
極限學習機(ELM) 演算法及MATLAB程式實現
極限學習機
單隱藏層反饋神經網路具有兩個比較突出的能力:
(1)可以直接從訓練樣本中擬 合 出 復 雜 的 映 射 函 數f :x ^ t
(2 )可以為大量難以用傳統分類引數技術處理的自然或者人工現象提供模型。但是單隱藏層反饋神經網路缺少比較快速的學習方 法 。誤差反向傳播演算法每次迭代需要更新n x(L+ 1) +L x (m+ 1 )個 值 ,所花費的時間遠遠低於所容忍的時間。經常可以看到為訓練一個單隱藏層反饋神經網路花費了數小時,數天或者更多的時間。
基於以上原因,黃廣斌教授對單隱藏層反饋神經網路進行了深入的研究,提
出並證明了兩個大膽的理論:

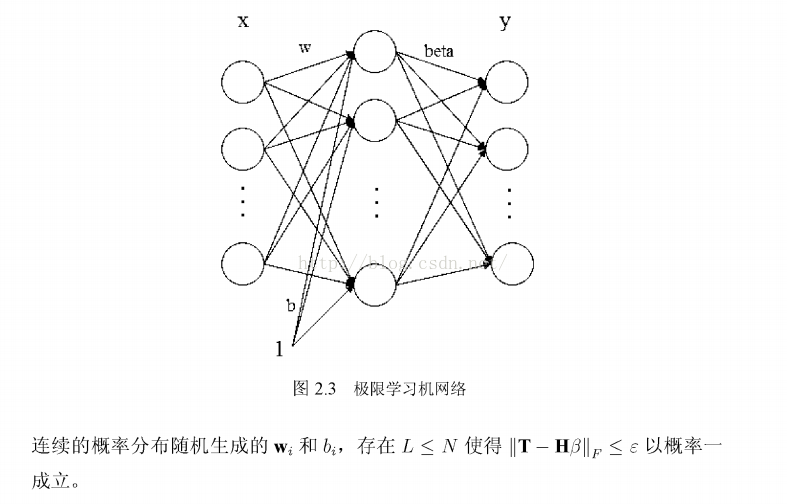
從以上兩條理論我們可以看出,只要激勵函式
對比圖2.2,缺少了輸出層偏 置bs,而輸入權重w和隱藏層偏置bi隨機產生不需要調整,那麼整個網路僅僅剩下輸出權重beta一項沒有確定。因此極限學習機
應運而生。令神經網路的輸出等於樣本標籤,如式 (2-11) 表示




n x(L+1) +Lx(m+1)個值,且反向傳播演算法為了保證系統的穩定性通常選取較小的學習率,使得學習時間大大加長。因此極限學習機在這一方法優勢非常巨大,在實驗中 ,極限學習機往往在數秒內就完成了運算。而一些比較經典的演算法在訓練一個單隱藏層神經網路的時候即使是很小的應用也要花費大量的時間,似乎這些演算法存在著一個無法逾越的虛擬速度壁壘。
(2)在大多數的應用中,極限學習機的泛化能力大於類似於誤差反向傳播演算法這類的基於梯度的演算法。
( 3 ) 傳統的基於梯度的演算法需要面對諸如區域性最小,合適的學習率、過擬合等問題 ,而極限學習機一步到位直接構建起單隱藏層反饋神經網路,避免了這些難以處理的棘手問題。
極限學習機由於這些優勢,廣大研究人員對極限學習機報以極大的興趣,使得這幾年極限學習機的理論發展很快,應用也在不斷地拓寬。
小結
本文主要對極限學習機的本質原理和來龍去脈作了詳盡的介紹,闡明極限學習機所具有的各種各樣優勢吸引廣大學者進行研究。然而極限學習機也有自己的劣勢,接下來我們將對極限學習機的劣勢進行分析和研究並加以改進。
MATLAB程式:可以到GB.Huang老師
1、一個迴歸的例子:(資料、程式放在同一資料夾)
clear all;
close all;
clc;
[TrainingTime, TestingTime, TrainingAccuracy, TestingAccuracy] = ELM('sinc_train', 'sinc_test', 0, 20, 'sig')ELM.m
function [TrainingTime, TestingTime, TrainingAccuracy, TestingAccuracy] = elm(TrainingData_File, TestingData_File, Elm_Type, NumberofHiddenNeurons, ActivationFunction)
% Usage: elm(TrainingData_File, TestingData_File, Elm_Type, NumberofHiddenNeurons, ActivationFunction)
% OR: [TrainingTime, TestingTime, TrainingAccuracy, TestingAccuracy] = elm(TrainingData_File, TestingData_File, Elm_Type, NumberofHiddenNeurons, ActivationFunction)
%
% Input:
% TrainingData_File - Filename of training data set
% TestingData_File - Filename of testing data set
% Elm_Type - 0 for regression; 1 for (both binary and multi-classes) classification
% NumberofHiddenNeurons - Number of hidden neurons assigned to the ELM
% ActivationFunction - Type of activation function:
% 'sig' for Sigmoidal function
% 'sin' for Sine function
% 'hardlim' for Hardlim function
% 'tribas' for Triangular basis function
% 'radbas' for Radial basis function (for additive type of SLFNs instead of RBF type of SLFNs)
%
% Output:
% TrainingTime - Time (seconds) spent on training ELM
% TestingTime - Time (seconds) spent on predicting ALL testing data
% TrainingAccuracy - Training accuracy:
% RMSE for regression or correct classification rate for classification
% TestingAccuracy - Testing accuracy:
% RMSE for regression or correct classification rate for classification
%
% MULTI-CLASSE CLASSIFICATION: NUMBER OF OUTPUT NEURONS WILL BE AUTOMATICALLY SET EQUAL TO NUMBER OF CLASSES
% FOR EXAMPLE, if there are 7 classes in all, there will have 7 output
% neurons; neuron 5 has the highest output means input belongs to 5-th class
%
% Sample1 regression: [TrainingTime, TestingTime, TrainingAccuracy, TestingAccuracy] = elm('sinc_train', 'sinc_test', 0, 20, 'sig')
% Sample2 classification: elm('diabetes_train', 'diabetes_test', 1, 20, 'sig')
%
%%%% Authors: MR QIN-YU ZHU AND DR GUANG-BIN HUANG
%%%% NANYANG TECHNOLOGICAL UNIVERSITY, SINGAPORE
%%%% EMAIL: [email protected]; [email protected]
%%%% WEBSITE: http://www.ntu.edu.sg/eee/icis/cv/egbhuang.htm
%%%% DATE: APRIL 2004
%%%%%%%%%%% Macro definition
REGRESSION=0;
CLASSIFIER=1;
%%%%%%%%%%% Load training dataset
train_data=load(TrainingData_File);
T=train_data(:,1)';
P=train_data(:,2:size(train_data,2))';
clear train_data; % Release raw training data array
%%%%%%%%%%% Load testing dataset
test_data=load(TestingData_File);
TV.T=test_data(:,1)';
TV.P=test_data(:,2:size(test_data,2))';
clear test_data; % Release raw testing data array
NumberofTrainingData=size(P,2);
NumberofTestingData=size(TV.P,2);
NumberofInputNeurons=size(P,1);
if Elm_Type~=REGRESSION
%%%%%%%%%%%% Preprocessing the data of classification
sorted_target=sort(cat(2,T,TV.T),2);
label=zeros(1,1); % Find and save in 'label' class label from training and testing data sets
label(1,1)=sorted_target(1,1);
j=1;
for i = 2:(NumberofTrainingData+NumberofTestingData)
if sorted_target(1,i) ~= label(1,j)
j=j+1;
label(1,j) = sorted_target(1,i);
end
end
number_class=j;
NumberofOutputNeurons=number_class;
%%%%%%%%%% Processing the targets of training
temp_T=zeros(NumberofOutputNeurons, NumberofTrainingData);
for i = 1:NumberofTrainingData
for j = 1:number_class
if label(1,j) == T(1,i)
break;
end
end
temp_T(j,i)=1;
end
T=temp_T*2-1;
%%%%%%%%%% Processing the targets of testing
temp_TV_T=zeros(NumberofOutputNeurons, NumberofTestingData);
for i = 1:NumberofTestingData
for j = 1:number_class
if label(1,j) == TV.T(1,i)
break;
end
end
temp_TV_T(j,i)=1;
end
TV.T=temp_TV_T*2-1;
end % end if of Elm_Type
%%%%%%%%%%% Calculate weights & biases
start_time_train=cputime;
%%%%%%%%%%% Random generate input weights InputWeight (w_i) and biases BiasofHiddenNeurons (b_i) of hidden neurons
InputWeight=rand(NumberofHiddenNeurons,NumberofInputNeurons)*2-1;
BiasofHiddenNeurons=rand(NumberofHiddenNeurons,1);
tempH=InputWeight*P;
clear P; % Release input of training data
ind=ones(1,NumberofTrainingData);
BiasMatrix=BiasofHiddenNeurons(:,ind); % Extend the bias matrix BiasofHiddenNeurons to match the demention of H
tempH=tempH+BiasMatrix;
%%%%%%%%%%% Calculate hidden neuron output matrix H
switch lower(ActivationFunction)
case {'sig','sigmoid'}
%%%%%%%% Sigmoid
H = 1 ./ (1 + exp(-tempH));
case {'sin','sine'}
%%%%%%%% Sine
H = sin(tempH);
case {'hardlim'}
%%%%%%%% Hard Limit
H = double(hardlim(tempH));
case {'tribas'}
%%%%%%%% Triangular basis function
H = tribas(tempH);
case {'radbas'}
%%%%%%%% Radial basis function
H = radbas(tempH);
%%%%%%%% More activation functions can be added here
end
clear tempH; % Release the temparary array for calculation of hidden neuron output matrix H
%%%%%%%%%%% Calculate output weights OutputWeight (beta_i)
OutputWeight=pinv(H') * T'; % implementation without regularization factor //refer to 2006 Neurocomputing paper
%OutputWeight=inv(eye(size(H,1))/C+H * H') * H * T'; % faster method 1 //refer to 2012 IEEE TSMC-B paper
%implementation; one can set regularizaiton factor C properly in classification applications
%OutputWeight=(eye(size(H,1))/C+H * H') \ H * T'; % faster method 2 //refer to 2012 IEEE TSMC-B paper
%implementation; one can set regularizaiton factor C properly in classification applications
%If you use faster methods or kernel method, PLEASE CITE in your paper properly:
%Guang-Bin Huang, Hongming Zhou, Xiaojian Ding, and Rui Zhang, "Extreme Learning Machine for Regression and Multi-Class Classification," submitted to IEEE Transactions on Pattern Analysis and Machine Intelligence, October 2010.
end_time_train=cputime;
TrainingTime=end_time_train-start_time_train % Calculate CPU time (seconds) spent for training ELM
%%%%%%%%%%% Calculate the training accuracy
Y=(H' * OutputWeight)'; % Y: the actual output of the training data
if Elm_Type == REGRESSION
TrainingAccuracy=sqrt(mse(T - Y)) % Calculate training accuracy (RMSE) for regression case
end
clear H;
%%%%%%%%%%% Calculate the output of testing input
start_time_test=cputime;
tempH_test=InputWeight*TV.P;
clear TV.P; % Release input of testing data
ind=ones(1,NumberofTestingData);
BiasMatrix=BiasofHiddenNeurons(:,ind); % Extend the bias matrix BiasofHiddenNeurons to match the demention of H
tempH_test=tempH_test + BiasMatrix;
switch lower(ActivationFunction)
case {'sig','sigmoid'}
%%%%%%%% Sigmoid
H_test = 1 ./ (1 + exp(-tempH_test));
case {'sin','sine'}
%%%%%%%% Sine
H_test = sin(tempH_test);
case {'hardlim'}
%%%%%%%% Hard Limit
H_test = hardlim(tempH_test);
case {'tribas'}
%%%%%%%% Triangular basis function
H_test = tribas(tempH_test);
case {'radbas'}
%%%%%%%% Radial basis function
H_test = radbas(tempH_test);
%%%%%%%% More activation functions can be added here
end
TY=(H_test' * OutputWeight)'; % TY: the actual output of the testing data
end_time_test=cputime;
TestingTime=end_time_test-start_time_test % Calculate CPU time (seconds) spent by ELM predicting the whole testing data
if Elm_Type == REGRESSION
TestingAccuracy=sqrt(mse(TV.T - TY)); % Calculate testing accuracy (RMSE) for regression case
end
if Elm_Type == REGRESSION
figure
plot(TV.T,'LineWidth',1.2);hold on ;
plot(TY,'LineWidth',1.2)
legend('真實值','估計值')
end
if Elm_Type == CLASSIFIER
%%%%%%%%%% Calculate training & testing classification accuracy
MissClassificationRate_Training=0;
MissClassificationRate_Testing=0;
for i = 1 : size(T, 2)
[x, label_index_expected]=max(T(:,i));
[x, label_index_actual]=max(Y(:,i));
if label_index_actual~=label_index_expected
MissClassificationRate_Training=MissClassificationRate_Training+1;
end
end
TrainingAccuracy=1-MissClassificationRate_Training/size(T,2)
for i = 1 : size(TV.T, 2)
[x, label_index_expected]=max(TV.T(:,i));
[x, label_index_actual]=max(TY(:,i));
if label_index_actual~=label_index_expected
MissClassificationRate_Testing=MissClassificationRate_Testing+1;
end
end
TestingAccuracy=1-MissClassificationRate_Testing/size(TV.T,2)
end測試結果:
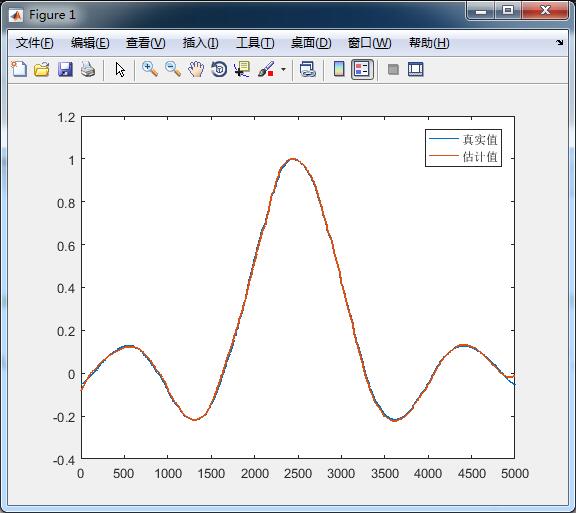
TrainingTime =0.1248
TestingTime = 0
TrainingAccuracy = 0.1158
TestingAccuracy =0.0074
2、一個分類的例子
clear all;
close all;
clc;
[TrainingTime, TestingTime, TrainingAccuracy, TestingAccuracy] = ELM('diabetes_train', 'diabetes_test', 1, 20, 'sig')ELM.m還是上面的那個
模擬結果:
TrainingTime =0.0624
TestingTime = 0
TrainingAccuracy = 0.7674
TestingAccuracy =0.7865
歡迎評論,點贊!