
SSD配置、訓練、測試以及應用到自己的資料集
git clone https://github.com/weiliu89/caffe.git
git
checkout ssd
make
all
如果報錯:
/usr/include/boost/property_tree/detail/json_parser_read.hpp:257:264: error: ‘type name’ declared as function returning an array
make: *** [.build_release/cuda/src/caffe/layers/detection_output_layer.o] Error 1
make
pycaffe
下載VOC2007和VOC2012資料集,放到caffe/data/目錄下 下載資料集 wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar 解壓資料集 tar -xvf VOCtrainval_11-May-
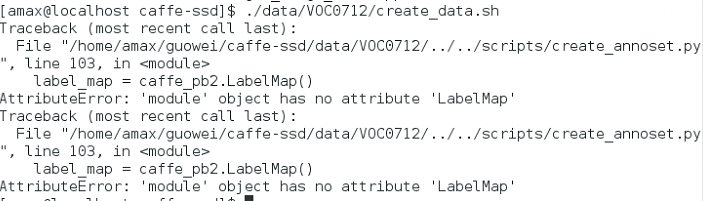
ssd/python:/home/amax/anaconda/include/python2.7 開始訓練: python examples/ssd/ssd_pascal.py 報錯:importerror:no module named model_libs 需要重新生成LMDB檔案 ./data/VOC0712/create_list.sh ./data/VOC0712/create_data.sh
然後重新訓練: python examples/ssd/ssd_pascal.py
圖片資料集上測試: python examples/ssd/score_ssd_pascal.py 利用caffe/examples/ssd_detect.ipynb檔案可以用單張圖片測試檢測效果(注意檔案內載入檔案的路徑,如果報錯修改為絕對路徑) 訓練自己的資料集
準備自己的資料集(VOC2007格式),這裡我的資料集叫做VOC1000 複製VOC0712資料夾,重新命名為VOC1000 修改create_list.sh #root_dir=$HOME/guowei/caffe-ssd/data/VOCdevkit/ for name in VOC1000 修改create_data.sh data_root_dir="$HOME/guowei/caffe-ssd/data/VOCdevkit" dataset_name="VOC1000" 修改labelmap_voc.prototxt(我的類別只有飛機,所以為背景和飛機) item { name: "none_of_the_above" label: 0 display_name: "background" } item { name: "aeroplane" label: 1 display_name: "aeroplane" } 生成資料 ./data/VOC1000/create_list.sh ./data/VOC1000/create_data.sh
開始訓練自己的資料 複製ssd_pascal.py,重新命名為ssd_pascal1000.py train_data = "examples/VOC1000/VOC1000_trainval_lmdb" test_data = "examples/VOC1000/VOC1000_test_lmdb" num_test_image換成自己資料集中測試圖片的數目 num_classes換成自己的類別數目+1,我的是2 VOC0712都換成VOC1000 執行訓練 python examples/ssd/ssd_pascal1000.py 結果如下圖:
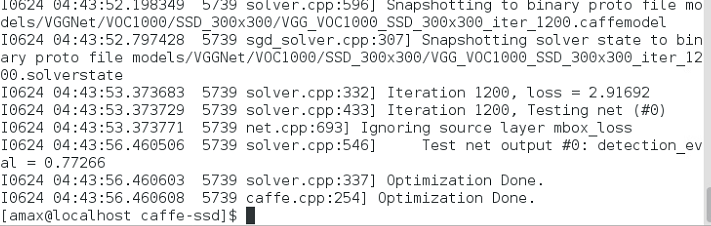
測試精度為77.2%,迭代1200次,基於VGGNet.
相關推薦
SSD配置、訓練、測試以及應用到自己的資料集
git clone https://github.com/weiliu89/caffe.git git checkout ssd make all 如果報錯: /usr/include/boost/property_tree/detail/json_parser_r
Caffe SSD編譯、訓練及測試
SSD採用VGG16作為基礎模型,然後在VGG16的基礎上新增了卷積層來獲得更多的特徵以用於檢測。SSD的網路結構如上圖所示(上面是SSD模型,下面是Yolo模型),可以明顯看到SSD利用了多尺度的特徵圖做檢測。 安裝 clone程式碼(假設程式碼clone到$CAFF
caffe-SSD 安裝、訓練、SSD測試(ubuntu18.04+cuda9.0+openvc3.4)
安裝及MNIST模型測試、matlab caffe介面測試 https://blog.csdn.net/qq_35608277/article/details/84938244 自己看程式碼提供者的最直接,大家都是根據他的copy的: https://github.com/weili
SSD 安裝、訓練、測試(ubuntu14.04+cuda7.5+openvc2.4.9)
安裝步驟 1.安裝git,下載SSD原始碼包 sudo apt-get install git git clone https://github.com/weiliu89/caffe.git cd caffe git checkout ssd 以下幾條命令是驗證相應的包是
caffe-ssd編譯、訓練、測試全過程(最後有彩蛋)
大家好,終於把SSD整通了,現在我把整個過程搭建給你們講講。 caffe_ssd多目標檢查效果還是非常好的,線上測試,FPS在20左右。我的訓練的還是官方的資料集,其實我們可通過做自己的資料集得到預測模型也是可以的。 一、SSD編譯 https://github.com
DL之RNN:人工智慧為你寫歌詞(林夕寫給陳奕迅)——基於TF利用RNN演算法實現【機器為你作詞】、訓練&測試過程全記錄
DL之RNN:人工智慧為你寫歌詞(林夕寫給陳奕迅)——基於TF利用RNN演算法實現【機器為你作詞】、訓練&測試過程全記錄 輸出結果 1、test01 你的揹包 一個人過我 誰不屬了 不甘心 不能回頭 我的揹包載管這個 誰讓我們是要不可 但求跟你過一生 你把我灌醉 即使嘴角
DL之RNN:人工智慧為你寫周董歌詞——基於TF利用RNN演算法實現【機器為你作詞】、訓練&測試過程全記錄
DL之RNN:人工智慧為你寫周董歌詞——基於TF利用RNN演算法實現~機器為你作詞~、訓練&測試過程全記錄 輸出結果 1、test01 夕海 而我在等待之光 在月前被畫面 而我心碎 你的個世紀 你的時間 我在趕過去 我的不是你不會感覺媽媽 我說不要不要說 我會愛你 我不要你不
pytorch: 準備、訓練和測試自己的圖片資料
大部分的pytorch入門教程,都是使用torchvision裡面的資料進行訓練和測試。如果我們是自己的圖片資料,又該怎麼做呢? 一、我的資料 我在學習的時候,使用的是fashion-mnist。這個資料比較小,我的電腦沒有GPU,還能吃得消。關於fashion-mnist資料,可以百度,也可以 點此 瞭解
Faster rcnn 安裝、訓練、測試、除錯
先上個檢測效果: (1)圖片人臉檢測+關鍵點 (2)攝像頭實時人臉+關鍵點 **********************************************************
藍綠部署、A/B測試以及灰度釋出
轉自:https://blog.csdn.net/zyqduron/article/details/59507525過去的10年裡,很多大公司都在使用藍綠部署,安全、可靠是這種部署方式的特點。藍綠部署雖然算不上”Sliver Bullet“,但確實很實用。在有關於“微服務”、
分類器之正負樣本收集、訓練、測試
分類器學習所需檔案如下: opencv工具 opencv_createsample.exe opencv_traincascade.exe 資料準備 1、pos資料夾 (正樣本) 2、neg資料夾 (負樣本
FCN製作自己的資料集、訓練和測試 caffe
花了兩三週的時間,在導師的催促下,把FCN的全部流程走了一遍,期間走了很多彎路,現在記錄一下。系統環境:ubuntu 16.04LTS 一、資料集的製作 注:我的資料集是仿照VOC資料集進行製作的 1.resize 資料集 我的GPU視訊記憶體4G,跑過大的圖片帶不動,需要resize圖片大小,放幾
SSD配置和訓練以及遇到的坑
SSD配置1、clone作者github下的caffe檔案包git clone https://github.com/weiliu89/caffe.git cd caffe git checkout ssd(出現“分支”則說明copy-check成功...作者caffe目錄下
學習筆記TF016:CNN實現、數據集、TFRecord、加載圖像、模型、訓練、調試
quest oba lose 神經元 byte 足夠 jpg eight 值轉換 AlexNet(Alex Krizhevsky,ILSVRC2012冠軍)適合做圖像分類。層自左向右、自上向下讀取,關聯層分為一組,高度、寬度減小,深度增加。深度增加減少網絡計算量。 訓練模
大陸居民身份證、港澳臺居民居住證驗證工具 Python 版 :驗證、獲取基本資訊以及生成假資料
中華人民共和國居民身份證、中華人民共和國港澳居民居住證以及中華人民共和國臺灣居民居住證號碼驗證工具(Python 版)支援 15 位與 18 位號碼。 PHP 版本 安裝 pip install id-validator 使用 440308199901101512 和 610104620927690
FCN訓練自己資料集(person-segmentation)、SIFT-FLOW、SBD和VOC實驗總結
最近花了將近一週的時間,基於提供的原始碼,通過參考網上的部落格,跑通了FCN在三個資料集上的訓練以及測試。在這裡寫下總結,即是記錄,又希望能夠對其他剛剛接觸FCN的人有所幫助。 FCN的原始碼地址:https://github.com/shelhamer/fcn.berkeleyvision.o
基於HtmlUnit實現簡單登入、頁面跳轉以及獲取有用資料部分程式碼示例(示例網站:大潤發)
首先,我們將要獲取的目標內容為商戶訂單查詢結果: 如下程式碼為登入模組程式碼(由於驗證碼解析這部分目前沒做,只能手動識別): /** * * @param username 使用者 * @param password
為豬臉識別而進行自己資料集的構建、訓練
在實際過程中走了彎路,特地進行說明記錄,以備今後參考。 思路是先構建VOC2007格式的豬臉資料集,在轉換成tf格式,然後利用tf的objectdetectionapi進行訓練。原因是把2種構
Fast RCNN 訓練自己資料集 (1編譯配置)
FastRCNN 訓練自己資料集 (1編譯配置) FastRCNN是Ross Girshick在RCNN的基礎上增加了Multi task training整個的訓練過程和測試過程比RCNN快了許多。別的一些細節不展開,過幾天會上傳Fast RCNN的論文筆記。FastRCNN mAP效能上略有上升。Fa
FastRCNN 訓練自己資料集(一)——編譯配置
FastRCNN是Ross Girshick在RCNN的基礎上增加了Multi task training整個的訓練過程和測試過程比RCNN快了許多。別的一些細節不展開,過幾天會上傳Fast RCNN的論文筆記。FastRCNN mAP效能上略有上升。Fast RCNN中,提取OP的過程和訓練過程仍