
ResNet論文筆記
ResNet——MSRA何凱明團隊的Residual Networks,在2015年ImageNet上大放異彩,在ImageNet的classification、detection、localization以及COCO的detection和segmentation上均斬獲了第一名的成績,而且Deep Residual Learning for Image Recognition也獲得了CVPR2016的best paper,實在是實至名歸。就讓我們來觀摩大神的這篇上乘之作。
ResNet最根本的動機就是所謂的“退化”問題,即當模型的層次加深時,錯誤率卻提高了,如下圖:
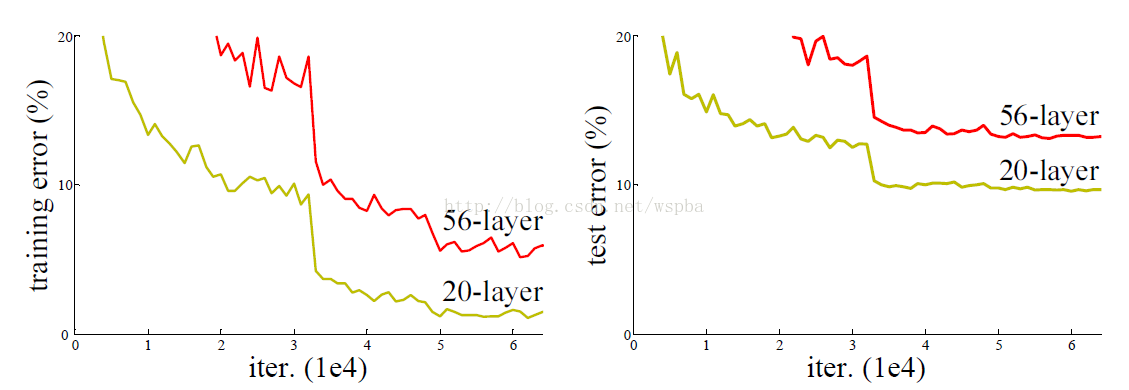
但是模型的深度加深,學習能力增強,因此更深的模型不應當產生比它更淺的模型更高的錯誤率。而這個“退化”問題產生的原因歸結於優化難題,當模型變複雜時,SGD的優化變得更加困難,導致了模型達不到好的學習效果。
針對這個問題,作者提出了一個Residual的結構:
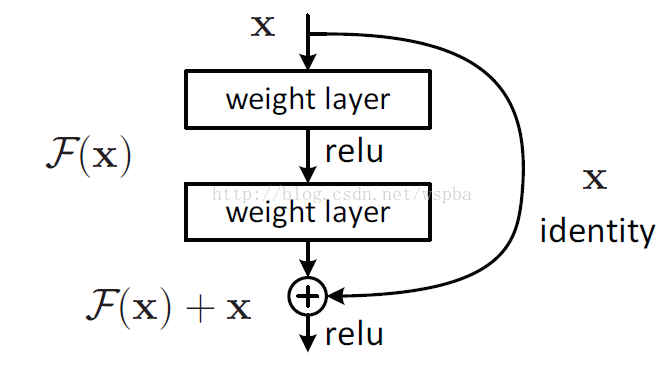
即增加一個identity mapping(恆等對映),將原始所需要學的函式H(x)轉換成F(x)+x,而作者認為這兩種表達的效果相同,但是優化的難度卻並不相同,作者假設F(x)的優化 會比H(x)簡單的多。這一想法也是源於影象處理中的殘差向量編碼,通過一個reformulation,將一個問題分解成多個尺度直接的殘差問題,能夠很好的起到優化訓練的效果。
這個Residual block通過shortcut connection實現,通過shortcut將這個block的輸入和輸出進行一個element-wise的加疊,這個簡單的加法並不會給網路增加額外的引數和計算量,同時卻可以大大增加模型的訓練速度、提高訓練效果,並且當模型的層數加深時,這個簡單的結構能夠很好的解決退化問題。
接下來,作者就設計實驗來證明自己的觀點。
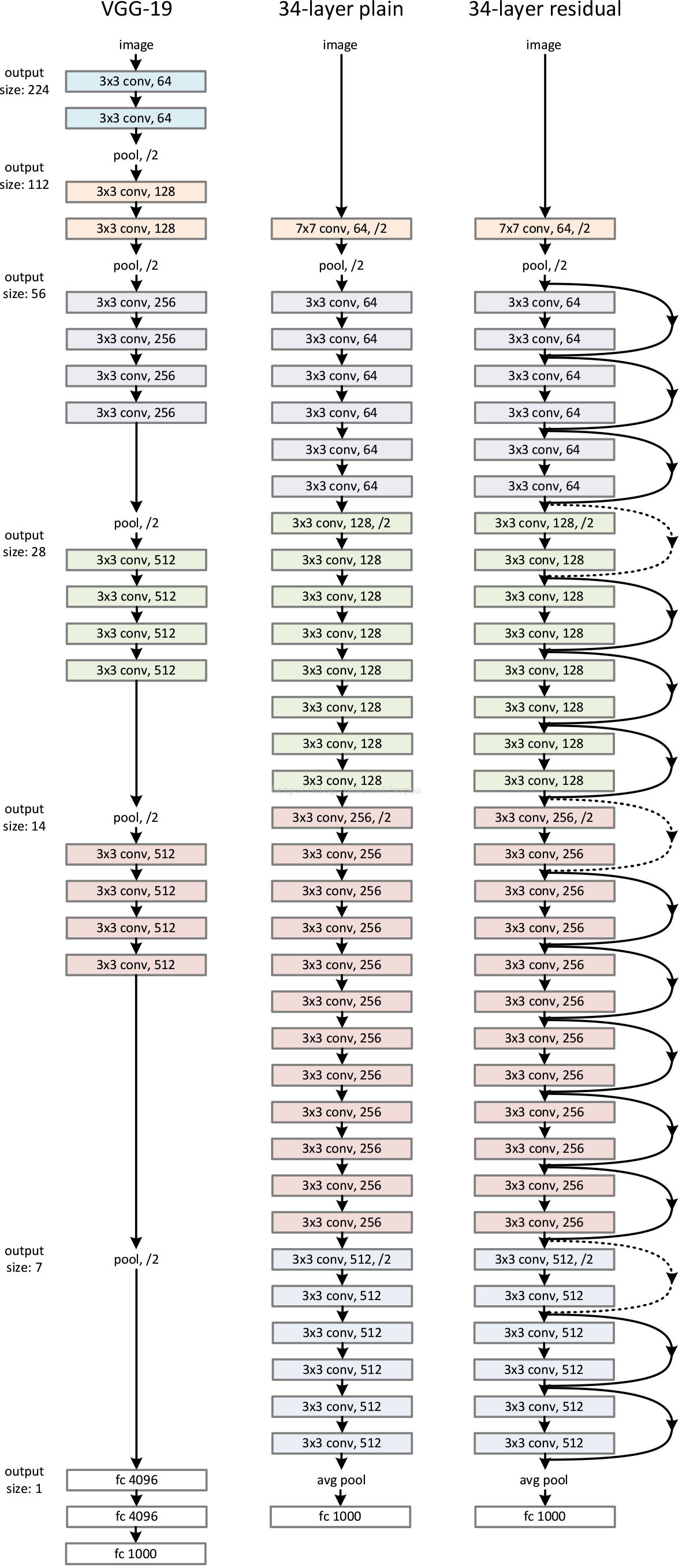
首先構建了一個18層和一個34層的plain網路,即將所有層進行簡單的鋪疊,然後構建了一個18層和一個34層的residual網路,僅僅是在plain上插入了shortcut,而且這兩個網路的引數量、計算量相同,並且和之前有很好效果的VGG-19相比,計算量要小很多。(36億FLOPs VS 196億FLOPs,FLOPs即每秒浮點運算次數。)這也是作者反覆強調的地方,也是這個模型最大的優勢所在。
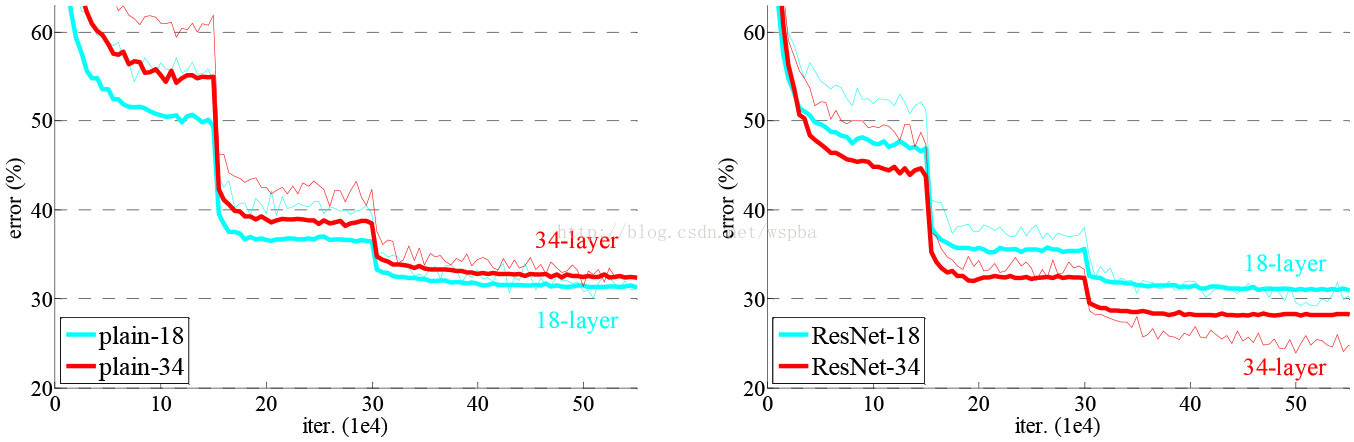
模型構建好後進行實驗,在plain上觀測到明顯的退化現象,而且ResNet上不僅沒有退化,34層網路的效果反而比18層的更好,而且不僅如此,ResNet的收斂速度比plain的要快得多。
對於shortcut的方式,作者提出了三個選項:
A. 使用恆等對映,如果residual block的輸入輸出維度不一致,對增加的維度用0來填充;
B. 在block輸入輸出維度一致時使用恆等對映,不一致時使用線性投影以保證維度一致;
C. 對於所有的block均使用線性投影。
對這三個選項都進行了實驗,發現雖然C的效果好於B的效果好於A的效果,但是差距很小,因此線性投影並不是必需的,而使用0填充時,可以保證模型的複雜度最低,這對於更深的網路是更加有利的。
進一步實驗,作者又提出了deeper的residual block:
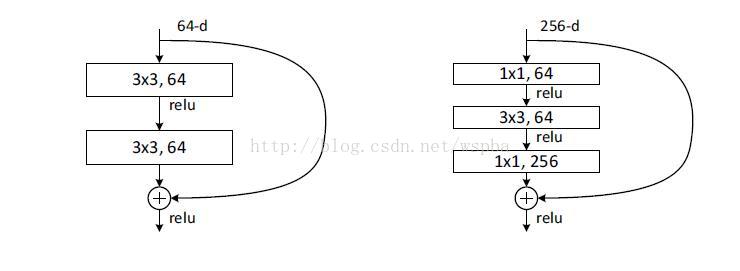
這相當於對於相同數量的層又減少了引數量,因此可以拓展成更深的模型。於是作者提出了50、101、152層的ResNet,而且不僅沒有出現退化問題,錯誤率也大大降低,同時計算複雜度也保持在很低的程度。
這個時候ResNet的錯誤率已經把其他網路落下幾條街了,但是似乎還並不滿足,於是又搭建了更加變態的1202層的網路,對於這麼深的網路,優化依然並不困難,但是出現了過擬合的問題,這是很正常的,作者也說了以後會對這個1202層的模型進行進一步的改進。(想想就可怕。)
在文章的附錄部分,作者又針對ResNet在其他幾個任務的應用進行了解釋,畢竟獲得了第一名的成績,也證明了ResNet強大的泛化能力,感興趣的同學可以好好研究這篇論文,是非常有學習價值的。
相關推薦
ResNet論文筆記
ResNet——MSRA何凱明團隊的Residual Networks,在2015年ImageNet上大放異彩,在ImageNet的classification、detection、localization以及COCO的detection和segmentation上均斬
ResNet 論文研讀筆記
Deep Residual Learning for Image Recognition 原文連結 摘要 深度神經網路很難去訓練,本文提出了一個殘差學習框架來簡化那些非常深的網路的訓練,該框架使得層能根據其輸入來學習殘差函式而非原始函式。本文提出證據表明,這些殘差網路的優化更簡單,而且通過增加深度來獲得
論文筆記:ResNet v2
ResNet v2 1、四個問題 要解決什麼問題? 進一步提高ResNet的效能。 解釋為何Identity mapping(恆等對映)的效果會比較好。 用了什麼方法解決? 提出了一個新的殘差單元結構。
【論文筆記】張航和李沐等提出:ResNeSt: Split-Attention Networks(ResNet改進版本)
github地址:https://github.com/zhanghang1989/ResNeSt 論文地址:https://hangzhang.org/files/resnest.pdf 核心就是:Split-attention blocks 先看一組圖: ResNeSt在影象分
論文筆記:目標追蹤-CVPR2014-Adaptive Color Attributes for Real-time Visual Tracking
exploit orm dom ons tail red 最好 早期 形式化 基於自適應顏色屬性的目標追蹤 Adaptive Color Attributes for Real-Time Visual Tracking 基於自適應顏色屬性的實時視覺追蹤 3月講的第一
論文筆記之 SST: Single-Stream Temporal Action Proposals
ron 我們 裁剪 只需要 lock proposal 數據 function 性能 SST: Single-Stream Temporal Action Proposals 2017-06-11 14:28:00 本文提出一種 時間維度上的 proposal
Selective Search for Object Recognition 論文筆記【圖片目標分割】
line 單個 介紹 images 分層 什麽 但是 如果 抽樣 這篇筆記,僅僅是對選擇性算法介紹一下原理性知識,不對公式進行推倒. 前言: 這篇論文介紹的是,如果快速的找到的可能是物體目標的區域,不像使用傳統的滑動窗口來暴力進行區域識別.這裏是使用算法從多個維度對找
Deep Learning論文筆記之(二)Sparse Filtering稀疏濾波
structure 分布 的確 tlab bolt 期望 有一個 尋找 mean Deep Learning論文筆記之(二)Sparse Filtering稀疏濾波 自己平時看了一些論文,但老感覺看完過後就會慢慢的淡忘,某一天重新拾起來的時候又好像沒有
Semi-supervised Segmentation of Optic Cup in Retinal Fundus Images Using Variational Autoencoder 論文筆記
str 很好 流程 Coding 測試 eat www tin nal MICCAI 2017年論文 Overview: 視杯視盤精確分割後,就可以計算杯盤比了,杯盤比是青光眼疾病的主要manifestation。以往的方法往往采用監督學習的方法,這樣需要大量的精確像素
論文筆記之:Collaborative Deep Reinforcement Learning for Joint Object Search
region format es2017 join sid col str bottom respond Collaborative Deep Reinforcement Learning for Joint Object Search CVPR 2017 Motiva
論文筆記-Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
mach default rap lin -s rnn alias for wrap 針對機器翻譯,提出 RNN encoder-decoder. encoder與decoder是兩個RNN,它們放在一起進行參數學習,最大化條件似然函數。 網絡結構: 註意輸入語句與
論文筆記-Sequence to Sequence Learning with Neural Networks
map tran between work down all 9.png ever onf 大體思想和RNN encoder-decoder是一樣的,只是用來LSTM來實現。 paper提到三個important point: 1)encoder和decoder的LSTM
論文筆記-Deep Interest Network for Click-Through Rate Prediction
圖片 res 興趣 log through deep pre 出發 amp 重點:認為不同的廣告會觸發用戶的興趣點不同導致user embedding隨之改變。 DIN網絡結構如下圖右邊 DIN的出發點:認為不同的廣告會觸發用戶的興趣點不同導致user embedd
論文筆記-DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
contain feature 比較 san date res 離散 edi post 針對交叉(高階)特征學習提出的DeepFM是一個end-to-end模型,不需要像wide&deep那樣在wide端人工構造特征。 網絡結構: sparse feature
論文筆記-Item2Vec- Neural Item Embedding for Collaborative Filtering
href resource 數據 per con doc 訂單 優化 div 將word2vec思想拓展到序列item的2vec方法並運用到推薦系統中,實質上可以認為是一種cf 在word2vec中,doc中的word是具有序列關系的,優化目標類似在max對數似然函數
論文筆記-Neural Machine Translation by Jointly Learning to Align and Translate
tps idt 個人理解 att date eight default con ati 提出attention機制,用於機器翻譯。 背景:基於RNN的機器翻譯 基本思路是首先對語言x進行編碼encoder,然後解碼decoder為語言y。encoder和decoder可
論文筆記-Wide & Deep Learning for Recommender Systems
wiki body pos ear recommend sys con 損失函數 wrapper 本文提出的W&D是針對rank環節的模型。 網絡結構: 本文提出的W&D是針對rank環節的模型。 網絡結構: wide是簡單的線性模型,但
論文筆記-Personal Recommendation Using Deep Recurrent Neural Networks in NetEase
use clas max onf 一位 url base 輸入 ont 思路:利用RNN對用戶瀏覽順序建模,利用FNN模擬CF,兩個網絡聯合學習 RNN網絡結構: 輸出層的state表示用戶瀏覽的某一頁面,可以看做是一個one-hot表示,state0到3是依次瀏覽的
論文筆記-Joint Deep Modeling of Users and Items Using Reviews for Recommendation
一個 solved default view http ati onf 評分 分享 基本思路:利用用戶和商品的評論構建CNN預測評分。 網絡結構: user review網絡與 item review網絡結構一致,僅就前者進行說明 從user review tex
【論文筆記】T Test
nor thum pan n-1 統計學 for nes 其它 align 用來算兩組數的差別大小 只要是一種叫做p-value的 就是說假如你測定一個實驗的p-value是5%也就是說你有95%的信心確定這個實驗它是正確的在正規的實驗裏 只有當p-value小於5%的時候