
Svm演算法原理及實現
Svm(support Vector Mac)又稱為支援向量機,是一種二分類的模型。當然如果進行修改之後也是可以用於多類別問題的分類。支援向量機可以分為線性核非線性兩大類。其主要思想為找到空間中的一個更夠將所有資料樣本劃開的超平面,並且使得本本集中所有資料到這個超平面的距離最短。
一、基於最大間隔分隔資料
1.1支援向量與超平面
在瞭解svm演算法之前,我們首先需要了解一下線性分類器這個概念。比如給定一系列的資料樣本,每個樣本都有對應的一個標籤。為了使得描述更加直觀,我們採用二維平面進行解釋,高維空間原理也是一樣。舉個簡單子:如下圖所示是一個二維平面,平面上有兩類不同的資料,分別用圓圈和方塊表示。我們可以很簡單地找到一條直線使得兩類資料正好能夠完全分開。但是能將據點完全劃開直線不止一條,那麼在如此眾多的直線中我們應該選擇哪一條呢?從直觀感覺上看圖中的幾條直線,
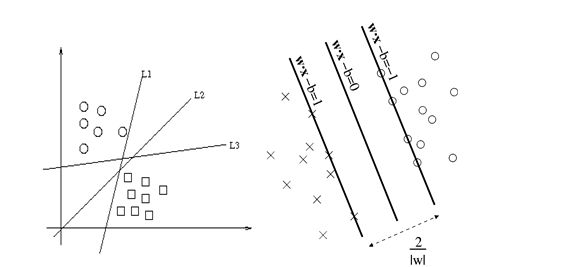
圖
1.2尋找最大間隔
1.2.1點到超平面的距離公式
既然這樣的直線是存在的,那麼我們怎樣尋找出這樣的直線呢?與二維空間類似,超平面的方程也可以寫成一下形式:
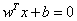
有了超平面的表示式之後之後,我們就可以計算樣本點到平面的距離了。假設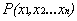

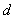
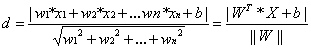
其中||W||為超平面的範數,常數b類似於直線方程中的截距。
上面的公式可以利用解析幾何或高中平面幾何知識進行推導,這裡不做進一步解釋。
1.2.2最大間隔的優化模型
現在我們已經知道了如何去求資料點到超平面的距離,在超平面確定的情況下,我們就能夠找出所有支援向量,然後計算出間隔margin。每一個超平面都對應著一個margin,我們的目標就是找出所有margin中最大的那個值對應的超平面。因此用數學語言描述就是確定w、b使得margin最大。這是一個優化問題其目標函式可以寫成:
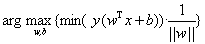
其中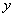
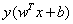
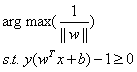
為了後面計算的方便,我們將目標函式等價替換為:
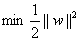
這是一個有約束條件的優化問題,通常我們可以用拉格朗日乘子法來求解。拉格朗日乘子法的介紹可以參考這篇部落格。應用拉格朗日乘子法如下:
令 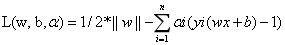
求L關於求偏導數得: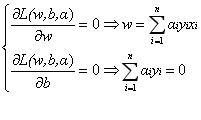
將(1.7)代入到(1.6)中化簡得:
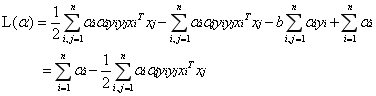
原問題的對偶問題為:
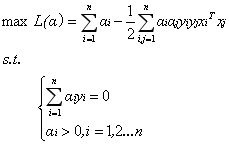
該對偶問題的KKT條件為
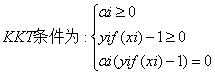
到此,似乎問題就能夠完美地解決了。但是這裡有個假設:資料必須是百分之百可分的。但是實際中的資料幾乎都不那麼“乾淨”,或多或少都會存在一些噪點。為此下面我們將引入了鬆弛變數來解決這種問題。
1.2.3鬆弛變數
由上一節的分析我們知道實際中很多樣本資料都不能夠用一個超平面把資料完全分開。如果資料集中存在噪點的話,那麼在求超平的時候就會出現很大問題。從圖三中課看出其中一個藍點偏差太大,如果把它作為支援向量的話所求出來的margin就會比不算入它時要小得多。更糟糕的情況是如果這個藍點落在了紅點之間那麼就找不出超平面了。
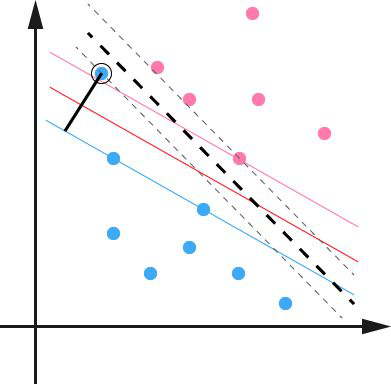
圖 3
因此引入一個鬆弛變數ξ來允許一些資料可以處於分隔面錯誤的一側。這時新的約束條件變為:
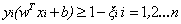
式中ξi的含義為允許第i個數據點允許偏離的間隔。如果讓ξ任意大的話,那麼任意的超平面都是符合條件的了。所以在原有目標的基礎之上,我們也儘可能的讓ξ的總量也儘可能地小。所以新的目標函式變為:
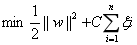
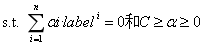
其中的C是用於控制“最大化間隔”和“保證大部分的點的函式間隔都小於1”這兩個目標的權重。將上述模型完整的寫下來就是:
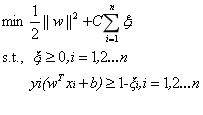
新的拉格朗日函式變為:
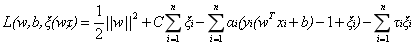
接下來將拉格朗日函式轉化為其對偶函式,首先對
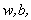
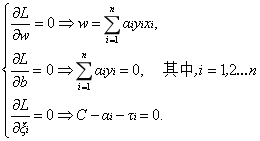
代入原式化簡之後得到和原來一樣的目標函式:
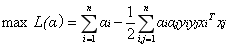
但是由於我們得到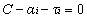
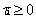
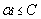
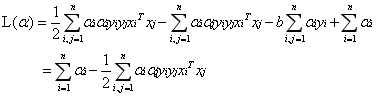
經過新增鬆弛變數的方法,我們現在能夠解決資料更加混亂的問題。通過修改引數C,我們可以得到不同的結果而C的大小到底取多少比較合適,需要根據實際問題進行調節。
1.2.4核函式
以上討論的都是線上性可分情況進行討論的,但是實際問題中給出的資料並不是都是線性可分的,比如有些資料可能是如圖4樣子。
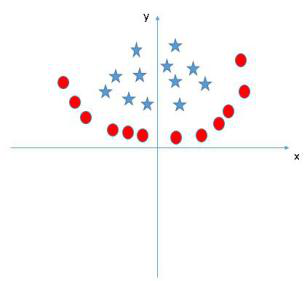
圖4
那麼這種非線性可分的資料是否就不能用svm演算法來求解呢?答案是否定的。事實上,對於低維平面內不可分的資料,放在一個高維空間中去就有可能變得可分。以二維平面的資料為例,我們可以通過找到一個對映將二維平面的點放到三維平面之中。理論上任意的資料樣本都能夠找到一個合適的對映使得這些在低維空間不能劃分的樣本到高維空間中之後能夠線性可分。我們再來看一下之前的目標函式:
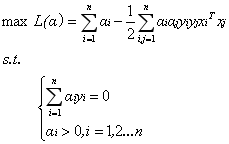
定義一個對映使得將所有對映到更高維空間之後等價於求解上述問題的對偶問題:
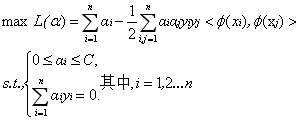
這樣對於線性不可分的問題就解決了,現在只需要找出一個合適的對映即可。當特徵變數非常多的時候在,高維空間中計算內積的運算量是非常龐大的。考慮到我們的目的並不是為找到這樣一個對映而是為了計算其在高維空間的內積,因此如果我們能夠找到計算高維空間下內積的公式,那麼就能夠避免這樣龐大的計算量,我們的問題也就解決了。實際上這就是我們要找的核函式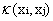
通過以上例子,我們可以很明顯地看到核函式是怎樣運作的。上述問題的對偶問題可以寫成如下形式:
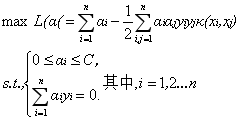
那麼怎樣的函式才可以作為核函式呢?下面的一個定理可以幫助我們判斷。
Mercer定理:任何半正定的函式都可以作為核函式。其中所謂半正定函式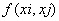
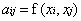
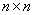
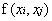
值得注意的是,上述定理中所給出的條件是充分條件而非充要條件。因為有些非正定函式也可以作為核函式。
下面是一些常用的核函式:
表1 常用核函式表
核函式名稱 | 核函式表示式 | 核函式名稱 | 核函式表示式 |
線性核 | 指數核 | ||
多項式核 | 拉普拉斯核 | ||
高斯核 | Sigmoid核 |

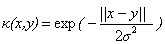
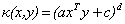
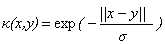
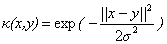
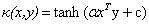
現在我們已經瞭解了一些支援向量機的理論基礎,我們通過對偶問題的的轉化將最開始求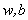
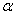
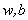
二、Smo演算法原理
2.1 約束條件
根據以上問題的分析,我們已經將原始問題轉化為了求的值,即求下面優化模型的解:
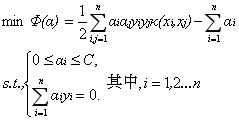
求解
Smo演算法的原理為:每次任意抽取兩個乘子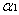
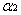

而原對偶問題的子問題的目標函式可以表達成:
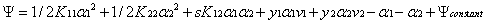
其中:
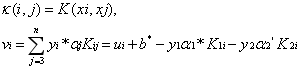
這裡之所以算兩個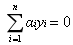
為了表述方便,定義一個特徵到輸出結果的輸出函式:
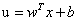
該對偶問題中KKT條件為:
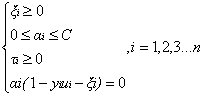
根據上述問題的KKT條件可以得出目標函式中的的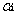
1、 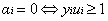
2、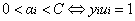
3、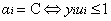
最優解需要滿足KKT條件,因此需要滿足以上的三個條件都滿足。而不滿足這三個條件的情況也有三種:
1、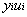
2、
3、
也就是說如果存在不滿足這些KKT條件的,我們就要更新它,這就是約束條件之一。其次,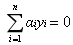
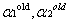
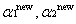

其中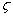
2.2引數優化
因為兩個因子不好同時求解,所以可先求第二個乘子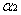
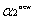
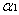
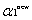
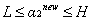
接下來,綜合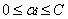

當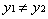
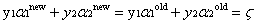
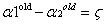
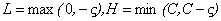
當
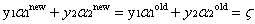
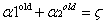
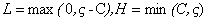
回顧第二個約束條件 :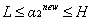
令其兩邊同時乘y1,可得:
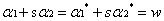
其中: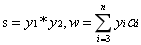
因此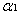
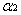
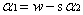
令 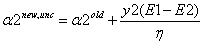
經過轉化之後可得:
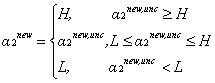
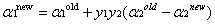
那麼如何來選擇乘子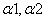
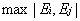
而b在滿足以下條件時需要更新:

且更新後的和如下:
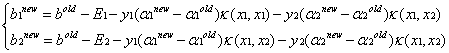
每次更新完兩個乘子之後,都需要重新計算b以及對應的E。最後更新完所有的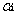
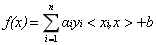
三、Svm的python實現與應用
第二節已經對Smo演算法進行了充分的說明並進行了推導,現在一切都準備好了。接下來需要做的就是實現這些演算法了,這裡我參考了《機器學習實戰》這本書中的程式碼,並利用該程式對一個問題進行了求解。由於程式碼數量過大,因此這裡就不再列出,而是放在附錄中。有興趣的朋友可以直接下載,也可以去官網下載原始碼。筆者在讀這些程式碼的過程中,也遇到了許多困難,大部分都根據自己的情況進行了註釋。
3.1問題描述
這裡我選取的一個數據集為聲吶資料集,該問題為需要根據聲吶從不同角度返回的聲音強度來預測被測物體是岩石還是礦井。資料集中共有208個數據,60個輸入變數和1個輸出變數。每個資料的前60個元素為不同方向返回的聲音強度,最後一個元素為本次用於聲吶測試的物體型別。其中標籤M表示礦井,標籤R為岩石。
3.2資料預處理
所給資料中沒有缺失值和異常值,因此不需要對資料集進行清洗。注意到所給資料集的標籤為字母型別,而svm演算法的標準標籤為“-1”和“1”的形式,所以需要對標籤進行轉化,用“-1”、“1”分別代替M和R。由於該資料集中所給標籤相同的資料都放在了一起,因此先對資料順序進行了打亂。程式碼如下:
def loadDataSet(fileName): dataMat=[];labelMat=[];data=[] fr=open(fileName) for line in fr.readlines(): line=line.replace(',','\t')#去除逗號 line=line.replace('M','-1')#對標籤進行替換 line=line.replace('R','1') lineArr=line.strip('\n').split('\t')#分割資料 data.append([float(lineArr[i]) for i in range(len(lineArr))]) random.shuffle(data) #隨機打亂列表 for i in range(len(data)): dataMat.append(data[i][0:len(data)-1]) labelMat.append(data[i][-1]) return dataMat,labelMat |
3.3模型訓練及測試
首先測試了一下將所有資料即作為訓練集又作為測試集,然後用Smo模型進行訓練找到所有的支援向量。最後根據訓練好的模型進行求解,最終測試的準確率平均為54%。如果把資料集分成測試集和訓練集,發現測試的準確率也在這附近。而根據網上資料統計該資料集測試的準確率最高為84%,一般情況下為百分之六十幾。資料集本身是造成測試準確率低的一個原因,但是另外一個更加重要的原因大概是引數的選擇問題。如何選取合適的引數是一個值得思考的問題,在接下來的學習過程中我也會注意一下引數選取這個問題。到這裡,關於svm的演算法就告一段落了。
#svm演算法的實現
from numpy import*
import random
from time import*
def loadDataSet(fileName):#輸出dataArr(m*n),labelArr(1*m)其中m為資料集的個數
dataMat=[];labelMat=[]
fr=open(fileName)
for line in fr.readlines():
lineArr=line.strip().split('\t')#去除製表符,將資料分開
dataMat.append([float(lineArr[0]),float(lineArr[1])])#陣列矩陣
labelMat.append(float(lineArr[2]))#標籤
return dataMat,labelMat
def selectJrand(i,m):#隨機找一個和i不同的j
j=i
while(j==i):
j=int(random.uniform(0,m))
return j
def clipAlpha(aj,H,L):#調整大於H或小於L的alpha的值
if aj>H:
aj=H
if aj<L:
aj=L
return aj
def smoSimple(dataMatIn,classLabels,C,toler,maxIter):
dataMatrix=mat(dataMatIn);labelMat=mat(classLabels).transpose()#轉置
b=0;m,n=shape(dataMatrix)#m為輸入資料的個數,n為輸入向量的維數
alpha=mat(zeros((m,1)))#初始化引數,確定m個alpha
iter=0#用於計算迭代次數
while (iter<maxIter):#當迭代次數小於最大迭代次數時(外迴圈)
alphaPairsChanged=0#初始化alpha的改變數為0
for i in range(m):#內迴圈
fXi=float(multiply(alpha,labelMat).T*\
(dataMatrix*dataMatrix[i,:].T))+b#計算f(xi)
Ei=fXi-float(labelMat[i])#計算f(xi)與標籤之間的誤差
if ((labelMat[i]*Ei<-toler)and(alpha[i]<C))or\
((labelMat[i]*Ei>toler)and(alpha[i]>0)):#如果可以進行優化
j=selectJrand(i,m)#隨機選擇一個j與i配對
fXj=float(multiply(alpha,labelMat).T*\
(dataMatrix*dataMatrix[j,:].T))+b#計算f(xj)
Ej=fXj-float(labelMat[j])#計算j的誤差
alphaIold=alpha[i].copy()#儲存原來的alpha(i)
alphaJold=alpha[j].copy()
if(labelMat[i]!=labelMat[j]):#保證alpha在0到c之間
L=max(0,alpha[j]-alpha[i])
H=min(C,C+alpha[j]-alpha[i])
else:
L=max(0,alpha[j]+alpha[i]-C)
H=min(C,alpha[j]+alpha[i])
if L==H:print('L=H');continue
eta=2*dataMatrix[i,:]*dataMatrix[j,:].T-\
dataMatrix[i,:]*dataMatrix[i,:].T-\
dataMatrix[j,:]*dataMatrix[j,:].T
if eta>=0:print('eta=0');continue
alpha[j]-=labelMat[j]*(Ei-Ej)/eta
alpha[j]=clipAlpha(alpha[j],H,L)#調整大於H或小於L的alpha
if (abs(alpha[j]-alphaJold)<0.0001):
print('j not move enough');continue
alpha[i]+=labelMat[j]*labelMat[i]*(alphaJold-alpha[j])
b1=b-Ei-labelMat[i]*(alpha[i]-alphaIold)*\
dataMatrix[i,:]*dataMatrix[i,:].T-\
labelMat[j]*(alpha[j]-alphaJold)*\
dataMatrix[i,:]*dataMatrix[j,:].T#設定b
b2=b-Ej-labelMat[i]*(alpha[i]-alphaIold)*\
dataMatrix[i,:]*dataMatrix[i,:].T-\
labelMat[j]*(alpha[j]-alphaJold)*\
dataMatrix[j,:]*dataMatrix[j,:].T
if (0<alpha[i])and(C>alpha[j]):b=b1
elif(0<alpha[j])and(C>alpha[j]):b=b2
else:b=(b1+b2)/2
alphaPairsChanged+=1
print('iter:%d i:%d,pairs changed%d'%(iter,i,alphaPairsChanged))
if (alphaPairsChanged==0):iter+=1
else:iter=0
print('iteraction number:%d'%iter)
return b,alpha
#定義徑向基函式
def kernelTrans(X, A, kTup):#定義核轉換函式(徑向基函式)
m,n = shape(X)
K = mat(zeros((m,1)))
if kTup[0]=='lin': K = X * A.T #線性核K為m*1的矩陣
elif kTup[0]=='rbf':
for j in range(m):
deltaRow = X[j,:] - A
K[j] = deltaRow*deltaRow.T
K = exp(K/(-1*kTup[1]**2)) #divide in NumPy is element-wise not matrix like Matlab
else: raise NameError('Houston We Have a Problem -- \
That Kernel is not recognized')
return K
class optStruct:
def __init__(self,dataMatIn, classLabels, C, toler, kTup): # Initialize the structure with the parameters
self.X = dataMatIn
self.labelMat = classLabels
self.C = C
self.tol = toler
self.m = shape(dataMatIn)[0]
self.alphas = mat(zeros((self.m,1)))
self.b = 0
self.eCache = mat(zeros((self.m,2))) #first column is valid flag
self.K = mat(zeros((self.m,self.m)))
for i in range(self.m):
self.K[:,i] = kernelTrans(self.X, self.X[i,:], kTup)
def calcEk(oS, k):
fXk = float(multiply(oS.alphas,oS.labelMat).T*oS.K[:,k] + oS.b)
Ek = fXk - float(oS.labelMat[k])
return Ek
def selectJ(i, oS, Ei):
maxK = -1; maxDeltaE = 0; Ej = 0
oS.eCache[i] = [1,Ei]
validEcacheList = nonzero(oS.eCache[:,0].A)[0]
if (len(validEcacheList)) > 1:
for k in validEcacheList: #loop through valid Ecache values and find the one that maximizes delta E
if k == i: continue #don't calc for i, waste of time
Ek = calcEk(oS, k)
deltaE = abs(Ei - Ek)
if (deltaE > maxDeltaE):
maxK = k; maxDeltaE = deltaE; Ej = Ek
return maxK, Ej
else: #in this case (first time around) we don't have any valid eCache values
j = selectJrand(i, oS.m)
Ej = calcEk(oS, j)
return j, Ej
def updateEk(oS, k):#after any alpha has changed update the new value in the cache
Ek = calcEk(oS, k)
oS.eCache[k] = [1,Ek]
def innerL(i, oS):
Ei = calcEk(oS, i)
if ((oS.labelMat[i]*Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i]*Ei > oS.tol) and (oS.alphas[i] > 0)):
j,Ej = selectJ(i, oS, Ei) #this has been changed from selectJrand
alphaIold = oS.alphas[i].copy(); alphaJold = oS.alphas[j].copy()
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L==H: print("L==H"); return 0
eta = 2.0 * oS.K[i,j] - oS.K[i,i] - oS.K[j,j] #changed for kernel
if eta >= 0: print("eta>=0"); return 0
oS.alphas[j] -= oS.labelMat[j]*(Ei - Ej)/eta
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)
updateEk(oS, j) #added this for the Ecache
if (abs(oS.alphas[j] - alphaJold) < 0.00001): print("j not moving enough"); return 0
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])#update i by the same amount as j
updateEk(oS, i) #added this for the Ecache #the update is in the oppostie direction
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,i] - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[i,j]
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,j]- oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[j,j]
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]): oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]): oS.b = b2
else: oS.b = (b1 + b2)/2.0
return 1
else: return 0
#smoP函式用於計算超平的alpha,b
def smoP(dataMatIn, classLabels, C, toler, maxIter,kTup=('lin', 0)): #完整的Platter SMO
oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler, kTup)
iter = 0#計算迴圈的次數
entireSet = True; alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
if entireSet: #go over all
for i in range(oS.m):
alphaPairsChanged += innerL(i,oS)
print("fullSet, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged))
iter += 1
else:#go over non-bound (railed) alphas
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i,oS)
print("non-bound, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged))
iter += 1
if entireSet: entireSet = False #toggle entire set loop
elif (alphaPairsChanged == 0): entireSet = True
print("iteration number: %d" % iter)
return oS.b,oS.alphas
#calcWs用於計算權重值w
def calcWs(alphas,dataArr,classLabels):#計算權重W
X = mat(dataArr); labelMat = mat(classLabels).transpose()
m,n = shape(X)
w = zeros((n,1))
for i in range(m):
w += multiply(alphas[i]*labelMat[i],X[i,:].T)
return w
#值得注意的是測試準確與k1和C的取值有關。
def testRbf(k1=1.3):#給定輸入引數K1
#測試訓練集上的準確率
d