,利用SVD來對資料降維,實現影象的壓縮 新建一個svdRec.py檔案,加入如下程式碼: #printMat()函式用於列印矩陣 def printMat(inMat, thresh=0.8): for
基於字典學習的影象去噪研究與實踐
機器學習在影象處理中有非常多的應用,運用機器學習(包括現在非常流行的深度學習)技術,很多傳統的影象處理問題都會取得相當不錯的效果。今天我們就以機器學習中的字典學習(Dictionary Learning)為例,來展示其在影象去噪方面的應用。文中程式碼採用Python寫成,其中
影象特徵學習與分類方法研究
基於深度學習的影象特徵學習和分類方法的研究及應用 華南理工 馮子勇 研究現狀: 1. 單層特徵編碼 2. 深度學習 深度玻爾茲曼機 卷積神經網路 Ioffe 和 Szegedy提出了塊歸一化(Batch Normal
inceptionv3 /v4遷移學習影象分類
研究一個影象分類的任務,現在的問題是對6類影象資料做分類任務,資料的特徵是每一類都只有非常少的資料,並且存在類別不平均,在這種情況下我們的實驗結果存在準確率的問題,對於少量資料,採用端到端從頭開始訓練的方法,模型學習到的特徵很少,泛化能力不夠,採用從ImageNet資料集訓練得到的結果,我們可以採用
《影象處理、分析與機器視覺》(第4版)閱讀筆記——第四章 影象分析的資料結構
4.1 影象資料表示的層次 共分為四個層次: 最底層的表示:圖示影象(iconic images),由含有原始資料的影象組成,原始資料也就是畫素亮度資料的整數矩陣。(預處理的部分) 第二層的表示:分割影象(segmented images)。 第三層:幾何表示(geo
深度學習影象分類(一)——AlexNet論文理解
0. 寫作目的 好記性不如爛筆頭。 1. 論文理解 1.1 ReLU 啟用函式的使用 Rectified Linear Units(ReLU) 使用ReLU比使用tanh(或者sigmoid)啟用函式收斂速度更快。下圖來自AlexNet論文中給出的在CIFAR-10
無監督深度學習影象分類思路
分類方法:(一)波普圖形識別分類(二)聚類分析: 1.動態聚類。聚類的方法主要有基於最鄰近規則的試探法、K-means均值演算法、迭代自組織的資料分析法(ISODATA)等。 2.模糊聚類法。模糊分類根據是否需要先驗知識也可以分為監督分類和非監督分類.。 3.系統聚類。這種方法是將影像中每個
基於字典的影象超解析度實現
簡介 這段時間在看基於字典的單幀影象超解析度重建,本篇主要是對這塊做個筆記記錄。 基本原理 預處理 1、準備好用於字典訓練的低解析度影象LR及與之對應的高解析度圖片HR。 2、將低解析度影象雙線性或者三次方插值到高解析度影象相同大小,得到MR
臺大林軒田機器學習課程筆記2----機器學習的分類
1. 根據輸出集合 二分類 根據輸出空間,二分類的輸出結果只有兩種,即y={-1,1},具體的應用包括: *信用卡申請問題:Client Data=>Accept or Deny 郵件分類問題:Email Text=>Rubbish or Not 病人生病問
tensorflow實現基於LSTM的文字分類方法
引言 學習一段時間的tensor flow之後,想找個專案試試手,然後想起了之前在看Theano教程中的一個文字分類的例項,這個星期就用tensorflow實現了一下,感覺和之前使用的theano還是有很大的區別,有必要總結mark一下 模型說明 這個
2017CS231n李飛飛深度視覺識別筆記(二)——影象分類
第二章 影象分類課時1 資料驅動方法 在上一章的內容,我們提到了關於影象分類的任務,這是一個計算機視覺中真正核心的任務,同時也是本課程中關注的重點。 當做影象分類時,分類系統接收一些輸入影象
《影象處理、分析與機器視覺》(第4版)閱讀筆記——第五章 影象預處理
預處理不會增加影象的資訊量,一般會降低熵。因此,從資訊理論的角度看,最好的預處理是沒有預處理:避免(消除)預處理的最好途徑是著力於高質量的影象獲取。實際影象中的屬於一個物體的相鄰畫素通常具有相同的或類似的亮度值,因此如果一個失真了的畫素可以從影象中被挑出來,它也許就可以用其鄰接畫素的平均值來複原。
《影象處理、分析與機器視覺》(第4版)閱讀筆記——第三章 影象及其數學與物理背景
3.1 概述 3.1.1 線性 向量(線性)空間(vector(linear) space) 3.1.2 狄拉克(Dirac)分佈和卷積 理想的衝擊是一個重要的輸入訊號,影象平面上的理想衝擊是用狄拉克分佈(Dirac distribution)定義的,。相當於訊號處理中的單位階躍函式
計算機視覺-論文閱讀筆記-基於高效能檢測器與表觀特徵的多目標跟蹤
這篇筆記主要是對今年ECCV2016上的論文:POI:Multiple Object Tracking with High Performance Detection and Appearance Feature 進行整理. 這篇文章的基本思路是在每幀上用檢測器
資料探勘學習------------------4-分類方法-4-神經網路(ANN)
4.4神經網路 它是一種應用類似於大腦神經突觸聯接的結構進行資訊處理的數學模型。 神經網路通常需要訓練,訓練的過程就是網路進行學習的過程。訓練改變了網路節點的連線權的值使其具有分類的功能,經過訓練的網路就可用於物件的識別。 1、感知器 由圖可知:①幾個輸入結點,用來表示輸
深度學習影象分類技術最近進展(以面板癌影象分類為例)
最近在看影象分類方面的技術,看了之前大家做面板癌分類時用到的一些方法和網路結構,覺得很有啟發。 讀了一些文獻,看過後就知道大家用的套路都差不多,但很好用。 讀文獻的過程中做了些筆記,記的都是我認為可以借鑑的點。 和大家分享下我的筆記內容吧,可能字寫的不是很好看不大清,對
文字資料的機器學習自動分類方法
來源:http://blog.csdn.net/jdbc/article/details/50586042 本文為第一部分,著重介紹文字預處理以及特徵抽取的方法。 隨著網際網路技術的迅速發展與普及,如何對浩如煙海的資料進行分類、組織和管理,已經成為一個具有重要用途