
Google and Uber’s Best Practices for Deep Learning
Google and Uber’s Best Practices for Deep Learning
There is more to building a sustainable Deep Learning solution than what is provided by Deep Learning frameworks like TensorFlow and PyTorch. These frameworks are good enough for research, but they don’t take into account the problems that crop up with production deployment. I’ve
Fortunately, Google and Uber have provided a glimpse of their internal architectures. The architectures of these two giants can be two excellent base-camps if you need to build your own production ready Deep Learning solution.
The primary motivations of Uber’s system named Michelangelo was that “there were no systems in place to build reliable, uniform, and reproducible pipelines for creating and managing training and prediction data at scale.” In their
I’m not going to go through Uber’s paper with you in its entirety. Rather, I’m just going to highlight some important points about their architecture. The Uber system is not a strictly Deep Learning system, but rather a Machine Learning system that can employ many ML methods depending on suitability. It is built on the following open source components: HDFS, Spark, Samza, Cassandra, MLLib, XGBoost, and TensorFlow. So, it’s a conventional BigData system that incorporates Machine Learning components for its analytics:
Michelangelo is built on top of Uber’s data and compute infrastructure, providing a data lake that stores all of Uber’s transactional and logged data, Kafka brokers that aggregate logged messages from all Uber’s services, a Samza streaming compute engine, managed Cassandra clusters, and Uber’s in-house service provisioning and deployment tools.
The architecture supports the following workflow:
- Manage data
- Train models
- Evaluate models
- Deploy, predict and monitor
Uber’s Michaelangelo architectures is depicted as follows:


I am going to skip over the usual Big Data architecture concerns and point out some notable ideas that relates more to machine learning.
Michaelangelo divides the management of data between online and offline pipelines. In addition, to permit knowledge sharing and reuse across the organization, a “feature store” is made available:
At the moment, we have approximately 10,000 features in Feature Store that are used to accelerate machine learning projects, and teams across the company are adding new ones all the time. Features in the Feature Store are automatically calculated and updated daily.
Uber created a Domain Specific Language (DSL) for modelers to select, transform and combine feature prior to sending a model to training and prediction. Currently supported ML methods are decision trees, linear and logistic models, k-means, time-series and deep neural networks.
The model configuration specifies type, hyper-parameters, data source references, the feature DSL expressions and compute resource requirements (i.e. cpus, memory, use of GPU, etc.). Training is performed in either a YARN or Mesos cluster.
After model training, performance metrics are calculated and provided in an evaluation report. All of the information, that is the model configuration, the learned model and the evaluation report are stored in the a versioned model repository for analysis and deployment. The model information contains:
- Who trained the model
- Start and end time of the training job
- Full model configuration (features used, hyper-parameter values, etc.)
- Reference to training and test data sets
- Distribution and relative importance of each feature
- Model accuracy metrics
- Standard charts and graphs for each model type (e.g. ROC curve, PR curve, and confusion matrix for a binary classifier)
- Full learned parameters of the model
- Summary statistics for model visualization
The idea is to democratize access to ML models, sharing it with other to improve organizational knowledge. The unique feature of Uber’s approach is the surfacing of a “Feature Store” that allows many different parties to share their data across different ML models.

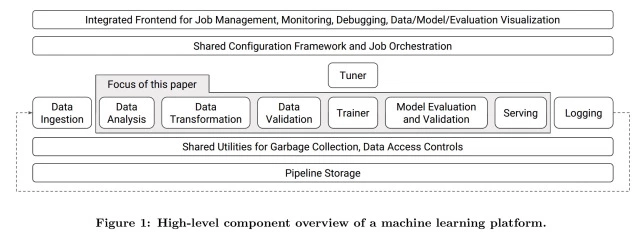
The paper is structured similarly to Uber’s paper in that they cover the same workflow:
- Manage data — Data Analysis, Transformation and Validation
- Train models — Model Training: Warm-Starting and Model Specification
- Evaluate models — Model Evaluation and Validation
- Deploy, predict and monitor — Model Serving
Google’s architecture is driven by the following stated high level guidelines:
- Capture Data Anomalies early.
- Automate data validation.
- Treat data errors with the same rigor as code.
- Support continuous training.
- Uniform configuration to improve sharing.
- Reliable and scalable production deployment and serving.
Let’s dig a little deeper into the unique capabilities of Google’s TFX. There are plenty of tidbits of wisdom as well as an introduction of several unique capabilities.
TFX provides several capabilities in the scope of data management. Data analysis performs statistics on each dataset providing information about value distribution, quantiles, mean, standard-deviation etc. The idea is that this allows users to quickly gain insights on the shape of dataset. This automated analysis is used to improve the continuous training and serving environment.
TFX handles the data wrangling and stores the transformations to maintain consistency. Furthermore, the system provides are uniform and consistent framework for managing feature-to-integer mappings.
TFX proves a schema that is version that specifies the expectations on the data. This schema is used to flag any anomalies found and also provide recommendations of actions such as blocking training or deprecating features. The tooling provide auto-generation of this schema to make it easy to use for new projects. This is a unique capability that draws inspiration from the static type checking found in programming languages.
TFX uses TensorFlow as its model description. TFX has this notion of ‘warm-starting’ that is inspired by transfer learning technique found in Deep Learning. The idea is to reduce the amount of training by leveraging existing training. Unlike transfer learning that employs an existing pre-trained network, warm-starting selectively identifies a general features network as its starting point. The network that is trained on general features are used as the basis for training more specialized networks. This feature appears to be implememented in TF-Slim.
TFX uses a common high level TensorFlow specification (see: TensorFlow Estimators: Managing Simplicity vs. Flexibility in High-Level Machine Learning Frameworks ) to provide uniformity and encode best practices across different implementations. See this article on Estimators for more detail.
TFX uses the TensorFlow Serving framework for deployment and serving. The framework allows different models to be served while keep the same architecture and API. TensorFlow Serving provies a “soft model-isolation” to allow multi-tenant deployment of models. The framework is also designed to support scalable inferences.
The TFX paper mentioned the need to optimize the deserialization of models. Apparently, a customized protocol buffer parses was created to improve performance up to 2–5 times.
Dissecting Uber and Google’s internal architecture provides good insight on pain-points and solutions for building your own internal platform. As compared to available open source DL frameworks, there is a greater emphasis in managing and sharing of meta-information. Google’s approach also demands additional effort to ensure uniformity as well as automated validation. These are practices that we have seen previously in conventional software-engineering projects.
Software engineering practices such as Test Driven Development (TDD), continuous integration, rollback and recovery, change control etc. are being introduced into advanced machine learning practices. It is not enough for a specialist to develop on a Jupyter notebook and throw it over the wall to a team to make operational. The same end-to-end devops practices that we find today in the best engineering companies are also going to be demanded in machine learning endeavors. We see this today in both Uber and Google, and thus we should expect it in any sustainable ML/DL practice.