
GAM(廣義相加模型)概要及R程式實現
國內關於GAM方面的資料不是一般的少,基本上都要往國外找。我光顧了沒100都有50個網站,翻查了不少論文及資料,研究整理出下文,歡迎一同討論。
GAM 廣義相加模型Generalized additive model:
|
概念 |
迴歸模型中部分或全部的自變數採用平滑函式,降低線性設定帶來的模型風險,對模型的假定不嚴,如不需要假定自變數線性相關於因變數(線性或非線性都可以)。 解決logistic迴歸當解釋變數個數較多時容易引起維度災難(Curse of dimensionality)。 光滑函式如應用到連續型解釋變數。 * http://plantecology.syr.edu/fridley/bio793/gam.html |
|
Equation |
g is a link function, y independent, fi(xi)為光滑函式(未知),代替經典線性迴歸中的xi,對樣本要求少,適用性廣。(unspecified nonparametric function replaces a single coefficient) |
|
估計方法 |
最小二乘法、likelyhood |
|
檢驗 |
殘差Pseduo係數(PCf)估計,PCf = 1 - RD / ND (RD殘差偏差,ND 無效偏差) |
|
分類 |
可加/非引數(Additive/Nonparametric): 引數(Parametric): 半引數/部分線性(Semiparametric/Partial Linear): 薄板樣條(Thin-plate spline): |
|
前提 |
如x1和x2並非獨立而存在互動作用,則應設為Thin-plate spline: f(x1, x2) 模型中不必每一項都是非線性的,如都非線性會出現計算量大、過擬合等問題,通過檢視xi與y的是否存線上性關係來判斷是否使用平滑函式。 Should follow statistical and operational considerations. |
|
光滑函式 |
見“樣條函式” |
|
缺點 |
樣條函式不定參使之不能直接用於預估新的資料(Lack of parametric functional form makes it difficult to score the new data directly) |
|
Q&A |
How to define smooth.terms in R.mgcv.GAM? competing philosophies: from "Try everything and go with the one that produces the best fit" (as measured by something like AIC) to "Write the one model that best reflects your understanding of the data-generating process and use it." |
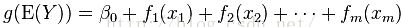
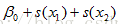
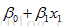
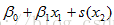
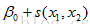 , allow for interactions between two predictor
, allow for interactions between two predictor廣義交叉驗證法(GCV,generalized cross-validation)
基本原理是當式Ax=b的測量值 b 中的任意一項i b被移除時,所選擇的正則引數應能預測到移除項所導致的變化。
馬洛斯的Cp、Cp—準則(Mallows' Cp)
用來幫助在多個候選迴歸模型之間進行選擇的一個統計量。Cp=(SSEp)/(2)-(n-2p)。
注:僅當使用相同的預測變數時,使用Mallows Cp 比較迴歸模型才有效。
結合Scorecard
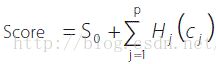
S0 = Intercept (only forBernoulli Likelihood objective function)
c1,c2, ..., cp = Scorecardcharacteristics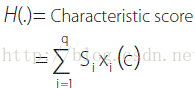
S1,S2,...,Sq = Score weightsassociated with the bins of a characteristics
X1,X2,...,Xq= Dummy indicatorvariables for the bins of a characteristics
關鍵是Score Weight的設定。
|
Y的分佈 |
聯絡函式名稱 |
f(Y) |
|
正態分佈(normal) |
Identity |
Y |
|
二項分佈(binomial) |
Logit |
Logit(Y) |
|
Poisson分佈 |
Log |
Log(Y) |
|
γ 分佈(gamma) |
inverse |
1/(Y-1) |
|
負二項分佈(negative binomial) |
Log |
Log(Y) |
樣條函式(spline function)
概念:早期工程師製圖時,把富有彈性的細長木條(所謂樣條)用壓鐵固定在樣點上,在其他地方讓它自由彎曲,然後沿木條畫下曲線。成為樣條曲線。
分段光滑、並且在各段交接處也有一定光滑性的函式,具有較好的數值穩定性和收斂性。
可多次樣條,最常用是二次和三次樣條。
(1)三次樣條插值(Cubic smoothingspline)
定義:函式S(x)∈C2[a,b] ,且在每個小區間[ xj,xj+1 ]上是三次多項式,其中a =x0<x1<...< xn= b 是給定節點,則稱S(x)是節點x0,x1,...xn上的三次樣條函式。
. To the left of the sequence of knots, anatural cubic spline is a line.
. Between knots, a natural cubic spline isa third degree polynomial curve. Hence the cubic in the name.
. At the knots, the curve must becontinuous. At the knots, the derivative also must be continuous (no corner).At the knots, the second derivative must be continuous.
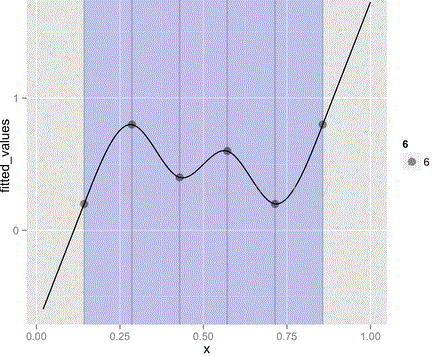
(2)cyclic spline
Live on a "circle", e.g. theytake values in the interval [0,1), and 0=1. like cyclic cubic regressionspline, cyclic p-spline.
R程式:
|
Concept |
Separate cubic polynomials are fit at each section, and then joined at the knots to create a continuous curve. effective degrees of freedom, or edf. In typical OLS regression the model degrees of freedom is equivalent to the number of predictors/terms in the model. s(Girth,Height) #Girth 和 Height 不獨立,存在相互影響 gam(Overall ~ Income + Edu + Health, data = d) # 此時與glm一樣 smooth terms: 其實就是應用了光滑函式的自變數e.g. s(agecont), te(Month,Age) |
|
gam syntax |
gam(y~s(x,k = , bs =)) / gam(y~te(x,k = , bs =)) Choose.k: sets up the dimensionality of the smoothing matrix for each term. Penalized regression smoothers. Using a substantially increased k to see if there is pattern in the residuals that could potentially be explained by increasing k. Default任意數字(normally 10 degree of freedom)。 bs: See smooth.terms for the full list. tp – DEFAULT, thin plate regression spline,cr – penalized cubic regression spline三次樣條, cs – shrinkage version of cr,cc – cyclic cubic regression spline, ps – P-spline,cp – cyclic p-spline, ad – adaptive smoothing, fs – factor smooth interaction. s: smooth s(covariate, edf); te: tensor product smooth gam(formula,family=gaussian(),data=list(),weights=NULL,subset=NULL, na.action,offset=NULL,method="GCV.Cp", optimizer=c("outer","newton"),control=list(),scale=0, select=FALSE,knots=NULL,sp=NULL,min.sp=NULL,H=NULL,gamma=1, fit=TRUE,paraPen=NULL,G=NULL,in.out,...) offset: Can be used to supply a model offset for use in fitting. Note that this offset will always be completely ignored when predicting, unlike an offset included in formula. control: A list of fit control parameters to replace defaults returned by gam.control. method: smoothing parameter estimation method. e.g. "GCV.Cp", "GACV.Cp", "REML", "P-REML", "ML", "P-ML" (ML = maximum likelihood, REML = 約束性最大似然法 restricted maximum likelihood) fit: If this argument is TRUE then gam sets up the model and fits it, but if it is FALSE then the model is set up and an object G containing what would be required to fit is returned is returned. Gamma: multiplier to inflate the degrees of freedom in the GCV/UBRE/AIC score. Select: TRUE means adding an extra penalty to each term so that it can be penalized to zero. s(x1, by=x2) e.g. Loc = America, Doy = as.numeric(format(Date,format = "%j")), s(Doy,by = Loc) |
|
test |
gam.check(b) # k' = k - 1 summary(gammodel) (1) GCV, with lower being better. (2) R-sq.(adj) near to 1 is better. AIC(mod_1d, mod_2d) (3) with lower being better. anova(b) # Wald like tests anova(mod_1d, mod_2d, test = "Chisq") #取lower resid.deviance anova(b,b1,test="F") (4) select the significant one |
|
plot |
plot(mod_gam2, pages=1, residuals=T, shade=T, col='#FF8000') vis.gam(mod_gam2, type = "response", plot.type = "contour") vis.gam(mod_gam2, type = "response", plot.type = "persp", border=NA, phi=30, theta=30) * If the graph looks noise, then the smooth function may be not suitable. * http://stats.stackexchange.com/questions/14746/what-does-the-dashed-bounds-mean-when-plotting-a-contour-plot-with-r-gam |
|
Q&A |
Err: - not meaningful for factors in: Ops.factor(xx, shift[i]) A: smoothing a factor, which isn't supported (`smooth' means that f(x_1) must be close to f(x_2), e.g. if a factor has levels "brick", "sky" and "purple", how far is it from "brick" to "purple"?) Err: A term has fewer unique covariate combinations than specified maximum degrees of freedom / basis dimension is larger than number of unique covariates A: for smoothing function, one independent variables portfolio cannot match to different response variable values. Q: how to choose a proper smoothing spline (bs='?') A: 1) use the default; 2) use a tensor product of "cr" smooths for bivariate smoothing, ie. te=(x,bs=”cr”) |
|
Summary |
Formula: LN_Brutto ~ s(agecont, by = Sex) + factor(Sex) + te(Month, Age) + s(Month, by = Sex) Parametric coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 4.32057 0.01071 403.34 <2e-16 *** factor(Sex)m 0.27708 0.01376 20.14 <2e-16 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Approximate significance of smooth terms: edf Ref.df F p-value s(agecont):Sexf 8.1611 8.7526 20.170 < 2e-16 *** s(agecont):Sexm 6.6695 7.5523 32.689 < 2e-16 *** te(Month,Age) 10.3651 12.7201 6.784 2.19e-12 *** s(Month):Sexf 0.9701 0.9701 0.641 0.430 s(Month):Sexm 1.3750 1.6855 0.193 0.787 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Rank: 60/62 R-sq.(adj) = 0.781 Deviance explained = 78.7% GCV = 0.048221 Scale est. = 0.046918 n = 1093 |
相關推薦
GAM(廣義相加模型)概要及R程式實現
國內關於GAM方面的資料不是一般的少,基本上都要往國外找。我光顧了沒100都有50個網站,翻查了不少論文及資料,研究整理出下文,歡迎一同討論。 GAM 廣義相加模型Generalized additive model: 概念 迴歸模型中部分或全部的自變數採用平滑函式
R語言解決Lasso問題----glmnet包(廣義線性模型)
Lasso迴歸複雜度調整的程度由引數lambda來控制,lambda越大模型複雜度的懲罰力度越大,從而獲得一個較少變數的模型。Lasso迴歸和bridge迴歸都是Elastic Net
極限學習機(ELM) 演算法及MATLAB程式實現
極限學習機 單隱藏層反饋神經網路具有兩個比較突出的能力: (1)可以直接從訓練樣本中擬 合 出 復 雜 的 映 射 函 數f :x ^ t (2 )可以為大量難以用傳統分類引數技術處理的自然或者人工現象提供模型。但是單隱藏層反饋神經網路缺少比較快速的學習方 法 。
Python機器學習及實踐——基礎篇7(分類整合模型)
常言道:“一個籬笆三個樁,一個好漢三個幫”。整合分類模型便是綜合考量多個分類器的預測結果,從而做出決策。只是這種“綜合考量”的方式大體上分為兩種: 一種是利用相同的訓練資料同時搭建多個獨立的分類模型,然後通過投票的方式,以少數服從多數的原則作出最終的分類決策。比
C_深入(內存模型)
urn 指向 修改 存儲位置 ... 右值 函數返回 改變 對象分配 01 數據類型: 為什麽有數據類型? 現實生活中的數據太多而且大小形態不一。 數據類型與內存的關系: 數據類型的本質:創建變量的模具,是固定大小的別名。 #include "stdio.h" #incl
C# WPF MVVM QQ密碼管家項目(2,模型)
service 做的 ext pri 客戶 完成 bsp chang invoke 2 - 模型Models 在這個項目中只有一個數據模型,那就是qq賬號數據。那麽qq賬號數據具有兩個屬性,一個是qq號,一個是密碼。 mvvm架構中我們需要做的是“前後臺分離
數據庫 之 Mysql的主主同步(雙主模型)
兩個 white serve 執行 密碼連接 進行 st3 提交 復制 1 概述互為主從:兩個節點各自都要開啟binlog和relay log; 1、數據不一致; 2、自動增長id;為了防止id沖突,解決辦法是一個服務器使用奇數id,另一個服務器使用偶數id,合並的時候一
普通高中課程方案和語文等學科課程標準(2017年版)----分析及教育部官網網址
信息 智能家居 eight ffffff 機器 add href 分享圖片 能源 我主要關註:高中信息技術、通用技術方面的課標。下面就把我的體會總結一下,便於後續教研。 高中信息技術 高中通用技術
Debian7配置LAMP(Apache/MySQL/PHP)環境及搭建建站
topic -- mysq nts gist 根據 ads prot 固定 完整Debian7配置LAMP(Apache/MySQL/PHP)環境及搭建建站 第一、安裝和配置Apache Web服務器 運行升級命令來確保我們的系統組件各方面都是最新的。 apt
無監督學習:Deep Generative Mode(深度生成模型)
speech nom like 當前 多個 generator 問題 get pixel 一 前言 1.1 Creation 據說在費曼死後,人們在他生前的黑板上拍到如圖畫片,在左上角有道:What i cannot create ,I do not understand.
Python基礎-----生成器函數(生產者消費者模型)
生成器 while for odi 生產者消費者 繼續 time __next__ urn #!/usr/bin/env python# -*- coding:utf-8 -*-# yield x相當於return 控制的是函數的返回值# 在定義生成器函數的yield時,
理解JWT(JSON Web Token)認證及python實踐
原文:https://segmentfault.com/a/1190000010312468?utm_source=tag-newest 幾種常用的認證機制 HTTP Basic Auth HTTP Basic Auth 在HTTP中,基本認證是一種用來允許Web瀏覽器或其他客戶端程式在請求時
java併發系列一(java記憶體模型)
作為一個半路出家學java的菜菜菜鳥,真的是感覺路漫漫其修遠兮,工作間隙看了大約兩週的java併發,現在開始慢慢總結。 1.執行緒間的通訊 執行緒之間的協作主要有幾個點,wait,notify,notiyALl(),顯示Condition物件,佇列中的生產者消費者等等。主要就是條件佇
JMM(JVM記憶體模型)
Java通過多執行緒機制實現多工並行處理。 所有執行緒共享JVM記憶體(main memory),同時執行緒又有自己的工作記憶體。 當執行緒與主存進行互動時,資料從主存複製到工作記憶體中,由執行緒進行處理。 JVM的邏輯記憶體模型中,包含如下幾個部分: 1)程式計數器 2)虛擬機器棧 3
python 自然語言處理 統計語言建模 - (n-gram模型)
N-gram語言模型 考慮一個語音識別系統,假設使用者說了這麼一句話:“I have a gun”,因為發音的相似,該語音識別系統發現如下幾句話都是可能的候選:1、I have a gun. 2、I have a gull. 3、I have a gub. 那麼問題來了,到底哪一個是正確答案呢?
BZOJ-4556 找相同字元(廣義字尾自動機)
給定兩個字串,求出在兩個字串中各取出一個子串使得這兩個子串相同的方案數。兩個方案不同當且僅當這兩 個子串中有一個位置不同。 Input 兩行,兩個字串s1,s2,長度分別為n1,n2。1 <=n1, n2<= 200000,字串中只有小寫字母 Out
NLP --- 寫在前面(概率圖模型)
本節將正式進入自然語言處理的領域,在自然語言處理的總結中,我不會總結的那麼細了,如剛開始的語言模型,自動機及其應用、校準、歧義消除、平滑方法等,這些基礎性的知識大家需要找本書看看,例如宗成慶老師的《統計自然語言處理》,前五章的內容大家應該有所瞭解,我這裡就不重複了,一是因為這是很老的內容的了,在
樂優商城(二十四)——RabbitMQ及資料同步
一、RabbitMQ 1.1 搜尋與商品服務的問題 1.2 訊息佇列(MQ) 1.2.1 什麼是訊息佇列 1.2.2 AMQP和JMS 1.2.3 常見MQ產品 1.2.4 RabbitMQ 1.3 下載和安裝 1.3.1 下載 1.3.2 安裝 二、五種
二叉樹後序遍歷(遞迴與非遞迴)演算法及C語言實現
二叉樹後序遍歷的實現思想是:從根節點出發,依次遍歷各節點的左右子樹,直到當前節點左右子樹遍歷完成後,才訪問該節點元素。 圖 1 二叉樹 如圖 1 中,對此二叉樹進行後序遍歷的操作過程為: 從根節點 1 開始,遍歷該節點的左子樹(以節點 2 為根節點); 遍歷節點 2 的左子樹(以節點 4 為根
二叉樹中序遍歷(遞迴和非遞迴)演算法及C語言實現
二叉樹中序遍歷的實現思想是: 訪問當前節點的左子樹; 訪問根節點; 訪問當前節點的右子樹; 圖 1 二叉樹 以圖 1 為例,採用中序遍歷的思想遍歷該二叉樹的過程為: 訪問該二叉樹的根節點,找到 1; 遍歷節點 1 的左子樹,找到節點 2; 遍歷節點 2 的左子樹,找到節點 4;