
Best Practices for Running Apache Cassandra on Amazon EC2
Apache Cassandra is a commonly used, high performance NoSQL database. AWS customers that currently maintain Cassandra on-premises may want to take advantage of the scalability, reliability, security, and economic benefits of running Cassandra on Amazon EC2.
Amazon EC2 and Amazon Elastic Block Store (Amazon EBS)
In this post, we outline three Cassandra deployment options, as well as provide guidance about determining the best practices for your use case in the following areas:
- Cassandra resource overview
- Deployment considerations
- Storage options
- Networking
- High availability and resiliency
- Maintenance
- Security
DynamoDB
Before we jump into best practices for running Cassandra on AWS, we should mention that we have many customers who decided to use DynamoDB instead of managing their own Cassandra cluster. DynamoDB is fully managed, serverless, and provides multi-master cross-region replication, encryption at rest, and managed backup and restore. Integration with AWS Identity and Access Management (IAM) enables DynamoDB customers to implement fine-grained access control for their data security needs.
Several customers who have been using large Cassandra clusters for many years have moved to DynamoDB to eliminate the complications of administering Cassandra clusters and maintaining high availability and durability themselves. Gumgum.com is one customer who migrated to DynamoDB and observed significant savings. For more information, see Moving to Amazon DynamoDB from Hosted Cassandra: A Leap Towards 60% Cost Saving per Year.
AWS provides options, so you’re covered whether you want to run your own NoSQL Cassandra database, or move to a fully managed, serverless DynamoDB database.
Cassandra resource overview
Here’s a short introduction to standard Cassandra resources and how they are implemented with AWS infrastructure. If you’re already familiar with Cassandra or AWS deployments, this can serve as a refresher.
| Resource | Cassandra | AWS |
| Cluster | A single Cassandra deployment. This typically consists of multiple physical locations, keyspaces, and physical servers. |
A logical deployment construct in AWS that maps to an AWS CloudFormation StackSet, which consists of one or many CloudFormation stacks to deploy Cassandra. |
| Datacenter | A group of nodes configured as a single replication group. | A logical deployment construct in AWS. A datacenter is deployed with a single CloudFormation stack consisting of Amazon EC2 instances, networking, storage, and security resources. |
| Rack | A collection of servers. A datacenter consists of at least one rack. Cassandra tries to place the replicas on different racks. |
A single Availability Zone. |
| Server/node | A physical virtual machine running Cassandra software. | An EC2 instance. |
| Token | Conceptually, the data managed by a cluster is represented as a ring. The ring is then divided into ranges equal to the number of nodes. Each node being responsible for one or more ranges of the data. Each node gets assigned with a token, which is essentially a random number from the range. The token value determines the node’s position in the ring and its range of data. | Managed within Cassandra. |
| Virtual node (vnode) | Responsible for storing a range of data. Each vnode receives one token in the ring. A cluster (by default) consists of 256 tokens, which are uniformly distributed across all servers in the Cassandra datacenter. | Managed within Cassandra. |
| Replication factor | The total number of replicas across the cluster. | Managed within Cassandra. |
Deployment considerations
One of the many benefits of deploying Cassandra on Amazon EC2 is that you can automate many deployment tasks. In addition, AWS includes services, such as CloudFormation, that allow you to describe and provision all your infrastructure resources in your cloud environment.
We recommend orchestrating each Cassandra ring with one CloudFormation template. If you are deploying in multiple AWS Regions, you can use a CloudFormation StackSet to manage those stacks. All the maintenance actions (scaling, upgrading, and backing up) should be scripted with an AWS SDK. These may live as standalone AWS Lambda functions that can be invoked on demand during maintenance.
Deployment patterns
In this section, we discuss various deployment options available for Cassandra in Amazon EC2. A successful deployment starts with thoughtful consideration of these options. Consider the amount of data, network environment, throughput, and availability.
- Single AWS Region, 3 Availability Zones
- Active-active, multi-Region
- Active-standby, multi-Region
Single region, 3 Availability Zones
In this pattern, you deploy the Cassandra cluster in one AWS Region and three Availability Zones. There is only one ring in the cluster. By using EC2 instances in three zones, you ensure that the replicas are distributed uniformly in all zones.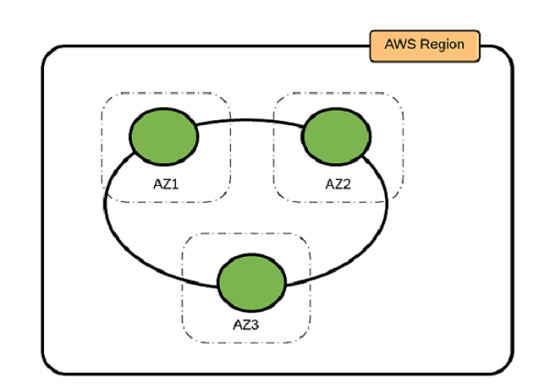
To ensure the even distribution of data across all Availability Zones, we recommend that you distribute the EC2 instances evenly in all three Availability Zones. The number of EC2 instances in the cluster is a multiple of three (the replication factor).
This pattern is suitable in situations where the application is deployed in one Region or where deployments in different Regions should be constrained to the same Region because of data privacy or other legal requirements.
| Pros | Cons |
| ● Highly available, can sustain failure of one Availability Zone. ● Simple deployment |
● Does not protect in a situation when many of the resources in a Region are experiencing intermittent failure. |
Active-active, multi-Region
In this pattern, you deploy two rings in two different Regions and link them. The VPCs in the two Regions are peered so that data can be replicated between two rings.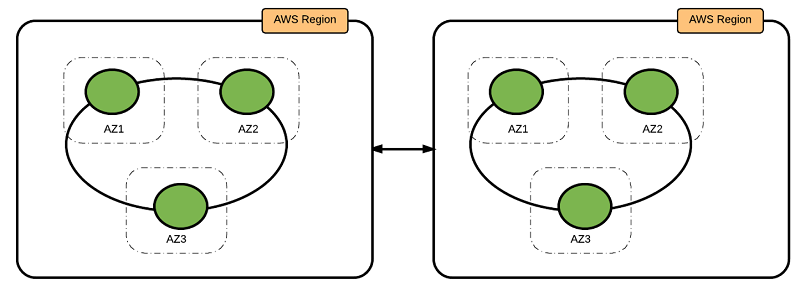
We recommend that the two rings in the two Regions be identical in nature, having the same number of nodes, instance types, and storage configuration.
This pattern is most suitable when the applications using the Cassandra cluster are deployed in more than one Region.
| Pros | Cons |
| ● No data loss during failover. ● Highly available, can sustain when many of the resources in a Region are experiencing intermittent failures. ● Read/write traffic can be localized to the closest Region for the user for lower latency and higher performance. |
● High operational overhead ● The second Region effectively doubles the cost |
Active-standby, multi-region
In this pattern, you deploy two rings in two different Regions and link them. The VPCs in the two Regions are peered so that data can be replicated between two rings.

However, the second Region does not receive traffic from the applications. It only functions as a secondary location for disaster recovery reasons. If the primary Region is not available, the second Region receives traffic.
We recommend that the two rings in the two Regions be identical in nature, having the same number of nodes, instance types, and storage configuration.
This pattern is most suitable when the applications using the Cassandra cluster require low recovery point objective (RPO) and recovery time objective (RTO).
| Pros | Cons |
| ● No data loss during failover. ● Highly available, can sustain failure or partitioning of one whole Region. |
● High operational overhead. ● High latency for writes for eventual consistency. ● The second Region effectively doubles the cost. |
Storage options
In on-premises deployments, Cassandra deployments use local disks to store data. There are two storage options for EC2 instances:
Your choice of storage is closely related to the type of workload supported by the Cassandra cluster. Instance store works best for most general purpose Cassandra deployments. However, in certain read-heavy clusters, Amazon EBS is a better choice.
The choice of instance type is generally driven by the type of storage:
- If ephemeral storage is required for your application, a storage-optimized (I3) instance is the best option.
- If your workload requires Amazon EBS, it is best to go with compute-optimized (C5) instances.
- Burstable instance types (T2) don’t offer good performance for Cassandra deployments.
Instance store
Ephemeral storage is local to the EC2 instance. It may provide high input/output operations per second (IOPs) based on the instance type. An SSD-based instance store can support up to 3.3M IOPS in I3 instances. This high performance makes it an ideal choice for transactional or write-intensive applications such as Cassandra.
In general, instance storage is recommended for transactional, large, and medium-size Cassandra clusters. For a large cluster, read/write traffic is distributed across a higher number of nodes, so the loss of one node has less of an impact. However, for smaller clusters, a quick recovery for the failed node is important.
As an example, for a cluster with 100 nodes, the loss of 1 node is 3.33% loss (with a replication factor of 3). Similarly, for a cluster with 10 nodes, the loss of 1 node is 33% less capacity (with a replication factor of 3).
| Ephemeral storage | Amazon EBS | Comments | |
| IOPS (translates to higher query performance) |
Up to 3.3M on I3 | 80K/instance 10K/gp2/volume 32K/io1/volume |
This results in a higher query performance on each host. However, Cassandra implicitly scales well in terms of horizontal scale. In general, we recommend scaling horizontally first. Then, scale vertically to mitigate specific issues. Note: 3.3M IOPS is observed with 100% random read with a 4-KB block size on Amazon Linux. |
| AWS instance types | I3 | Compute optimized, C5 | Being able to choose between different instance types is an advantage in terms of CPU, memory, etc., for horizontal and vertical scaling. |
| Backup/ recovery | Custom | Basic building blocks are available from AWS. | Amazon EBS offers distinct advantage here. It is small engineering effort to establish a backup/restore strategy. a) In case of an instance failure, the EBS volumes from the failing instance are attached to a new instance. b) In case of an EBS volume failure, the data is restored by creating a new EBS volume from last snapshot. |
Amazon EBS
EBS volumes offer higher resiliency, and IOPs can be configured based on your storage needs. EBS volumes also offer some distinct advantages in terms of recovery time. EBS volumes can support up to 32K IOPS per volume and up to 80K IOPS per instance in RAID configuration. They have an annualized failure rate (AFR) of 0.1–0.2%, which makes EBS volumes 20 times more reliable than typical commodity disk drives.
The primary advantage of using Amazon EBS in a Cassandra deployment is that it reduces data-transfer traffic significantly when a node fails or must be replaced. The replacement node joins the cluster much faster. However, Amazon EBS could be more expensive, depending on your data storage needs.
Cassandra has built-in fault tolerance by replicating data to partitions across a configurable number of nodes. It can not only withstand node failures but if a node fails, it can also recover by copying data from other replicas into a new node. Depending on your application, this could mean copying tens of gigabytes of data. This adds additional delay to the recovery process, increases network traffic, and could possibly impact the performance of the Cassandra cluster during recovery.
Data stored on Amazon EBS is persisted in case of an instance failure or termination. The node’s data stored on an EBS volume remains intact and the EBS volume can be mounted to a new EC2 instance. Most of the replicated data for the replacement node is already available in the EBS volume and won’t need to be copied over the network from another node. Only the changes made after the original node failed need to be transferred across the network. That makes this process much faster.
EBS volumes are snapshotted periodically. So, if a volume fails, a new volume can be created from the last known good snapshot and be attached to a new instance. This is faster than creating a new volume and coping all the data to it.
Most Cassandra deployments use a replication factor of three. However, Amazon EBS does its own replication under the covers for fault tolerance. In practice, EBS volumes are about 20 times more reliable than typical disk drives. So, it is possible to go with a replication factor of two. This not only saves cost, but also enables deployments in a region that has two Availability Zones.
EBS volumes are recommended in case of read-heavy, small clusters (fewer nodes) that require storage of a large amount of data. Keep in mind that the Amazon EBS provisioned IOPS could get expensive. General purpose EBS volumes work best when sized for required performance.
Networking
If your cluster is expected to receive high read/write traffic, select an instance type that offers 10–Gb/s performance. As an example, i3.8xlarge and c5.9xlarge both offer 10–Gb/s networking performance. A smaller instance type in the same family leads to a relatively lower networking throughput.
Cassandra generates a universal unique identifier (UUID) for each node based on IP address for the instance. This UUID is used for distributing vnodes on the ring.
In the case of an AWS deployment, IP addresses are assigned automatically to the instance when an EC2 instance is created. With the new IP address, the data distribution changes and the whole ring has to be rebalanced. This is not desirable.
To preserve the assigned IP address, use a secondary elastic network interface with a fixed IP address. Before swapping an EC2 instance with a new one, detach the secondary network interface from the old instance and attach it to the new one. This way, the UUID remains same and there is no change in the way that data is distributed in the cluster.
If you are deploying in more than one region, you can connect the two VPCs in two regions using cross-region VPC peering.
High availability and resiliency
Cassandra is designed to be fault-tolerant and highly available during multiple node failures. In the patterns described earlier in this post, you deploy Cassandra to three Availability Zones with a replication factor of three. Even though it limits the AWS Region choices to the Regions with three or more Availability Zones, it offers protection for the cases of one-zone failure and network partitioning within a single Region. The multi-Region deployments described earlier in this post protect when many of the resources in a Region are experiencing intermittent failure.
Resiliency is ensured through infrastructure automation. The deployment patterns all require a quick replacement of the failing nodes. In the case of a regionwide failure, when you deploy with the multi-Region option, traffic can be directed to the other active Region while the infrastructure is recovering in the failing Region. In the case of unforeseen data corruption, the standby cluster can be restored with point-in-time backups stored in Amazon S3.
Maintenance
In this section, we look at ways to ensure that your Cassandra cluster is healthy:
- Scaling
- Upgrades
- Backup and restore
Scaling
Cassandra is horizontally scaled by adding more instances to the ring. We recommend doubling the number of nodes in a cluster to scale up in one scale operation. This leaves the data homogeneously distributed across Availability Zones. Similarly, when scaling down, it’s best to halve the number of instances to keep the data homogeneously distributed.
Cassandra is vertically scaled by increasing the compute power of each node. Larger instance types have proportionally bigger memory. Use deployment automation to swap instances for bigger instances without downtime or data loss.
Upgrades
All three types of upgrades (Cassandra, operating system patching, and instance type changes) follow the same rolling upgrade pattern.
In this process, you start with a new EC2 instance and install software and patches on it. Thereafter, remove one node from the ring. For more information, see Cassandra cluster Rolling upgrade. Then, you detach the secondary network interface from one of the EC2 instances in the ring and attach it to the new EC2 instance. Restart the Cassandra service and wait for it to sync. Repeat this process for all nodes in the cluster.
Backup and restore
Your backup and restore strategy is dependent on the type of storage used in the deployment. Cassandra supports snapshots and incremental backups. When using instance store, a file-based backup tool works best. Customers often use rsync or other third-party products to copy data backups from the instance to long-term storage. This process has to be repeated for all instances in the cluster for a complete backup. These backup files are copied back to new instances to restore. We recommend using S3 to durably store backup files for long-term storage.
For Amazon EBS based deployments, you can enable automated snapshots of EBS volumes to back up volumes. New EBS volumes can be easily created from these snapshots for restoration.
Security
We recommend that you think about security in all aspects of deployment. The first step is to ensure that the data is encrypted at rest and in transit. The second step is to restrict access to unauthorized users. For more information about security, see the Cassandra documentation.
Encryption at rest
Encryption at rest can be achieved by using EBS volumes with encryption enabled. Amazon EBS uses AWS KMS for encryption. For more information, see Amazon EBS Encryption.
Instance store–based deployments require using an encrypted file system or an AWS partner solution.
Encryption in transit
Cassandra uses Transport Layer Security (TLS) for client and internode communications.
Authentication
The security mechanism is pluggable, which means that you can easily swap out one authentication method for another. You can also provide your own method of authenticating to Cassandra, such as a Kerberos ticket, or if you want to store passwords in a different location, such as an LDAP directory.
Authorization
The authorizer that’s plugged in by default is org.apache.cassandra.auth.Allow AllAuthorizer. Cassandra also provides a role-based access control (RBAC) capability, which allows you to create roles and assign permissions to these roles.
Conclusion
In this post, we discussed several patterns for running Cassandra in the AWS Cloud. This post describes how you can manage Cassandra databases running on Amazon EC2. AWS also provides managed offerings for a number of databases. To learn more, see Purpose-built databases for all your application needs.
If you have questions or suggestions, please comment below.
![]()
Additional Reading

About the Authors

Prasad Alle is a Senior Big Data Consultant with AWS Professional Services. He spends his time leading and building scalable, reliable Big data, Machine learning, Artificial Intelligence and IoT solutions for AWS Enterprise and Strategic customers. His interests extend to various technologies such as Advanced Edge Computing, Machine learning at Edge. In his spare time, he enjoys spending time with his family.
 Provanshu Dey is a Senior IoT Consultant with AWS Professional Services. He works on highly scalable and reliable IoT, data and machine learning solutions with our customers. In his spare time, he enjoys spending time with his family and tinkering with electronics & gadgets.
Provanshu Dey is a Senior IoT Consultant with AWS Professional Services. He works on highly scalable and reliable IoT, data and machine learning solutions with our customers. In his spare time, he enjoys spending time with his family and tinkering with electronics & gadgets.
相關推薦
Best Practices for Running Apache Cassandra on Amazon EC2
Apache Cassandra is a commonly used, high performance NoSQL database. AWS customers that currently maintain Cassandra on-premises may want to take
Migrate to Apache HBase on Amazon S3 on Amazon EMR: Guidelines and Best Practices
This blog post provides guidance and best practices about how to migrate from Apache HBase on HDFS to Apache HBase on Amazon S3 on Amazon EMR.
Best deals for Oct. 5: Save on Beats headphones, CBD oil, Cuisinart coffee makers, Amazon Echo Sub, and more
With the weekend finally here, we've gathered together the best deals to make your time away from work so much more enjoyable and relaxing. Speaking of rel
Fw: EPM 11.1.2.x – Planning/PBCS Best Practices for BSO Business Rule Optimisation
trigge rec oval sage depend opera manage 1.2 group 1. Introduction This document is intended to provide best practices for Business Rule
Best Practices for QML and Qt Quick
ins proto IT fault qmake scala simple text view Despite all of the benefits that QML and Qt Quick offer, they can be challenging in certa
轉錄組分析綜述A survey of best practices for RNA-seq data analysis
轉錄組分析綜述 轉錄組 文獻解讀 Trinity cufflinks 轉錄組研究綜述文章解讀 今天介紹下小編最近閱讀的關於RNA-seq分析的文章,文章發在Genome Biology 上的A survey of
PBR最佳實踐(Best Practices For Physically Based Content Creation)
該視訊是Anton Hand在Unite 大會上做的分享,比較老的視訊了,但是PBR理論及最佳實踐永遠不會過時。Anton Hand在Youtube上還有一個頻道 (需科學上網),每隔一段時間會上傳一個開發日誌,演示他做的VR專案進展,有興趣的可以看一下,是關於他的VR槍戰遊戲,目前
Google and Uber’s Best Practices for Deep Learning
Google and Uber’s Best Practices for Deep LearningThere is more to building a sustainable Deep Learning solution than what is provided by Deep Learning fra
Best deals for Oct. 1: Save on Instant Pot, Epson printers, Beats headphones, Echo Show, LEGO, and more
October is here and so are some great sales. We've gathered the best deals on the products you want, including printers, headphones, kitchen gear, video st
Best deals for Oct. 17: Save on Apple iPad Pro, LG 4K TVs, Dyson vacuums, Audible, Echo Show, and more
Save on tablets, vacuums, and Amazon devices, plus get fantastic discounts from IGN's 24-hour deals event Night of the Living Deals, which goes through Oct
time bushfire alerting with Complex Event Processing in Apache Flink on Amazon EMR and IoT sensor network | AWS Big Data Blog
Bushfires are frequent events in the warmer months of the year when the climate is hot and dry. Countries like Australia and the United States are
Best practices for building API Keys
Best practices for building API KeysHello there, we all know how valuable APIs are, its a gateway to explore other services, integrate with them and build
Learn Best Practices for Securing Your Account and Resources
AWS offers a number of tools to help secure your account. Many of these measures are not active by default, and you must take direct action to
Running Windows Containers on Amazon ECS
This post was developed and written by Jeremy Cowan, Thomas Fuller, Samuel Karp, and Akram Chetibi. — Containers have revolutioni
Best Practices for Implementing Custom CloudFormation Resources with Lambda
When implementing Lambda-backed custom resources in your CloudFormation stack, consider the following best practices: Build your cus
Prepare Environment for Working with AWS CLI and Amazon DynamoDB on Amazon EC2
Amazon Web Services is Hiring. Amazon Web Services (AWS) is a dynamic, growing business unit within Amazon.com. We are currently hiring So
Apache Spark on Amazon EMR
Apache Spark includes several libraries to help build applications for machine learning (MLlib), stream processing (Spark Streaming), and graph p
What are best practices for identifying users? Documentation
This tutorial will help you track newly registered users the right way. The process of shifting from an anonymous visitor to an identified user requires so
Best Practices for Spies, Stubs and Mocks in Sinon.js
Introduction Testing code with Ajax, networking, timeouts, databases, or other dependencies can be difficult. For example, if you use A
Host a Public Website on Amazon EC2 Using IIS
Amazon Web Services is Hiring. Amazon Web Services (AWS) is a dynamic, growing business unit within Amazon.com. We are currently hiring So