
機器學習sklearn19.0聚類演算法——層次聚類(AGNES/DIANA)、密度聚類(DBSCAN/MDCA)、譜聚類
一、層次聚類


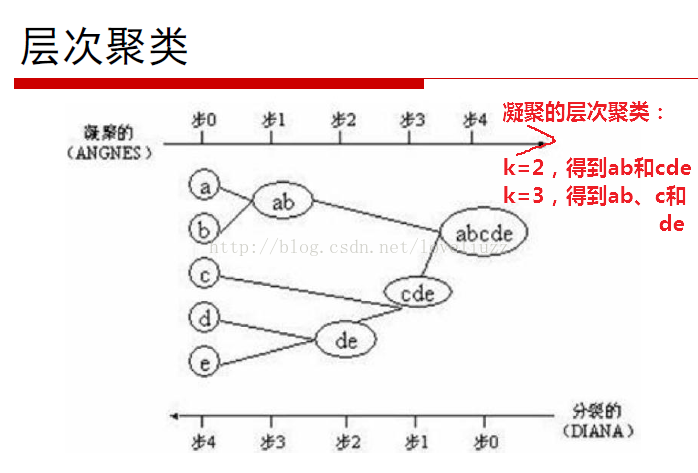




BIRCH演算法詳細介紹以及sklearn中的應用如下面部落格連結:
http://www.cnblogs.com/pinard/p/6179132.html
http://www.cnblogs.com/pinard/p/6200579.html
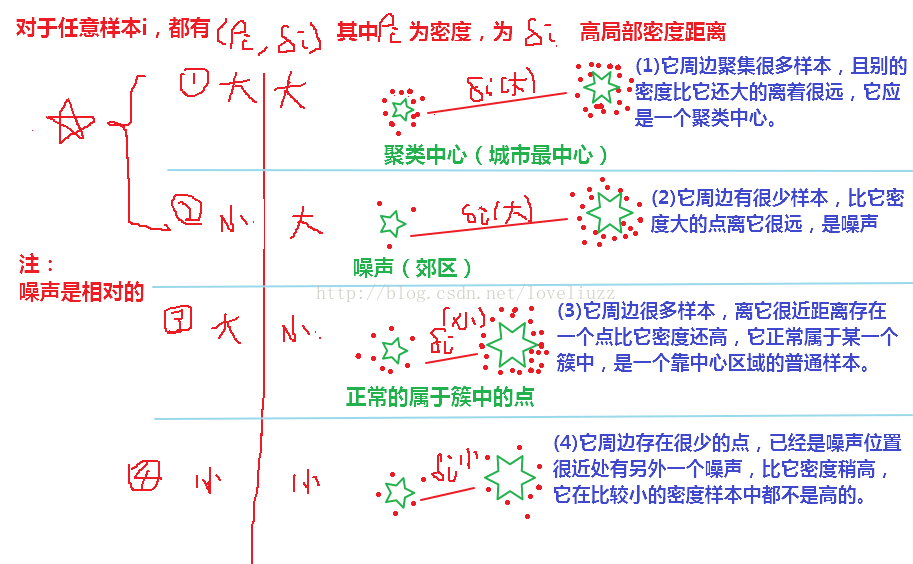
二、密度聚類





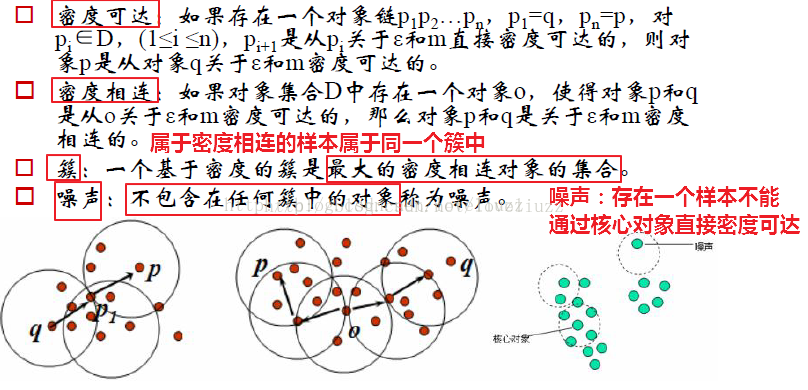

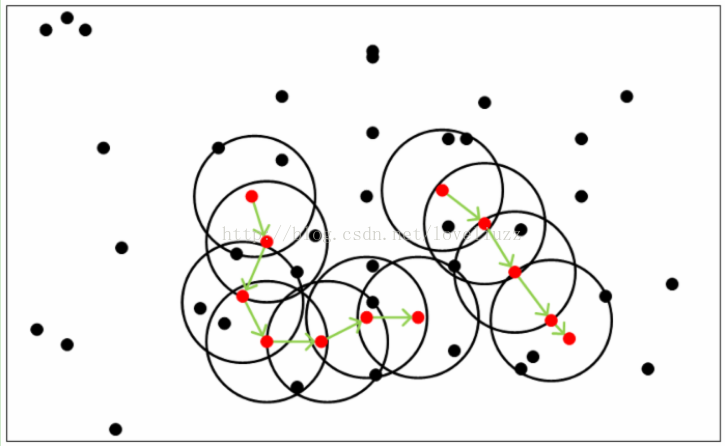


三、密度最大值聚類



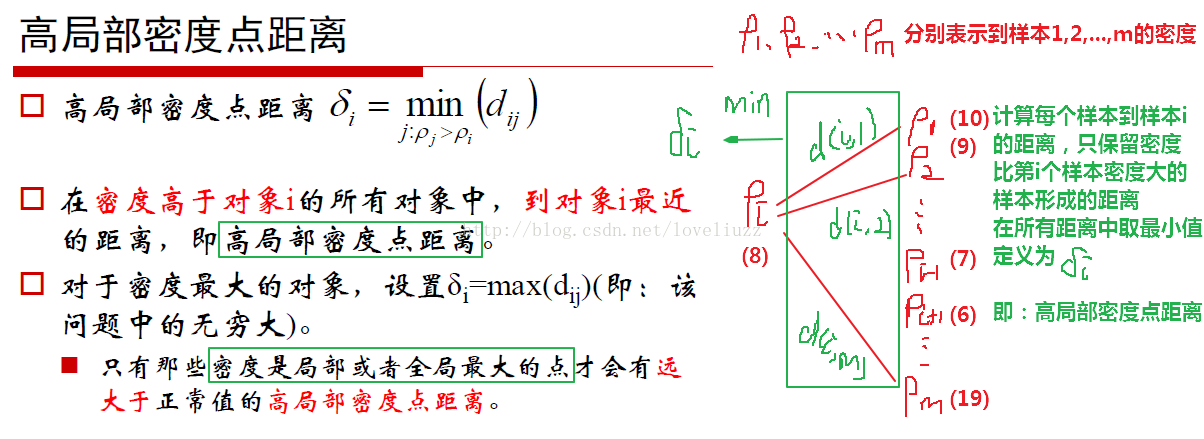




四、譜聚類



相關推薦
機器學習sklearn19.0——線性迴歸演算法(應用案例)
一、sklearn中的線性迴歸的使用 二、線性迴歸——家庭用電預測 (1)時間與功率之間的關係 #!/usr/bin/env python # -*- coding:utf-8 -*- # Author:ZhengzhengLiu #線性迴歸——家庭用電預
機器學習sklearn19.0——Logistic迴歸演算法
一、Logistic迴歸的認知與應用場景 Logistic迴歸為概率型非線性迴歸模型,是研究二分類觀察結果與一些影響因素之間關係的 一種多變量分析方法。通常的問題是,研究某些因素條件下某個結果是否發生,比如醫學中根據病人的一些症狀 來判斷它是否患有某種病。 二
機器學習sklearn19.0聚類演算法——層次聚類(AGNES/DIANA)、密度聚類(DBSCAN/MDCA)、譜聚類
一、層次聚類 BIRCH演算法詳細介紹以及sklearn中的應用如下面部落格連結: http://www.cnblogs.com/pinard/p/6179132.html http://www.cnblogs.com/pinard/p/62
機器學習sklearn19.0聚類演算法——Kmeans演算法
一、關於聚類及相似度、距離的知識點 二、k-means演算法思想與流程 三、sklearn中對於kmeans演算法的引數 四、程式碼示例以及應用的知識點簡介 (1)make_blobs:聚類資料生成器 sklearn.datasets.m
機器學習sklearn19.0——整合學習——boosting與梯度提升演算法(GBDT)、Adaboost演算法
一、boosting演算法原理 二、梯度提升演算法 關於提升梯度演算法的詳細介紹,參照部落格:http://www.cnblogs.com/pinard/p/6140514.html 對該演算法的sklearn的類庫介紹和調參,參照網址:http://
【機器學習】利用蟻群演算法求解旅行商(TSP)問題
如果喜歡這裡的內容,你能夠給我最大的幫助就是轉發,告訴你的朋友,鼓勵他們一起來學習。 If you like the content here, you can give me the greatest help is forwarding, tell you
AP聚類演算法使用詳解(scikit-learn)
Affinity Propagation Clustering(簡稱AP演算法)是2007提出的,當時發表在Science上《single-exemplar-based》。特別適合高維、多類資料快速聚類,相比傳統的聚類演算法,從聚類效能和效率方面都有大幅度的提升。
《機器學習實戰》高清版pdf免費下載(資源分享)
《機器學習實戰》高清版pdf免費下載 《機器學習實戰》高清版pdf免費下載 下載地址:網盤下載 編輯推薦 介紹並實現機器學習的主流演算法 面向日常任務的高效實戰內容 《機器學習實戰》沒有從理論角度來揭示機器學習演算法背後的數學原理,而是通過“原理簡述+問題例項+實際程式碼+執行
機器學習防止過擬合之L1範數(正則)與LASSO
機器學習過擬合問題 對於機器學習問題,我們最常遇到的一個問題便是過擬合。在對已知的資料集合進行學習的時候,我們選擇適應度最好的模型最為最終的結果。雖然我們選擇的模型能夠很好的解釋訓練資料集合,但卻不一定能夠很好的解釋測試資料或者其他資料,也就是說這個模型過於精
斯坦福:機器學習CS229:Exercise 1: Linear Regression線性迴歸(答案1)
先貼程式碼,有空再根據講義,逐條講解 謝謝黃博的資料! %% Machine Learning Online Class - Exercise 1: Linear Regression % Instructions % ------------ %
林軒田--機器學習技法--SVM筆記2--對偶支援向量機(dual+SVM)
對偶支援向量機 咦?怎麼還有關於支援向量機的內容,我們不是在上一講已經將支援向量機解決了麼?怎麼又引入了對偶這個概念? 1.動機 我們在上一講已經講過,可以使用二次規劃來解決支援向量機的問題。如果現在想要解決非線性的支援向量機的問題,也很簡單,如下圖所
《機器學習實戰》二分-kMeans演算法(二分K均值聚類)
首先二分-K均值是為了解決k-均值的使用者自定義輸入簇值k所延伸出來的自己判斷k數目,其基本思路是: 為了得到k個簇,將所有點的集合分裂成兩個簇,從這些簇中選取一個繼續分裂,如此下去,直到產生k個簇。 虛擬碼: 初始化簇表,使之包含由所有的點組成的簇。 repeat &n
王小草【機器學習】筆記--無監督演算法之聚類
標籤(空格分隔): 王小草機器學習筆記 1. 聚類的概述 存在大量未標註的資料集,即只有特徵,沒有標籤的資料。 根據這些特徵資料計算樣本點之間的相似性。 根據相似性將資料劃分到多個類別中。 使得,同一個類別內的資料相似度大,類別之間的資料相似度小。
聚類演算法---層次聚類
假設有N個待聚類的樣本,對於層次聚類來說,步驟: 1.(初始化)把每個樣本歸為一類,計算每兩個類之間的距離,也就是樣本與樣本之間的相似度; 2.尋找各個類之間最近的兩個類,把他們歸為一類(這樣類的總數就少了一個); 3.重新計算新生成的這個類和各個舊類之間的相似度; 4.重複2和3直到所
從 0 開始機器學習 - 神經網路反向 BP 演算法!
最近一個月專案好忙,終於擠出時間把這篇 BP 演算法基本思想寫完了,公式的推導放到下一篇講吧。 ## 一、神經網路的代價函式 神經網路可以看做是複雜邏輯迴歸的組合,因此與其類似,我們訓練神經網路也要定義代價函式,之後再使用梯度下降法來最小化代價函式,以此來訓練最優的權重矩陣。 ### 1.1 從邏輯迴歸
基於機器學習的可擴充套件HCGraph演算法
HCGraph 是Leviatom網路的核心演算法。在前面的文章中, 我們介紹過該演算法利用Gossip 協議族構建全網信任模型。HCGraph利用類似於HashGraph的Gossip以及Gossip about Gossip協議來實現高效的信任關係傳遞。利用該協議,我們可以在獲得一個比
機器學習的分類與主要演算法對比
重要引用:Andrew Ng Courera Machine Learning;從機器學習談起;關於機器學習的討論;機器學習常見演算法分類彙總;LeNet Homepage;pluskid svm 首先讓我們瞻仰一下當今機器學習領域的執牛耳者: 這幅圖上的三人是當今機器學習界的
機器學習實戰——利用AdaBoost元演算法提高分類效能 實現記錄
問題:TypeError: __new__() takes from 2 to 4 positional arguments but 6 were given def loadSimpData(): datMat = matrix([1. ,2.1],
python實現西瓜書《機器學習》習題5.5BP演算法
慣例,首先對原始碼致以崇高的感謝和敬意:https://blog.csdn.net/Snoopy_Yuan/article/details/70230862 學習神經網路,pybrain是個好東東,上鍊接http://pybrain.org/docs/index.html#installat
機器學習——樸素貝葉斯演算法
概率定義為一件事情發生的可能性 概率分為聯合概率和條件概率 聯合概率:包含多個條件,且所有條件同時成立的概率 記作:P(A,B) P(A,B)=P(A)P(B) 條件概率:就是事件A在另外一個事件B已經發生的條件概率 記作:P(A|B)