
資料結構--並查集的原理及實現
一,並查集的介紹
並查集(Union/Find)從名字可以看出,主要涉及兩種基本操作:合併和查詢。這說明,初始時並查集中的元素是不相交的,經過一系列的基本操作(Union),最終合併成一個大的集合。
而在某次合併之後,有一種合理的需求:某兩個元素是否已經處在同一個集合中了?因此就需要Find操作。
並查集是一種 不相交集合 的資料結構,設有一個動態集合S={s1,s2,s3,.....sn},每個集合通過一個代表來標識,代表 就是動態集合S 中的某個元素。
比如,若某個元素 x 是否在集合 s1 中(Find操作),返回集合 s1 的代表元素即可。這樣,判斷兩個元素是否在同一個集合中也是很方便的,只要看find(x) 和 find(y) 是否返回同一個代表即可。
為什麼是動態集合S呢?因為隨著Union操作,動態集合S中的子集合個數越來越少。
資料結構的基本操作決定了它的應用範圍,對並查集而言,一個簡單的應用就是判斷無向圖的連通分量個數,或者判斷無向圖中任何兩個頂點是否連通。
二,並查集的儲存結構及實現分析
①儲存結構
並查集(大S)由若干子集合si構成,並查集的邏輯結構就是一個森林。si表示森林中的一棵子樹。一般以子樹的根作為該子樹的代表。
而對於並查集的儲存結構,可用一維陣列和連結串列來實現。這裡主要介紹一維陣列的實現。
根據前面介紹的基本操作再加上儲存結構,並查集類的實現架構如下:
public class DisjSets {private int[] s; private int count;//記錄並查集中子集合的個數(子樹的個數) public DisjSets(int numElements) { //建構函式,負責初始化並查集 } public void unionByHeight(int root1, int root2){ //union操作 } public int find(int x){ //find 操作 } }
由於Find操作需要找到該子集合的代表元素,而代表元素是樹根,因此需要儲存樹中結點的父親,對於每一個結點,如果知道了父親,沿著父結點鏈就可以最終找到樹根。
為了簡單起見,假設一維陣列s中的每個元素 s[i] 表示該元素 i 的父親。這裡有兩個需要注意的地方:①我們用一維陣列來儲存並查集,陣列的元素s[i]表示的是結點的父親的位置。②陣列元素的下標 i 則是結點的標識。如:s[5]=4,表示:結點5 的父親 是結點4。
假設有並查集中6個元素,初始時,所有的元素都相互獨立,處在不同的集合中:

對應的一維陣列初始化如下:

因為,初始時每個元素代表一個集合,該元素本身就是樹根。樹根的父結點用 -1 來表示。程式碼實現如下:
1 public DisjSets(int numElements) { 2 s = new int[numElements]; 3 count = numElements; 4 //初始化並查集,相當於新建了s.length 個互不相交的集合 5 for(int i = 0; i < s.length; i++) 6 s[i] = -1;//s[i]儲存的是高度(秩)資訊 7 }
②基本操作實現
Union操作就是將兩個不相交的子集合合併成一個大集合。簡單的Union操作是非常容易實現的,因為只需要把一棵子樹的根結點指向另一棵子樹即可完成合並。
比如合併 節點3 和節點4:
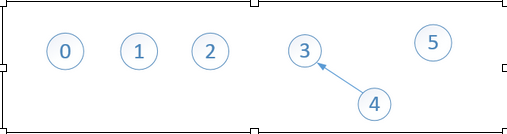
這裡的合併很隨意,把任意一棵子樹的結點指向另一棵子樹結點就完成了合併。
1 public void union(int root1, int root2){ 2 s[root2] = root1;//將root1作為root2的新樹根 3 }
但是,這只是一個簡單的情況,如果待合併的兩棵子樹很大,而且高度不一樣時,如何使得合併操作生成的新的子樹的高度最小?因為高度越小的子樹Find操作越快。
後面會介紹一種更好的合併策略,以支援Quick Union/Find。
Find操作就是查詢某個元素所在的集合,返回該集合的代表元素。在union(3,4) 和 union(1,2)後,並查集如下:
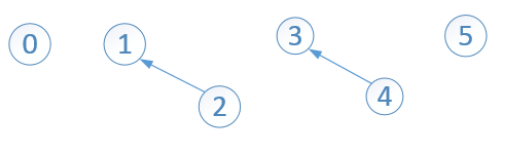
此時的一維陣列如下:

此時一共有4個子集合。第一個集合的代表元素為0,第二個集合的代表元素為1,第三個集合的代表元素為3,第四個集合的代表元素為5,故:
find(2)返回1,find(0)返回0。因為 結點3 和 結點4 在同一個集合內,find(4)返回3,find(3)返回3。
1 public int find(int x){ 2 if(s[x] < 0) 3 return x; 4 else 5 return find(s[x]); 6 }
這裡find(int x)返回的是最裡層遞迴執行後,得到的值。由於只有樹根的父結點位置小於0,故返回的是樹根結點的標識。
(陣列中索引 i 處的元素 s[i] 小於0,表示 結點i 是根結點.....)
Union/Find的改進----Quick Union/Find
上面介紹的Union操作很隨意:任選一棵子樹,將另一棵子樹的根指向它即完成了合併。如果一直按照上述方式合併,很可能產生一棵非常不平衡的子樹。
比如在上面的基礎上union(2,3)後
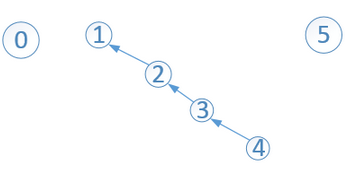
樹越來越高了,此時會影響到Find操作的效率。比如,find(4)時,會一直沿著父結點遍歷直到根,4-->3-->2-->1
這裡引入一種新的合併策略,這是一種啟發式策略,稱之為按秩合併:將秩小的子樹的根指向秩大的子樹的根。
秩的定義:對每個結點,用秩表示結點高度的一個上界。為什麼是上界?
因為路徑壓縮不完全與按高度求併兼容。路徑壓縮會改變樹的高度,這樣在Union操作之前,我們就無法獲得子樹的高度的精確值,因此就不計算高度的精確值,而是儲存每棵樹的高度的估計值,這個值稱之為秩。(關於路徑壓縮在後面的Find操作中會詳細介紹)
說了這麼多,按秩求並就是在合併之前,先判斷下哪棵子樹更高,讓矮的子樹的根指向高的子樹的根。
除了按高度求並之外,還可以按大小求並,即先判斷下哪棵子樹含有的結點數目多,讓較小的子樹的根指向較大的子樹的根。
對於按高度求並,需要解釋下陣列中儲存的元素:是高度的負值再減去1。這樣,初始時,所有元素都是-1,而樹根節點的高度為0,s[i]=-1。
按高度求並的程式碼如下:
1 /** 2 * 3 * @param root1 並查集中以root1為代表的某個子集 4 * @param roo2 並查集中以root2為代表的某個子集 5 * 按高度(秩)合併以root1 和 root2為代表的兩個集合 6 */ 7 public void unionByHeight(int root1, int root2){ 8 if(find(root1) == find(root2)) 9 return;//root1 與 root2已經連通了 10 11 if(s[root2] < s[root1])//root2 is deeper 12 s[root1] = root2; 13 else{ 14 if(s[root1] == s[root2])//root1 and root2 is the same deeper 15 s[root1]--;//將root1的高度加1 16 s[root2] = root1;//將root2的根(指向)更新為root1 17 } 18 19 count--;//每union一次,子樹數目減1 20 }
使用了路徑壓縮的Find的操作
上面程式程式碼find方法只是簡單地把待查詢的元素所在的根返回。路徑壓縮是指,在find操作進行時,使find查詢路徑中的頂點(的父親)都直接指向為樹根(這很明顯地改變了子樹的高度)
如何使find查詢路徑中經過的每個頂點都直接指向樹根呢?只需要小小改動一下就可以了,這裡用到了非常神奇的遞迴。修改後的find程式碼如下:
1 public int find(int x){ 2 if(s[x] < 0)//s[x]為負數時,說明 x 為該子集合的代表(也即樹根), 且s[x]的值表示樹的高度 3 return x; 4 else 5 return s[x] = find(s[x]);//使用了路徑壓縮,讓查詢路徑上的所有頂點都指向了樹根(代表節點) 6 //return find(s[x]); 沒有使用 路徑壓縮 7 }
因為遞迴最終得到的返回值是根元素。第5行將根元素直接賦值給s[x],s[x]在每次遞迴過程中相當於結點x的父結點指標。
關於路徑壓縮對按”秩“求並的相容性問題
上面的unionByHeight(int , int)是按照兩棵樹的高度來進行合併的。但是find操作中的路徑壓縮會對樹的高度產生影響。使用了路徑壓縮後,樹的高度變化了,但是陣列並沒有更新這個變化。因為無法更新!!(我們沒有在Find操作中去計算原來的樹的高度,然後再計算新的樹的高度,這樣不現實,複雜度太大了)
舉個例子:
依次高度unionByHeight(3, 4)、unionByHeight(1, 3)、unionByHeight(1, 0)後,並查集如下:
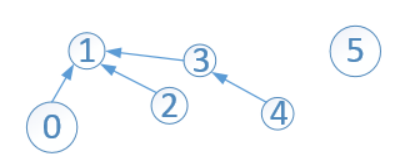
此時,陣列中的元素如下:

可以看出,此時只有兩棵子樹,一棵根結點為1,另一棵只有一個結點5。結點1的s[1]=-3,它所表示是該子樹的高度為2,如果此時執行find(4),會改變這棵樹的高度!但是,陣列s中儲存的根的高度卻沒有更新,只會更新查詢路徑上的頂點的高度。執行完find(4)後,變成:

查詢路徑為 4-->3-->1,find(4)使得查詢路徑上的所有頂點的父結點指向了根。如,將結點4 指向了根。但是沒有根結點的高度(沒有影響樹根的秩),因為s[1]的值仍為-3
-3表示的高度為2,但是樹的高度實際上已經變成了1
執行find(4)之後,樹實際上是這樣的:
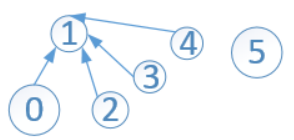
(關於路徑壓縮對按秩合併有影響,我一直有個疑問,希望有大神指點啊)。。。。
路徑壓縮改變了子樹的高度,而這個高度是按秩求的依據。,而且當高度改變之後,我們是無法更新這個變化了的高度的。那這會不會影響按秩求並的正確性?或者說使按秩求並達不到減小新生成的子樹的高度的效果?
四,並查集的應用
並查集資料結構非常簡單,基本操作也很簡單。但是用途感覺很大。比如,求解無向圖中連通分量的個數,生成迷宮……
這些應用本質上就是:初始時都是一個個不連通的物件,經過一步步處理,變成連通的了。。。。。
如迷宮,初始時,起點和終點不連通,隨機地開啟起點到終點路徑上的一個方向,直至起點和終點連通了,就生成了一個迷宮。
如,無向圖的連通分量個數,初始時,將無向圖中各個頂點視為不連通的子集合,對圖中每一條邊,相當於union這條邊對應的兩個頂點分別所在的集合,直至所有的邊都處理完後,還剩下的集合的個數即為連通分量的個數。
五,完整程式碼如下:
1 package mark_allen_weiss.c8; 2 3 public class DisjSets { 4 private int[] s; 5 private int count;//記錄並查集中子集合的個數(子樹的個數) 6 7 8 public DisjSets(int numElements) { 9 s = new int[numElements]; 10 count = numElements; 11 //初始化並查集,相當於新建了s.length 個互不相交的集合 12 for(int i = 0; i < s.length; i++) 13 s[i] = -1;//s[i]儲存的是高度(秩)資訊 14 } 15 16 /** 17 * 18 * @param root1 並查集中以root1為代表的某個子集 19 * @param roo2 並查集中以root2為代表的某個子集 20 * 按高度(秩)合併以root1 和 root2為代表的兩個集合 21 */ 22 public void unionByHeight(int root1, int root2){ 23 if(find(root1) == find(root2)) 24 return;//root1 與 root2已經連通了 25 26 if(s[root2] < s[root1])//root2 is deeper 27 s[root1] = root2; 28 else{ 29 if(s[root1] == s[root2])//root1 and root2 is the same deeper 30 s[root1]--;//將root1的高度加1 31 s[root2] = root1;//將root2的根(指向)更新為root1 32 } 33 34 count--;//每union一次,子樹數目減1 35 } 36 37 public void union(int root1, int root2){ 38 s[root2] = root1;//將root1作為root2的新樹根 39 } 40 41 42 public void unionBySize(int root1, int root2){ 43 44 if(find(root1) == find(root2)) 45 return;//root1 與 root2已經連通了 46 47 if(s[root2] < s[root1])//root2 is deeper 48 s[root1] = root2; 49 else{ 50 if(s[root1] == s[root2])//root1 and root2 is the same deeper 51 s[root1]--;//將root1的高度加1 52 s[root2] = root1;//將root2的根(指向)更新為root1 53 } 54 55 count--;//每union一次,子樹數目減1 56 } 57 58 59 public int find(int x){ 60 if(s[x] < 0)//s[x]為負數時,說明 x 為該子集合的代表(也即樹根), 且s[x]的值表示樹的高度 61 return x; 62 else 63 return s[x] = find(s[x]);//使用了路徑壓縮,讓查詢路徑上的所有頂點都指向了樹根(代表節點) 64 //return find(s[x]); 沒有使用 路徑壓縮 65 } 66 67 public int find0(int x){ 68 if(s[x] < 0) 69 return x; 70 else 71 return find0(s[x]); 72 } 73 74 75 public int size(){ 76 return count; 77 } 78 79 //for test purpose 80 public static void main(String[] args) { 81 DisjSets dSet = new DisjSets(6); 82 dSet.unionBySize(1, 2); 83 84 for(int i : dSet.s) 85 System.out.print(i + " "); 86 87 dSet.unionBySize(3, 4); 88 89 System.out.println(); 90 for(int i : dSet.s) 91 System.out.print(i + " "); 92 93 System.out.println(); 94 dSet.unionBySize(1, 3); 95 for(int i : dSet.s) 96 System.out.print(i + " "); 97 98 System.out.println(); 99 dSet.unionBySize(1, 0); 100 for(int i : dSet.s) 101 System.out.print(i + " "); 102 103 System.out.println(); 104 int x = dSet.find(4); 105 System.out.println(x); 106 107 for(int i : dSet.s) 108 System.out.print(i + " "); 109 110 System.out.println("\nsize:" + dSet.size()); 111 } 112 }
六,參考資料
http://blog.csdn.net/dm_vincent/article/details/7655764
《演算法導論》第二版
《資料結構與演算法分析》JAVA語言描述--Mark Allen Weiss
相關推薦
資料結構--並查集的原理及實現
一,並查集的介紹 並查集(Union/Find)從名字可以看出,主要涉及兩種基本操作:合併和查詢。這說明,初始時並查集中的元素是不相交的,經過一系列的基本操作(Union),最終合併成一個大的集合。 而在某次合併之後,有一種合理的需求:某兩個元素是否已經處在同一個集合中了?因此就需要Find操作。 並
並查集原理及Python實現,朋友圈個數問題
背景問題:給定一些好友的關係,求這些好友關係中,存在多少個朋友圈? 例如給定好友關係為:[0,1], [0, 4], [1, 2], [1, 3], [5, 6], [6, 7], [7, 5], [8, 9]。在這些朋友關係中,存在3個朋友圈,分別是 【0,1,2,3,
【資料結構並查集】POJ1988——線樹上的帶權並查集
問題描述: 給定30000個方塊,一開始每個方塊各自一摞,每次有兩種操作的方法,一種是將含有編號xx的一摞放在含有編號yy的一摞上,另一種是統計編號xx的方塊下有幾個方塊,每次將第二種操作的結果
資料結構-並查集
並查集 一種特殊的樹, 由子節點執行父節點 方便解決連線問題 主要操作 union(p,q) 用於合併p, q所在的集合 isConnected(p,q) 判斷p,q是否相連 程式碼實現 首先先定義並查集的介面, 介面定義如下: package tr
資料結構——並查集Union Find
一、並查集解決了什麼問題? 1、網路中節點間的連線狀態:這裡的網路是一個抽象的概念,指的是使用者之間形成的網路 2、兩個或兩個以上集合之間的交集 二、對並查集的設計 對於一組資料,主要支援兩個操作 public interface UnionFind {
資料結構——並查集
等價關係:滿足自反,對稱,傳遞。 等價類:指相互等價的元素的最大集合。一個元素只能屬於一個等價類。 離線等價類問題中,已知n和R,確定所有的等價類。 線上等價類問題中,初始時有n個元素,每個元素都屬於一個獨立的等價類。 find(element)返回所屬的等價類。union
資料結構----並查集Java
並查集:(union-find sets)是一種簡單的用途廣泛的集合. 並查集是若干個不相交集合,能夠實現較快的合併和判斷元素所在集合的操作,應用很多。 應用場景: 網路連線判斷: 如果每個pair中的兩個整數分別代表一個網路節點,那麼該pair就是
POJ 1182 食物鏈 [資料結構-並查集 union-find sets]
在輸入時可以先判斷題目所說的條件2和3,即: 1>若(x>n||y>n):即當前的話中x或y比n大,則假話數目num加1. 2>若(x==2&&x==y):即當前的話表示x吃x,則假話數目num加1. 而不屬於這兩種情況外的話語要利用
ACM-資料結構-並查集
ACM競賽中,並查集(DisjointSets)這個資料結構經常使用。顧名思義,並查集即表示集合,並且支援快速查詢、合併操作。 並查集如何表示一個集合?它藉助樹的思想,將一個集合看成一棵有根樹。那又如何表示一棵樹?初始狀態下,一個元素即一棵樹,根即是元素本身。 並查集如何
2019.9.17 初級資料結構——並查集及其應用
一、並查集基礎 (一)引入 我們先來看一個問題。 某學校有N個學生,形成M個俱樂部。每個俱樂部裡的學生有著一定相似的興趣愛好,形成一個朋友圈。一個學生可以同時屬於若干個不同的俱樂部。根據“我的朋友的朋友也是我的朋友”這個推論可以得出,如果A和B是朋友,且B和C是朋友,則A和C也是
數據結構 並查集
一個 efault mar left pts turn 一個數 baseline 數組 並查集是一種數據結構,字面意思上來說,就是一個支持合並和查詢的集合。 並查集 並查集的建立 1 void init() 2 { 3 for (int i = 1; i <
NOI2018歸程(Kruskal重構樹)(以及騙分數據結構並查集)
沒有 這一 目標 div 相對 之前 大寫字母 top color 題目描述 本題的故事發生在魔力之都,在這裏我們將為你介紹一些必要的設定。 魔力之都可以抽象成一個 n 個節點、m 條邊的無向連通圖(節點的編號從 1 至 n)。 我們依次用 l,a 描述一條邊的長度、海拔
資料正規化 (data normalization) 的原理及實現 (Python sklearn)
原理 資料正規化(data normalization)是將資料的每個樣本(向量)變換為單位範數的向量,各樣本之間是相互獨立的.其實際上,是對向量中的每個分量值除以正規化因子.常用的正規化因子有 L1, L2 和 Max.假設,對長度為 n 的向量,其正規化因子 z 的計算公式,如下所示:
演算法之並查集 C語言實現3
標頭檔案 UnionFind3.h #ifndef UNIONFIND3_H_INCLUDED #define UNIONFIND3_H_INCLUDED #include "stdlib.h" #include "ASSERT.h" typedef stru
資料結構(三)——佇列及實現、迴圈佇列實現
一、佇列 佇列是一種特殊的線性表,它只允許在表的前端(front)進行刪除操作,而在表的後端(rear)進行插入操作。進行插入操作的端稱為隊尾,進行刪除操作的端稱為隊頭。佇列中沒有元素時,稱為空佇
並查集的樹形實現(C++)(轉載)
摘要:本文介紹了通用並查集的樹形實現,通過壓縮路徑和維持數的平衡,可以保證 查詢和合並的平均時間複雜度為O(1)! 關鍵字:並查集,UnionFind,樹形 並查集基本知識參見博文《並查集的陣列實現》。在並查集的樹形實現中,使用樹狀結構來組織一個 集合,多個集合之
資料結構--二項佇列分析及實現
一,介紹 什麼是二項佇列,為什麼會用到二項佇列? 與二叉堆一樣,二項佇列也是優先順序佇列的一種實現方式。在 資料結構--堆的實現之深入分析 的末尾 ,簡單地比較了一下二叉堆與二項佇列。 對於二項佇列而言,它可以彌補二叉堆的不足:merge操作的時間複雜度為O(N)。二項佇列的merge操作的最壞時間複雜
【資料壓縮】LZ77演算法原理及實現
1. 引言 LZ77演算法是採用字典做資料壓縮的演算法,由以色列的兩位大神Jacob Ziv與Abraham Lempel在1977年發表的論文《A Universal Algorithm for Sequential Data Compression》中提出。 基於統計的資料壓縮編碼,比如Huffman編
【資料壓縮】LZ78演算法原理及實現
在提出基於滑動視窗的LZ77演算法後,兩位大神Jacob Ziv與Abraham Lempel於1978年在發表的論文 [1]中提出了LZ78演算法;與LZ77演算法不同的是LZ78演算法使用動態樹狀詞典維護歷史字串。 1. 原理 壓縮 LZ78演算法的壓縮過程非常簡單。在壓縮時維護一個動態詞典Dictio
資料結構之串的定義及實現
串的基本定義及實現 串型別的定義 定長順序儲存形式 堆分配儲存形式 1.1、串型別的定義 串(string)是零個或多個字元組成的有限序列 , S=‘a1a2…an’(n>=0) 其中,s是串名